
AWS MAP (Migration Acceleration Program): Hướng Dẫn Chi Tiết Từng Phase Cho Doanh Nghiệp - Part 2
Tiếp nối phần 1, chúng ta sẽ đến
Phase 3: Migrate — Di chuyển
Phase Migrate là giai đoạn thực thi thực sự — nơi workload được di chuyển từ on-prem lên AWS theo từng wave có kiểm soát. Đây là lúc mọi nền tảng đã xây dựng ở Mobilize được kiểm chứng.
Note: Wave Planning là kỹ thuật chia toàn bộ danh sách workload/server cần migrate thành các nhóm nhỏ (waves) và thực hiện migrate từng wave theo thứ tự ưu tiên.
💡 Thay vì migrate tất cả cùng lúc (rủi ro cao) → chia nhỏ, migrate tuần tự, kiểm soát được rủi ro.
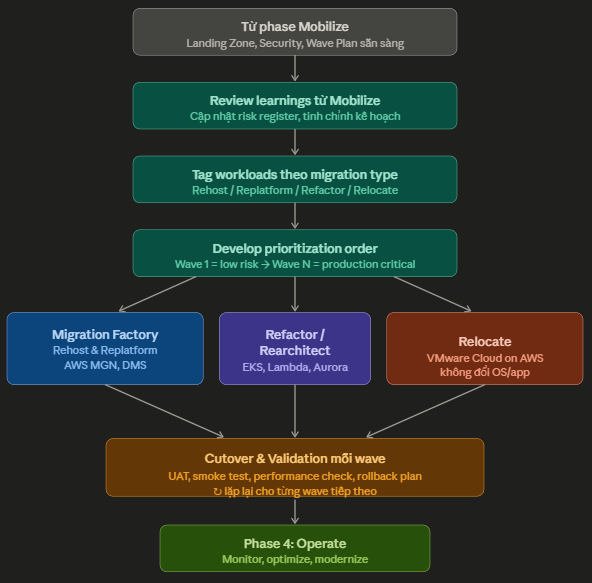
Bước 1 — Review learnings từ Mobilize
Trước khi di chuyển application đầu tiên, team cần ngồi lại rà soát toàn bộ những gì đã xây dựng trong Mobilize để đảm bảo không có gap nào bị bỏ sót.
Các nội dung cần review: Risk Register có được cập nhật đầy đủ chưa, có phát sinh risk mới nào trong quá trình build Landing Zone không, wave plan có cần điều chỉnh dựa trên những phát hiện mới không, runbook cho wave 1 đã đủ chi tiết chưa. Đây cũng là thời điểm confirm lại với business stakeholders về cutover windows — thường tránh tháng cao điểm (end-of-year, quarter close, campaign lớn).
Bước 2 — Tag workloads theo migration type
Dựa vào kết quả Portfolio Assessment từ Mobilize, mỗi workload được gán nhãn chính xác theo strategy sẽ áp dụng. Việc tagging này không chỉ là metadata — nó quyết định tool nào được dùng và team nào phụ trách:
- Rehost → Migration Factory team dùng AWS MGN
- Replatform → Migration Factory team với thêm bước convert (OS upgrade, DB managed)
- Refactor/Rearchitect → Engineering team, timeline dài hơn nhiều
- Relocate → VMware team dùng VMware Cloud on AWS
- Retire → Infrastructure team lên lịch decommission
- Retain → Không làm gì, document lý do retain để review định kỳ
Chi tiết về 7Rs là gì? Mình có bài viết insights tại đây: Giải thích chi tiết về 7R - Chiến lược dịch chuyển Cloud và bài toán tăng trưởng bền vững cho doanh nghiệp (High level)
Bước 3 — Develop prioritization order
Thứ tự wave là cân bằng giữa rủi ro và tốc độ. Nguyên tắc chung:
Wave đầu tiên luôn phải là workload ít rủi ro nhất để team làm quen quy trình: dev/test environment, internal tools không có SLA, sandbox applications. Mục tiêu là học và hoàn thiện runbook trước khi đụng vào production.
Các wave giữa dần tăng độ phức tạp: staging environments, internal production apps có SLA thấp, apps có ít dependency. Mỗi wave thường gồm 20–50 server tùy quy mô team.
Wave cuối cùng là production critical và apps có nhiều dependency phức tạp — thường được thực hiện sau khi đội đã chạy thành thục 3–5 wave trước.
Tiêu chí xếp thứ tự ưu tiên gồm: mức độ rủi ro kỹ thuật, số dependency với hệ thống khác, impact đến business nếu downtime, deadline hợp đồng datacenter, và mức độ sẵn sàng của application owner.
Bước 4A — Migration Factory: Rehost & Replatform
Đây là engine chính của phase Migrate, được thiết kế để xử lý khối lượng lớn workload theo dây chuyền lặp lại.
AWS Application Migration Service (MGN) — công cụ Rehost chủ lực
MGN là công cụ chính thức của AWS cho lift-and-shift, thay thế Server Migration Service (SMS) cũ. Quy trình hoạt động:
Cài MGN Replication Agent trên server nguồn → Agent liên tục replicate block-level data lên AWS Replication Server trong staging subnet → Khi sẵn sàng cutover, launch test instance để validate → Cutover chính thức: stop server nguồn, finalize replication, launch production instance → Sau khi confirm ổn định, disconnect agent và archive server nguồn.
Điểm mạnh của MGN là replication liên tục — RPO (Recovery Point Objective) gần như bằng 0 tại thời điểm cutover, thay vì phải schedule migration window dài như các tool cũ. Cutover window thực tế thường chỉ 15–30 phút.
AWS Database Migration Service (DMS) — cho database
DMS xử lý migration database với tính năng Change Data Capture (CDC) — cho phép database nguồn tiếp tục nhận write trong quá trình migration, DMS sync liên tục, và chỉ cần dừng ứng dụng trong vài phút để cutover. DMS hỗ trợ homogeneous migration (Oracle → Oracle RDS) và heterogeneous (Oracle → Aurora PostgreSQL, SQL Server → Aurora MySQL).
Với heterogeneous migration, cần thêm bước dùng AWS Schema Conversion Tool (SCT) để convert schema và stored procedures trước khi chạy DMS.
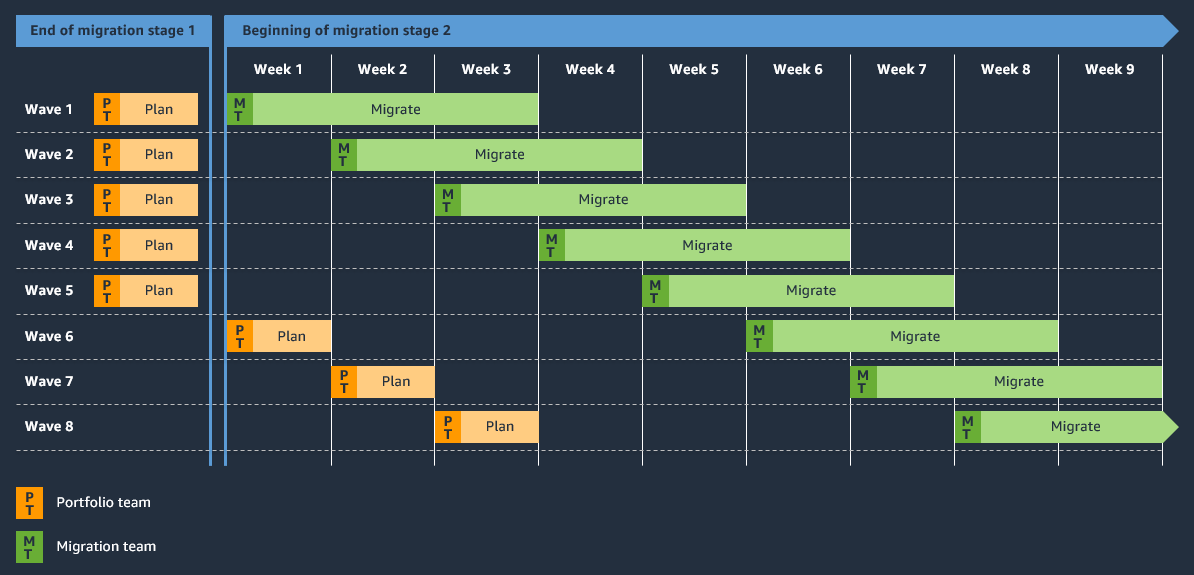
Quy trình Migration Factory chuẩn (mỗi wave)
Mỗi wave đi qua 5 giai đoạn nhỏ: Discover & Plan (confirm inventory, dependencies, cutover window) → Mobilize (cài agent, bắt đầu replicate, cấu hình target) → Migrate (test launch, validate, fix issues) → Cutover (production cutover, DNS update, decommission source) → Operate (handoff sang Operate team, monitor 30 ngày).
Bước 4B — Complex Refactor & Rearchitect
Đây là các workload cần thay đổi kiến trúc đáng kể — không thể lift-and-shift mà vẫn đạt yêu cầu về performance, scale, hoặc cost. Timeline dài hơn nhiều (3–12 tháng mỗi app) nên thường chạy song song với Migration Factory thay vì theo wave.
Containerization là hướng phổ biến nhất: đóng gói ứng dụng thành container, chạy trên EKS (Kubernetes managed) hoặc ECS (simpler, AWS-native). AWS cung cấp App2Container tool để tự động phân tích Java và .NET app đang chạy trên Windows/Linux và generate CloudFormation/ECS task definition. Không phải magic nhưng tiết kiệm đáng kể công đầu.
Serverless cho các workload event-driven hoặc API-heavy: Lambda cho business logic, API Gateway cho REST/GraphQL endpoints, DynamoDB cho session state và flexible schema, Step Functions cho workflow orchestration. Chi phí giảm mạnh vì chỉ trả tiền khi có request.
Database modernization là bài toán phức tạp nhất: Oracle → Aurora PostgreSQL (dùng SCT + DMS), SQL Server → Aurora MySQL, hoặc NoSQL migration (MongoDB → DynamoDB). Thường cần chạy dual-write trong giai đoạn chuyển tiếp để đảm bảo data consistency.
Bước 4C — Relocate: VMware Cloud on AWS
Dành cho tổ chức đang dùng VMware vSphere on-prem và muốn di chuyển nhanh mà không phải thay đổi gì ở tầng OS hay application. VMware Cloud on AWS (VMC) chạy VMware SDDC (vSphere, vSAN, NSX) trực tiếp trên bare-metal AWS hardware.
VM được di chuyển bằng VMware HCX — công cụ migration của VMware — với downtime gần bằng 0 nhờ live migration (vMotion qua WAN). Sau khi migrate, admin vẫn dùng vCenter quen thuộc để quản lý, network policy giữ nguyên. Đây là con đường "ít đau" nhất cho VMware-heavy environments.
Trade-off: chi phí cao hơn native EC2 vì phải trả thêm license VMware. Thường được dùng làm bước chuyển tiếp (2–3 năm) trước khi refactor sang EC2/EKS native.
Bước 5 — Cutover & Validation mỗi wave
Đây là thời điểm căng thẳng nhất của mỗi wave. Quy trình cutover chuẩn:
- T-2 tuần: Freeze code changes trên hệ thống liên quan, chạy dry-run cutover trên môi trường test, confirm rollback procedure với tất cả bên liên quan.
- T-2 ngày: Final sync data, validate performance của target environment dưới load test, brief toàn bộ team về cutover plan và liên lạc khẩn cấp.
- Cutover window (thường cuối tuần đêm thứ 6 hoặc rạng sáng thứ 7): Stop application ở source, finalize replication (MGN), launch production instance ở AWS, update DNS records (giảm TTL trước 24h), run smoke tests, chạy UAT nhanh với business user.
- Go/No-go decision point: Nếu smoke test pass và business confirm OK → Go, announce thành công, monitor chặt 24h đầu. Nếu có vấn đề → trigger rollback plan, revert DNS, restart source system, post-mortem trong 48h.
- 30-day hypercare period sau mỗi wave: team migration monitor chặt metrics (CPU, memory, latency, error rate), ưu tiên fix mọi issue phát sinh trước khi handoff chính thức sang Operate team.
Thời gian thực tế của phase Migrate phụ thuộc hoàn toàn vào số lượng và độ phức tạp workload. Một Migration Factory tốt có thể xử lý 20–50 server/tuần với team 6–8 người. Với 500 server, timeline sẽ vào khoảng 3–6 tháng. Refactor/Rearchitect chạy song song và thường mất thêm 6–18 tháng cho các app phức tạp.
Phase 4: Operate — Vận hành
Phase Operate là giai đoạn sau khi migration hoàn thành — nơi tổ chức chuyển từ tư duy "di chuyển" sang tư duy "vận hành và tối ưu bền vững" trên AWS. Đây không phải điểm kết thúc mà là điểm bắt đầu của hành trình cloud dài hạn.
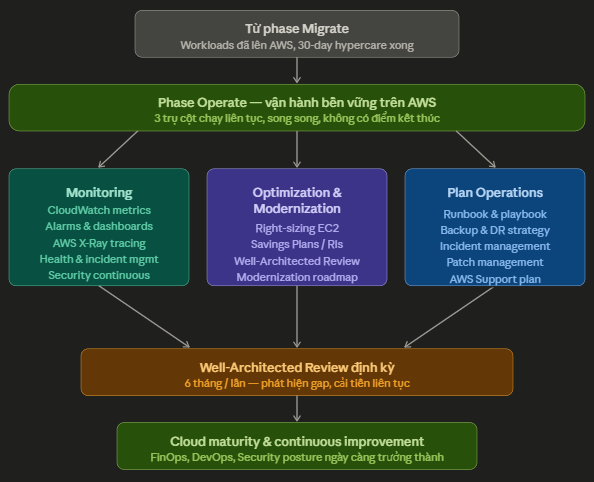
Điểm khác biệt căn bản so với 3 phase trước: Assess, Mobilize, Migrate đều có điểm kết thúc rõ ràng — Operate thì không. Đây là trạng thái thường trực, liên tục cải tiến theo vòng lặp.
Trụ cột 1 — Monitoring the migrated environment
Mục tiêu là có khả năng quan sát toàn diện (full observability) trên toàn bộ môi trường AWS — không chỉ biết hệ thống có đang chạy không, mà còn biết đang chạy như thế nào và tại sao khi có vấn đề.
Observability stack 3 tầng
- Metrics — CloudWatch: Nền tảng monitoring của AWS. Mỗi service AWS tự động publish metrics về CloudWatch (EC2 CPU/memory nếu cài CloudWatch Agent, RDS connections/IOPS, ALB request count/latency, Lambda duration/errors...). Từ đó xây dựng:
- CloudWatch Alarms kết hợp SNS để notify khi vượt ngưỡng — ví dụ CPU > 80% trong 5 phút liên tiếp → alert PagerDuty → on-call engineer nhận notification.
- CloudWatch Dashboards tổng hợp metrics của nhiều service vào một màn hình — cực kỳ quan trọng trong 30–90 ngày đầu sau migration khi team cần nhìn thấy toàn cảnh liên tục.
- CloudWatch Composite Alarms kết hợp nhiều alarm để giảm alert fatigue — chỉ alert khi cả CPU cao và error rate tăng, không alert riêng lẻ từng cái.
- Traces — AWS X-Ray: Cho distributed tracing — theo dõi một request đi qua bao nhiêu service (API Gateway → Lambda → DynamoDB → SQS → Lambda khác) mất thời gian ở đâu, lỗi phát sinh ở service nào. X-Ray Service Map vẽ ra dependency graph trực quan giúp phát hiện bottleneck và cascading failures. Bắt buộc cài cho bất kỳ kiến trúc microservices hay serverless nào.
- Logs — CloudWatch Logs + Log Insights: Tập trung toàn bộ application logs, system logs, và AWS service logs (VPC Flow Logs, CloudTrail, ALB Access Logs) về CloudWatch Logs. Dùng CloudWatch Log Insights để query phân tích nhanh khi debug — cú pháp gần giống SQL, query kết quả trong vài giây dù log hàng GB. Với tổ chức có nhu cầu phân tích log phức tạp hơn, có thể ship sang Amazon OpenSearch Service.
Security monitoring liên tục
Sau migration, security không phải là công việc làm một lần rồi thôi. Cần duy trì:
- AWS Security Hub tổng hợp findings từ GuardDuty (threat detection), Inspector (vulnerability scanning cho EC2 và container), Macie (sensitive data detection trong S3), và IAM Access Analyzer (phát hiện resource được share ra ngoài account). Security Hub score theo thời gian cho thấy security posture đang tốt lên hay xấu đi.
- AWS Config liên tục track configuration changes và so sánh với baseline. Config Rules báo động khi có deviation — ví dụ: S3 bucket đột nhiên bật public access, Security Group mở port 22 ra internet, encryption bị tắt trên EBS volume. Kết hợp với AWS Config Conformance Packs để enforce compliance frameworks (CIS AWS Foundations, PCI DSS, NIST 800-53) tự động.
- AWS CloudTrail ghi lại toàn bộ API call trong account — ai làm gì, lúc nào, từ IP nào. Là audit trail không thể thiếu cho compliance và forensics. Nên enable CloudTrail Insights để tự động phát hiện unusual API activity pattern.
- AWS Health & incident management
- AWS Health Dashboard thông báo khi AWS có planned maintenance hoặc service event ảnh hưởng đến resources của bạn cụ thể — không phải thông báo chung chung mà là "EC2 instance i-xxx của bạn trong us-east-1 bị ảnh hưởng bởi hardware issue". Tích hợp AWS Health vào PagerDuty hoặc Slack để team nhận thông báo ngay lập tức.
Trụ cột 2 — Application optimization & Modernization
Đây là nơi thực sự hiện thực hóa giá trị cloud — không phải ngay ngày đầu sau migration mà là quá trình liên tục trong 12–36 tháng tiếp theo. Có thể chia thành hai chân: tối ưu chi phí ngắn hạn và hiện đại hóa dài hạn.
Tối ưu chi phí — FinOps
- Right-sizing EC2 là bước đầu tiên và thường cho kết quả nhanh nhất. Trong 30–60 ngày đầu sau migration, chạy AWS Compute Optimizer để phân tích utilization thực tế và đề xuất instance type phù hợp. Rất nhiều workload được lift-and-shift lên với instance size giống on-prem nhưng thực tế utilization chỉ 20–30% — right-sizing về instance nhỏ hơn có thể tiết kiệm 30–40% chi phí EC2 ngay lập tức.
- Savings Plans và Reserved Instances là bước tiếp theo sau khi đã right-size và workload pattern đã ổn định (ít nhất 30–60 ngày observing). Compute Savings Plans linh hoạt nhất — áp dụng cho bất kỳ EC2 instance family/region/OS nào, cả Lambda và Fargate. EC2 Instance Savings Plans tiết kiệm nhiều hơn (tới 72%) nhưng lock vào instance family cụ thể trong một region. Committed 1 năm tiết kiệm ít hơn nhưng ít rủi ro hơn so với 3 năm.
- AWS Cost Anomaly Detection dùng ML để tự động phát hiện chi phí bất thường — ví dụ một Lambda function đột nhiên invoke nhiều gấp 10 lần bình thường do bug trong code, hoặc data transfer cost tăng đột biến do misconfiguration. Alert ngay khi phát hiện thay vì phát hiện khi nhận bill cuối tháng.
- S3 Intelligent-Tiering tự động chuyển object ít được truy cập sang tier rẻ hơn (Infrequent Access, Archive) mà không cần viết lifecycle rule thủ công. Đặc biệt hiệu quả cho các bucket chứa log, backup, và media asset có access pattern không đều.
Well-Architected Framework Review định kỳ
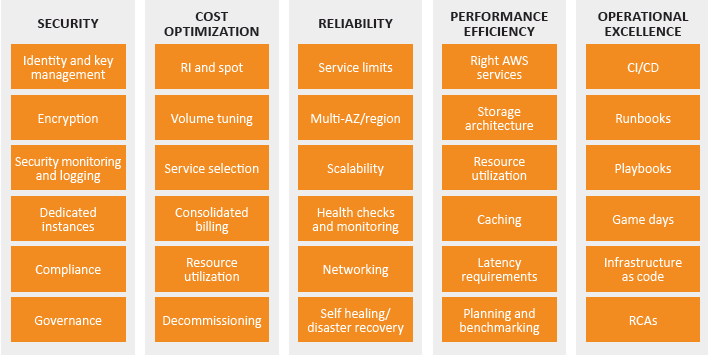
- AWS Well-Architected Tool cho phép tự thực hiện review hoặc mời AWS Partner thực hiện, đánh giá workload theo 6 pillars (Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, Sustainability). Mỗi pillar có hàng chục câu hỏi cụ thể, kết quả ra danh sách High Risk Issues (HRIs) và Medium Risk Issues (MRIs) kèm best practice remediation.
- Nên thực hiện Well-Architected Review 6 tháng một lần cho production workloads quan trọng. Với MAP, AWS thường hỗ trợ free Well-Architected Remediation — tức là sau khi review phát hiện HRI, AWS cung cấp credits để fix các vấn đề đó.
Modernization roadmap dài hạn
Sau khi đã ổn định vận hành, bắt đầu lên kế hoạch modernization cho các workload còn đang chạy theo kiểu legacy:
- Database modernization: Chuyển từ commercial database (Oracle, SQL Server) sang open-source managed (Aurora PostgreSQL/MySQL) để giảm mạnh license cost. AWS Database Migration Service + Schema Conversion Tool hỗ trợ phần lớn conversion tự động. Workload NoSQL có thể chuyển sang DynamoDB để có scale gần như vô hạn với chi phí thấp hơn nhiều.
- Containerization: Workload đang chạy trên EC2 có thể được containerize dần — dùng App2Container để tự động phát hiện dependencies rồi generate container image. Chạy trên ECS Fargate (serverless container, không cần quản lý node) hoặc EKS (Kubernetes nếu tổ chức đã có Kubernetes expertise).
- Serverless-first cho workload mới: Với bất kỳ tính năng mới nào phát triển sau migration, áp dụng serverless-first approach — Lambda + API Gateway + DynamoDB + EventBridge. Không phải mọi thứ đều phù hợp nhưng rất nhiều use case (API backend, event processing, scheduled jobs, data transformation) hoàn toàn có thể serverless với chi phí rất thấp.
Trụ cột 3 — Plan Operations
Plan Operations là việc thiết kế mô hình vận hành cloud bền vững: ai chịu trách nhiệm về account nào, quy trình incident management theo SRE practices, FinOps để quản lý tài chính cloud (đây là một disciplines mới mà nhiều tổ chức cần học), Cloud Center of Excellence (CCoE) để chia sẻ best practices nội bộ, và tự động hóa thông qua Infrastructure as Code (CloudFormation, Terraform) và GitOps.
Runbook & Playbook
- Runbook là tài liệu step-by-step cho các tác vụ vận hành thường ngày: restart một service, scale out ECS task, rotate credential, restore backup, add capacity. Runbook tốt đến mức junior engineer chưa từng làm việc với hệ thống cũng có thể thực hiện đúng.
- Playbook là tài liệu xử lý incident theo kịch bản: "Application latency tăng đột biến" → check load balancer → check EC2 CPU → check RDS connections → check error logs → escalate nếu không tìm được root cause trong 15 phút. AWS Systems Manager Automation Documents cho phép chuyển nhiều bước trong runbook thành automation script chạy một click.
Backup & Disaster Recovery
- AWS Backup cung cấp centralized backup management cho EC2, EBS, RDS, DynamoDB, EFS, S3 — tất cả từ một console duy nhất. Backup Plan định nghĩa frequency (hourly/daily/weekly), retention period, và cross-region copy. Vault Lock (WORM) đảm bảo backup không thể bị xóa — quan trọng cho compliance.
- DR strategy theo bậc thang chi phí/RTO từ thấp đến cao:
- Backup & Restore: RTO vài giờ, RPO vài giờ, chi phí rất thấp — phù hợp cho workload non-critical.
- Pilot Light: Giữ một môi trường DR tối thiểu luôn chạy (chỉ database và core service), scale up khi disaster — RTO 30–60 phút.
- Warm Standby: DR environment chạy ở capacity nhỏ hơn production, switch traffic nhanh — RTO vài phút.
- Multi-Site Active/Active: Cả hai region đều nhận traffic, không có downtime — RTO gần 0, chi phí gấp đôi.
- AWS Elastic Disaster Recovery (DRS) — công cụ DR native của AWS, tương tự MGN nhưng cho DR use case — liên tục replicate server về DR region với RPO tính bằng giây.
Patch Management
- AWS Systems Manager Patch Manager tự động hóa patching cho EC2 fleet theo Patch Baseline (quy định patch nào được approve tự động, patch nào cần manual review) và Maintenance Window (thời gian được phép apply patch — thường ngoài giờ cao điểm). Patch compliance report cho thấy % instance đã patched theo từng baseline.
- Với container workload, cần pipeline tự động rebuild image khi có base image mới (Amazon Linux 2023, Ubuntu...) — dùng EC2 Image Builder kết hợp EventBridge rule trigger khi AWS publish AMI mới.
AWS Support Plan
Chọn support plan phù hợp với criticality của workload:
| Plan | Phù hợp | Response time critical |
|---|---|---|
| Basic | Dev/test, non-prod | Chỉ có documentation |
| Developer | 1 account, test workload | 12 giờ (business hours) |
| Business | Production workload | 1 giờ |
| Enterprise On-Ramp | Production lớn | 30 phút + TAM nhóm |
| Enterprise | Mission-critical | 15 phút + TAM riêng |
Với tổ chức đã migrate production lên AWS, tối thiểu nên ở Business Support để có access 24/7 và SLA 1 giờ cho critical case. Technical Account Manager (TAM) ở Enterprise plan là người đồng hành chiến lược lâu dài — review architecture, cảnh báo về thay đổi service, hỗ trợ plan cho event lớn (peak season, product launch).
Well-Architected Review — vòng lặp cải tiến liên tục
Toàn bộ phase Operate được kết nối bởi vòng lặp Well-Architected Review 6 tháng/lần. Mỗi cycle: Review → Phát hiện HRI/MRI → Prioritize → Remediate → Measure → Review lại. Đây là cơ chế chính để cloud maturity của tổ chức tăng trưởng có hệ thống thay vì ngẫu nhiên.
Kết quả có thể đo lường được sau 12–24 tháng Operate tốt: chi phí AWS giảm 20–35% so với ngay sau migration nhờ right-sizing và Savings Plans, MTTR (Mean Time to Recover) giảm nhờ runbook và automation, security finding count giảm nhờ continuous remediation, và team có thể deploy infrastructure mới trong giờ thay vì tuần — đây mới là giá trị thực sự của cloud.
Tổng kết và lời khuyên thực tế
Trong thực tế, các phase thường overlap. Khi bạn đang ở phase Migrate cho wave thứ ba, bạn đồng thời đã ở phase Operate cho wave đầu tiên. Và những bài học từ Operate phải được feedback ngược lại để cải thiện phase Migrate.
Một câu hỏi tôi muốn bạn tự suy ngẫm để hiểu sâu hơn: nếu một khách hàng nói rằng họ muốn "migrate 500 server lên AWS trong 6 tháng và không có thời gian cho phase Assess", bạn sẽ tư vấn họ thế nào? Bạn sẽ thấy rằng việc bỏ qua Assess không tiết kiệm thời gian — nó chỉ chuyển thời gian sang phase Migrate dưới dạng các sự cố và rework. Đây là lý do AWS thiết kế template theo cách này dựa trên dữ liệu từ hàng nghìn dự án.