AWS Disaster Recovery: Choosing the Right Strategy for Your Workload
Tháng 3/2026, các cuộc tấn công bằng drone vào khu vực Trung Đông đã trực tiếp phá huỷ hai data center của AWS tại UAE và một facility tại Bahrain, khiến hàng loạt ứng dụng và dịch vụ số tại khu vực này ngừng hoạt động. Careem (ứng dụng gọi xe và giao hàng), Alaan, Hubpay (Payment Service), ADCB và Emirates NBD (Bank), Snowflake (enterprise data) — tất cả đều báo cáo outage. AWS phải khuyến cáo khẩn: "Các khách hàng có workload đang chạy ở Middle East hãy migrate ngay sang AWS Region khác."
Đây không phải kịch bản trong giả thuyết. Đây là thực tế đã xảy ra — và nó nhắc nhở một điều: thảm hoạ có thể đến từ bất kỳ đâu, từ thiên tai, sự cố kỹ thuật, cho đến xung đột địa chính trị. Câu hỏi không phải là "liệu thảm hoạ có xảy ra không" mà là "khi nó xảy ra, hệ thống của bạn có sẵn sàng không?"
Những doanh nghiệp có chiến lược Disaster Recovery (DR) tốt — với workload được replicate sang Region khác — đã phục hồi trong vài phút. Những doanh nghiệp không có DR thì chỉ biết chờ AWS khôi phục hạ tầng, không có gì trong tay để tự cứu mình.
Bài viết này sẽ giải thích chi tiết về 4 chiến lược Disaster Recovery trên AWS:
- Backup and Restore — Sao lưu và phục hồi
- Pilot Light — Duy trì data layer chạy liên tục, application servers chưa deploy
- Warm Standby — Hạ tầng đầy đủ nhưng thu nhỏ, luôn sẵn sàng
- Multi-Site Active/Active — Hai hoặc nhiều Region hoạt động song song
Và quan trọng hơn: giúp bạn chọn đúng chiến lược cho workload của mình.
Trước tiên: RTO và RPO là gì?
Trước khi đi vào từng chiến lược, bạn cần hiểu hai khái niệm nền tảng mà mọi quyết định DR đều xoay quanh.
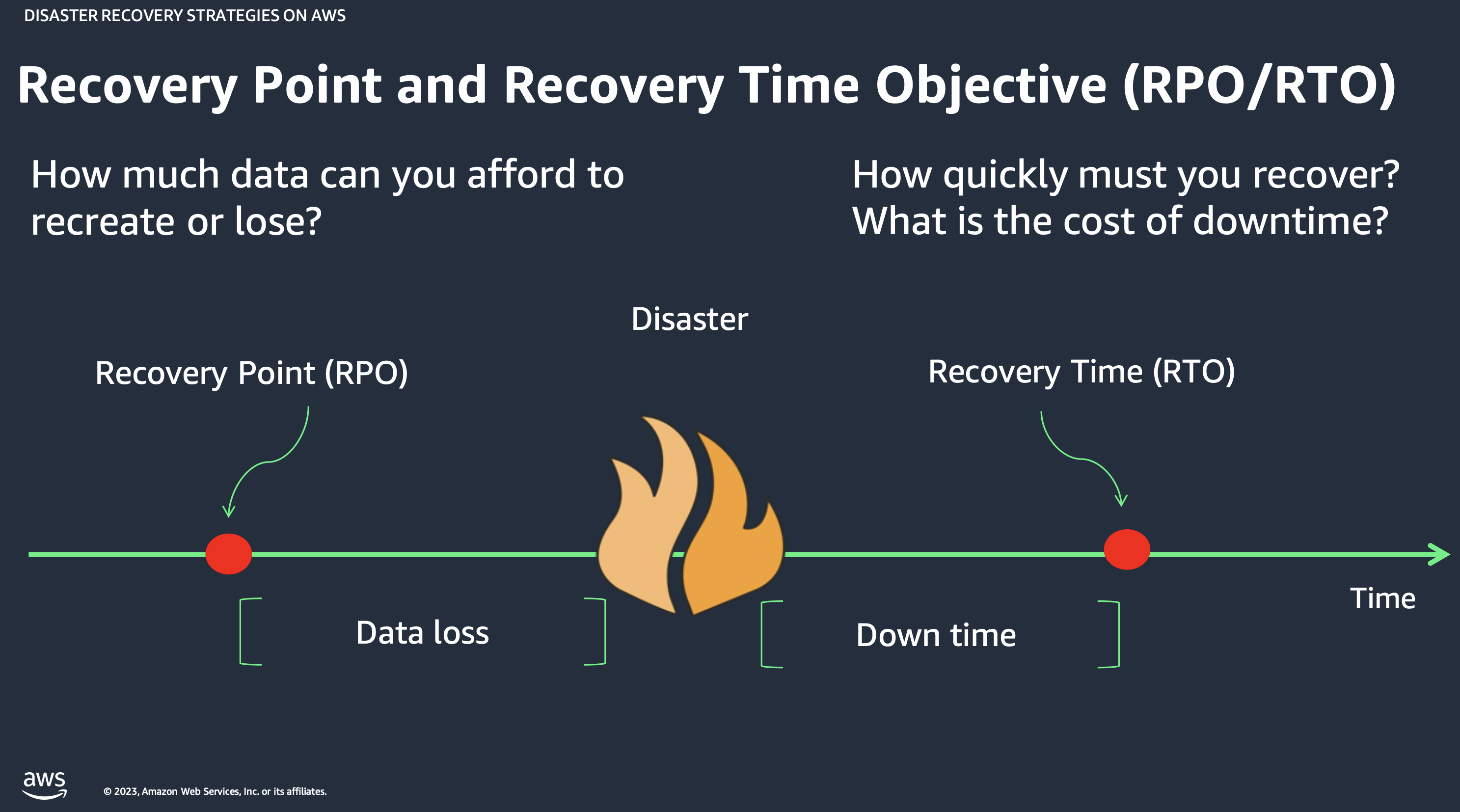
Recovery Time Objective (RTO)
RTO là khoảng thời gian tối đa mà hệ thống được phép ngừng hoạt động sau một sự cố. Nói đơn giản: "Tôi có thể chịu đựng downtime bao lâu?"
Ví dụ: Nếu RTO = 4 giờ, nghĩa là hệ thống phải được phục hồi trong vòng 4 giờ kể từ khi xảy ra sự cố. Nếu quá thời gian này, tổn thất về kinh doanh là không thể chấp nhận được.
Recovery Point Objective (RPO)
RPO là khoảng thời gian dữ liệu tối đa có thể bị mất khi xảy ra thảm hoạ. Nói đơn giản: "Tôi có thể mất bao nhiêu dữ liệu?"
Ví dụ: Nếu RPO = 1 giờ và bạn backup mỗi giờ một lần, trong trường hợp xấu nhất bạn sẽ mất 1 giờ dữ liệu — đây là mức chấp nhận được.
Tại sao RTO và RPO quan trọng?
Chúng là "ngôn ngữ chung" giữa kỹ thuật và kinh doanh. Khi bạn nói chuyện với CTO hay CEO về DR, đừng nói "chúng ta cần multi-region" — hãy nói "RTO hiện tại của chúng ta là 8 giờ, chi phí downtime mỗi giờ là $50,000, nếu đầu tư thêm X dollar vào DR thì RTO giảm xuống còn 15 phút."
Quy tắc chung: RTO và RPO càng thấp → chi phí DR càng cao. Nhiệm vụ của architect là tìm điểm cân bằng hợp lý.
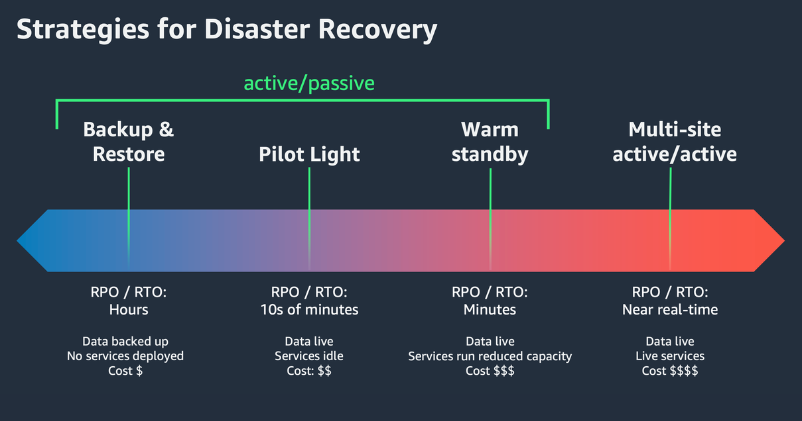
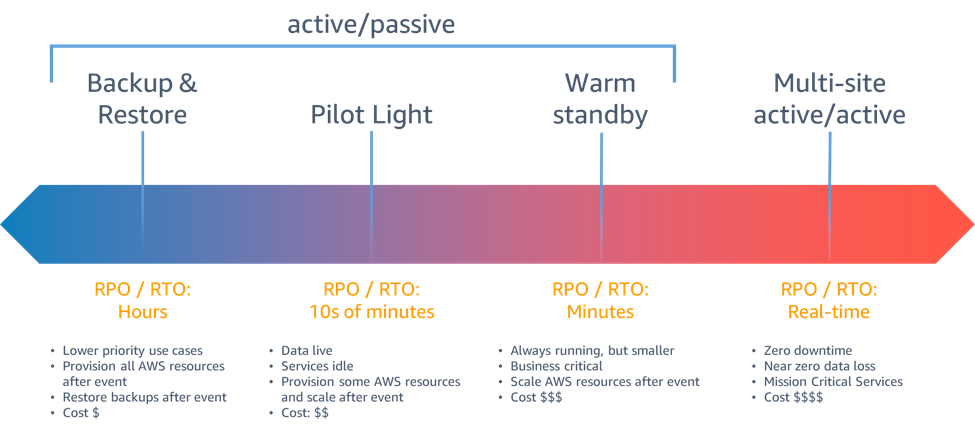
4 Chiến Lược Disaster Recovery Trên AWS
AWS chia DR thành 4 chiến lược theo thứ tự từ đơn giản/rẻ đến phức tạp/đắt. Mỗi chiến lược đánh đổi giữa chi phí và khả năng phục hồi nhanh.
Chiến lược 1: Backup and Restore
Backup and Restore là gì?
Đây là chiến lược đơn giản và tiết kiệm nhất. Bạn định kỳ sao lưu dữ liệu (và cả cấu hình hạ tầng) sang một Region khác. Khi xảy ra thảm hoạ, bạn khôi phục dữ liệu từ backup và deploy lại toàn bộ hạ tầng từ đầu tại Region DR.
Đặc điểm:
- RTO: Vài giờ đến vài ngày (tuỳ vào độ phức tạp của hạ tầng)
- RPO: Bằng khoảng thời gian giữa hai lần backup (ví dụ: backup mỗi 6 giờ → RPO = 6 giờ)
- Chi phí: Thấp nhất — bạn chỉ trả cho storage của backup
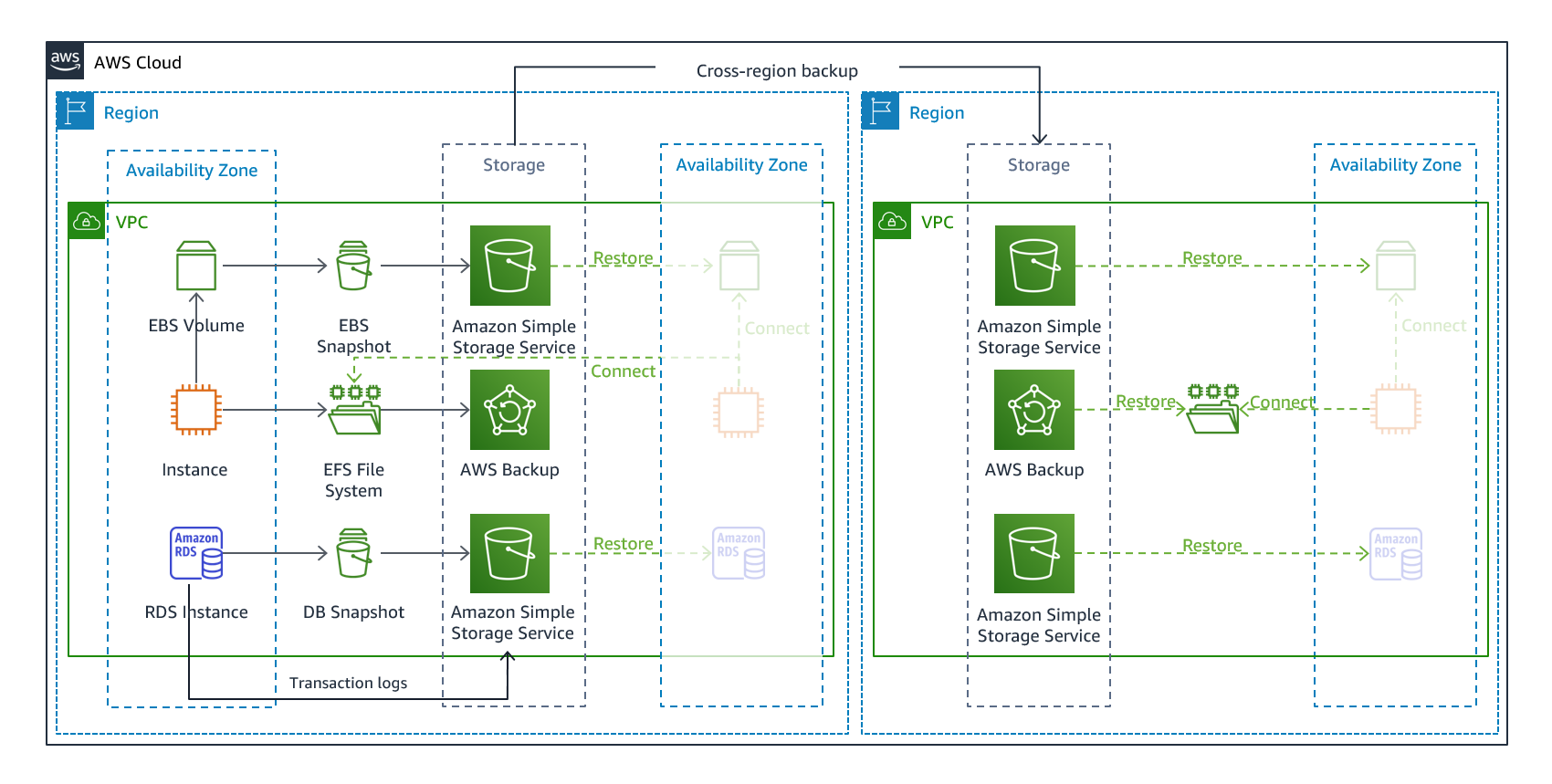
Cần backup những gì?
Một sai lầm phổ biến là chỉ backup dữ liệu mà quên backup hạ tầng. Khi thảm hoạ xảy ra, bạn cần khôi phục cả hai.
Backup dữ liệu: Point-in-Time Recovery
Backup tốt phải cho phép restore về đúng thời điểm backup được tạo — từ đó bạn chọn backup gần nhất trước khi thảm hoạ xảy ra để khôi phục. Một số services còn hỗ trợ point-in-time recovery (PITR), như DynamoDB hay RDS automated backups. AWS cung cấp cơ chế này cho các services sau:
| Service | Cơ chế backup |
|---|---|
| Amazon EBS | EBS Snapshots |
| Amazon RDS | Automated snapshots + PITR (transaction logs mỗi 5 phút) |
| Amazon Aurora | Aurora DB snapshots + PITR |
| Amazon DynamoDB | On-demand backup + Point-in-time recovery (PITR) |
| Amazon EFS | AWS Backup |
| Amazon Redshift | Automated snapshots |
| Amazon Neptune | Automated snapshots |
| Amazon DocumentDB | Automated snapshots |
| Amazon FSx (Windows, Lustre, NetApp ONTAP, OpenZFS) | AWS Backup |
AWS Backup — Trung Tâm Quản Lý Backup
AWS Backup là dịch vụ tập trung để configure, schedule và monitor backup cho toàn bộ hạ tầng. Thay vì quản lý backup rải rác từng service, AWS Backup cho phép bạn định nghĩa backup policies một nơi và áp dụng cho:
- Amazon EBS volumes
- Amazon EC2 instances
- Amazon RDS databases (bao gồm Aurora)
- Amazon DynamoDB tables
- Amazon EFS file systems
- AWS Storage Gateway volumes
- Amazon FSx (Windows File Server, Lustre, NetApp ONTAP, OpenZFS)
Hai tính năng đặc biệt quan trọng của AWS Backup:
Cross-region backup copy: Tự động copy backup sang DR Region theo schedule — đây là backbone của Backup & Restore strategy.
Cross-account backup: Cho phép sao lưu sang một AWS account khác, bảo vệ trước insider threats hoặc account compromise. Nếu attacker chiếm quyền account chính và xoá mọi thứ, backup ở account riêng biệt vẫn an toàn.
Backup hạ tầng — Phần Hay Bị Bỏ Quên
Nếu không có Infrastructure as Code (IaC), việc deploy lại toàn bộ hạ tầng tại Region DR sẽ mất rất nhiều thời gian và dễ xảy ra lỗi, dẫn đến RTO bị kéo dài nghiêm trọng.
AWS CloudFormation hoặc AWS CDK là công cụ cần thiết: định nghĩa toàn bộ hạ tầng dưới dạng code, khi cần failover chỉ việc chạy lại template tại DR Region.
Amazon Machine Images (AMIs): Backup EC2 instances dưới dạng AMI (bao gồm OS, packages, cấu hình) và copy sang DR Region. Khi failover, launch EC2 từ AMI này là xong. AWS Backup hỗ trợ EC2 backup với metadata bổ sung: instance type, VPC, security group, IAM role, monitoring config, và tags.
Lưu ý quan trọng về S3 và data corruption
S3 Cross-Region Replication (CRR) sao chép dữ liệu liên tục (gần real-time) sang DR Region — nhưng cũng có nghĩa là nếu ai đó vô tình xoá dữ liệu, thao tác xoá đó cũng replicate ngay lập tức.
Đây là lý do bạn cần kết hợp S3 Object Versioning: khi enable versioning, S3 chỉ thêm một "delete marker" thay vì xoá thực sự — bạn vẫn khôi phục được về version trước. Quan trọng hơn: khi dùng S3 replication, mặc định delete marker chỉ được thêm ở source bucket, không replicate sang DR bucket — dữ liệu ở DR Region được bảo vệ khỏi malicious deletion từ Region chính.
Tự động hoá restore — Đừng chờ đến lúc cần mới làm
AWS Backup cung cấp restore capability nhưng không hỗ trợ scheduled hoặc automatic restoration theo mặc định. Bạn cần implement automation bằng AWS SDK để trigger restore tự động — ví dụ: dùng Amazon SNS + AWS Lambda để tự động restore mỗi khi backup hoàn thành.
Tại sao điều này quan trọng? Restore từ backup là control plane operation — nếu Region DR đang gặp sự cố, chính control plane có thể không available. Nhưng nếu bạn đã setup scheduled periodic restore, bạn có sẵn data stores hoạt động được tại DR Region từ backup gần nhất, không cần chờ restore mới.
Khi nào nên dùng Backup and Restore?
- Workload không yêu cầu uptime cao (ví dụ: hệ thống nội bộ, batch processing)
- RTO chấp nhận được từ vài giờ trở lên
- Budget hạn chế
- Mục tiêu DR chỉ là bảo vệ dữ liệu, không phải đảm bảo availability liên tục
Chiến lược 2: Pilot Light
Pilot Light là gì?
Hãy tưởng tượng "ngọn lửa mồi" (pilot light) trong bếp gas — nó luôn cháy âm ỉ để sẵn sàng bùng cháy lớn khi cần. Trong DR, Pilot Light nghĩa là: các thành phần cốt lõi (databases, data stores) luôn chạy và được đồng bộ dữ liệu từ Primary Region. Các thành phần khác (application servers) đã được chuẩn bị code và config sẵn nhưng chưa được deploy — chỉ khi failover xảy ra mới "bật lên".
Đặc điểm:
- RTO: Vài chục phút (vì cần "bật" servers và scale up)
- RPO: Gần bằng 0 (nhờ continuous replication) với regional outage. Tuy nhiên, với data corruption hay ransomware, replication cũng sao chép dữ liệu bị hỏng — khi đó phải restore từ point-in-time backup, RPO > 0
- Chi phí: Vừa phải — chủ yếu là chi phí cho databases và storage đang chạy ở DR Region
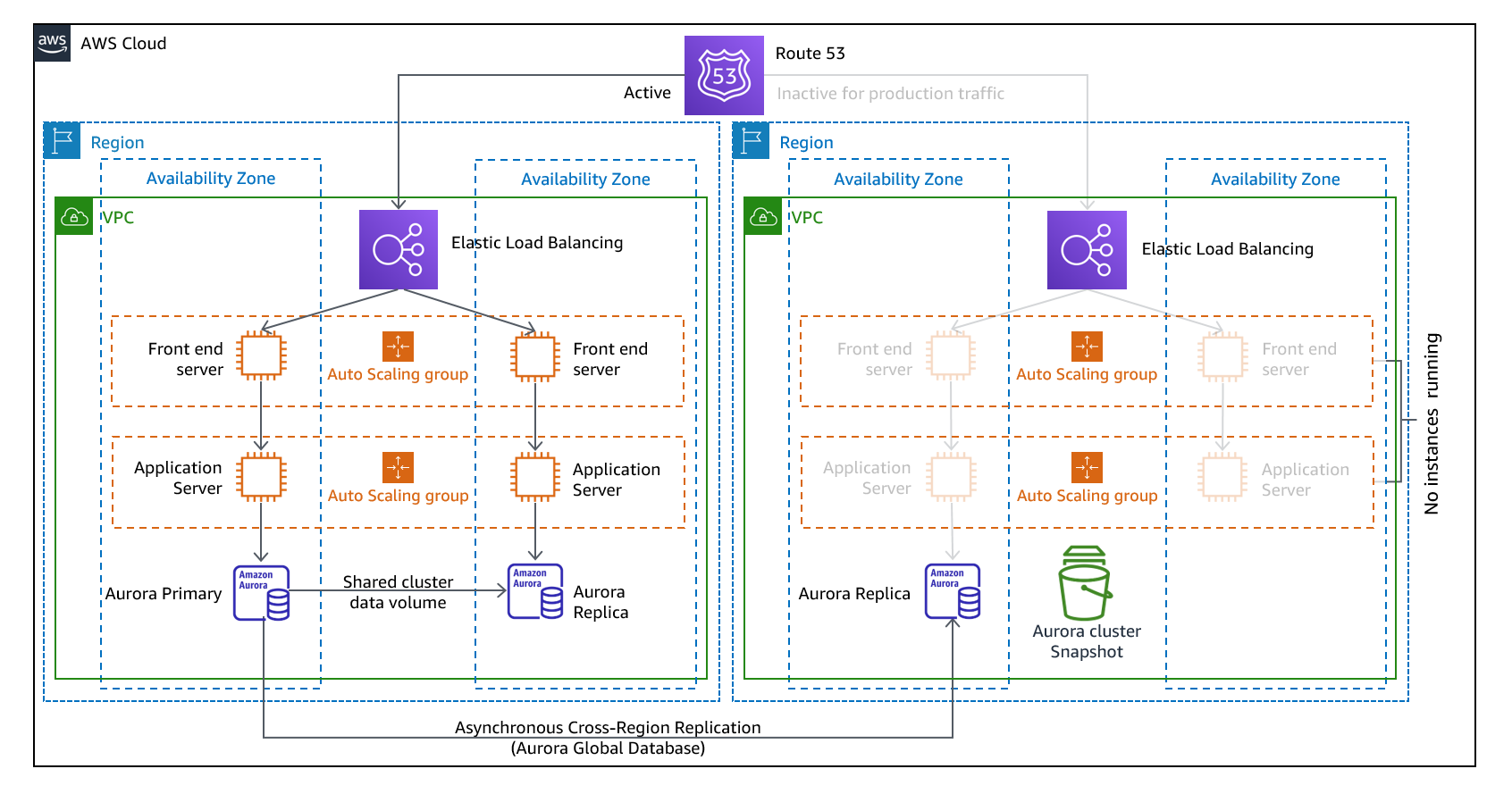
Continuous Data Replication — Trái Tim Của Pilot Light
Điểm mạnh nhất của Pilot Light so với Backup & Restore là dữ liệu được đồng bộ liên tục, không phải chờ đến lịch backup tiếp theo.
AWS cung cấp replication cross-region cho các services sau:
| Service | Cơ chế replication |
|---|---|
| Amazon Aurora | Aurora Global Database — replication < 1 giây, hỗ trợ tối đa 5 secondary Regions |
| Amazon RDS | Read Replicas cross-region |
| Amazon DynamoDB | Global Tables — multi-region, multi-master |
| Amazon S3 | Cross-Region Replication (CRR) |
| Amazon ElastiCache (Redis) | Global Datastore |
| Amazon DocumentDB | Global Clusters |
Aurora Global Database đặc biệt ấn tượng: nó sử dụng dedicated infrastructure riêng biệt (không ảnh hưởng đến workload chính), replication latency thường dưới 1 giây, và khi failover, bạn có thể promote secondary Region lên primary trong chưa đầy 1 phút — ngay cả khi Primary Region bị outage hoàn toàn.
"Tắt" server trong Pilot Light đúng cách
Best practice là không deploy EC2 instances tại DR Region (thay vì deploy rồi stop). Tại sao?
- Không phát sinh chi phí instance (chỉ trả cho AMI storage và EBS snapshot)
- Sạch hơn về mặt quản lý
- Khi cần "bật", bạn deploy từ AMI đã chuẩn bị sẵn (đã copy sang DR Region)
Dùng CloudFormation với conditional logic để deploy hạ tầng thu nhỏ/tắt ở DR Region và full production ở Primary Region — từ một codebase duy nhất.
Failover Traffic: Route 53 vs Global Accelerator
Khi Primary Region không còn khả dụng, bạn cần chuyển traffic sang DR Region. Có hai cách chính:
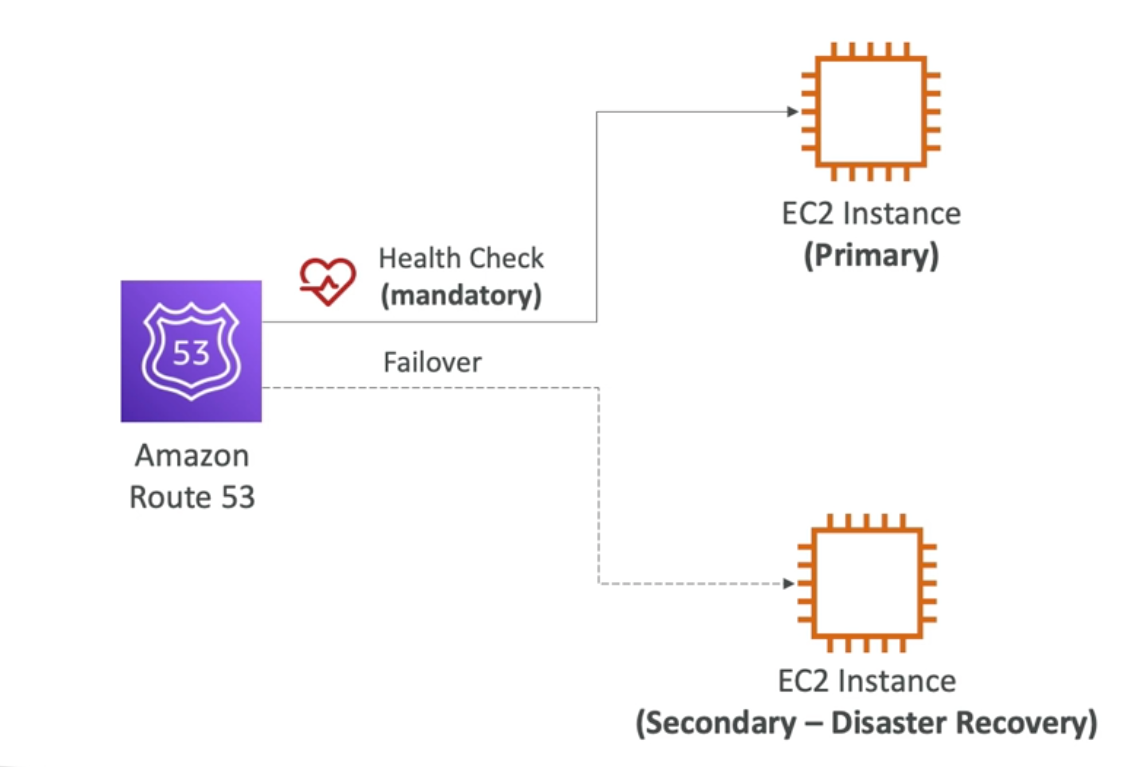
Dùng Amazon Route 53:
- Tạo health checks cho endpoint của Primary Region
- Cấu hình DNS failover — khi health check fail, Route 53 tự động route traffic sang DR Region
- Đây là data plane operation → độ tin cậy cao
- Nhược điểm: DNS có cache, cần chờ TTL expire (thường 60 giây trở lên)
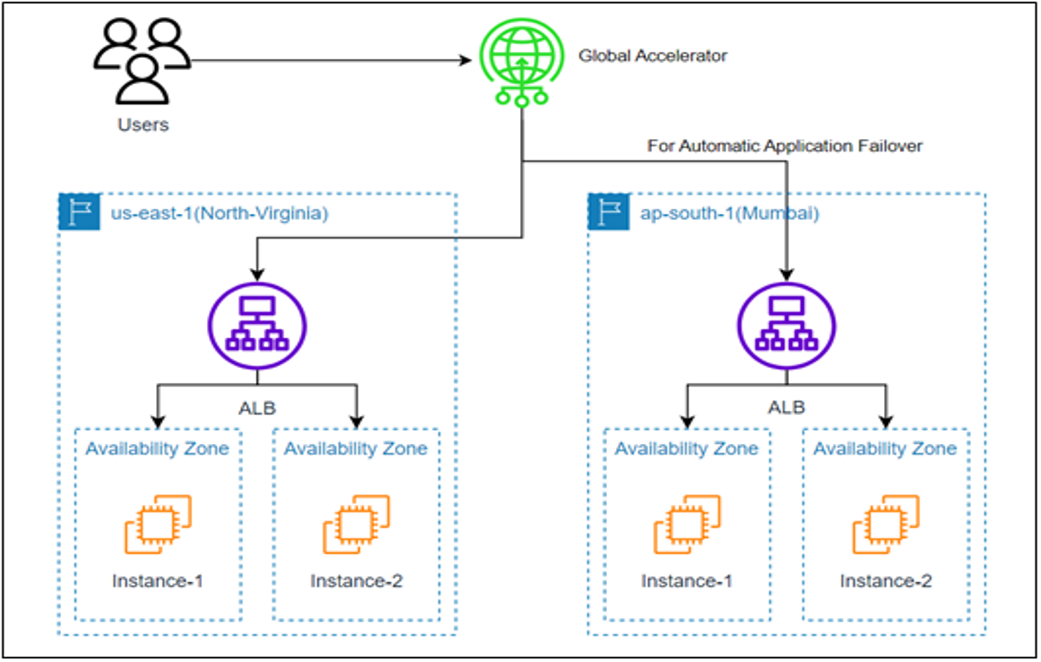
Dùng AWS Global Accelerator:
- Dùng AnyCast IP — cùng một IP nhưng route đến endpoint gần nhất/healthy nhất
- Failover nhanh hơn Route 53 (không bị ảnh hưởng DNS cache)
- Traffic đi vào AWS backbone network ngay từ edge → latency thấp hơn
- Nhược điểm: Chi phí cao hơn Route 53
Dùng Amazon Application Recovery Controller (ARC): Nếu bạn muốn failover thủ công (để tránh false alarm), ARC cho phép tạo Route 53 health checks hoạt động như "công tắc on/off" — bạn kiểm soát hoàn toàn khi nào traffic được chuyển sang DR Region thông qua data plane API.
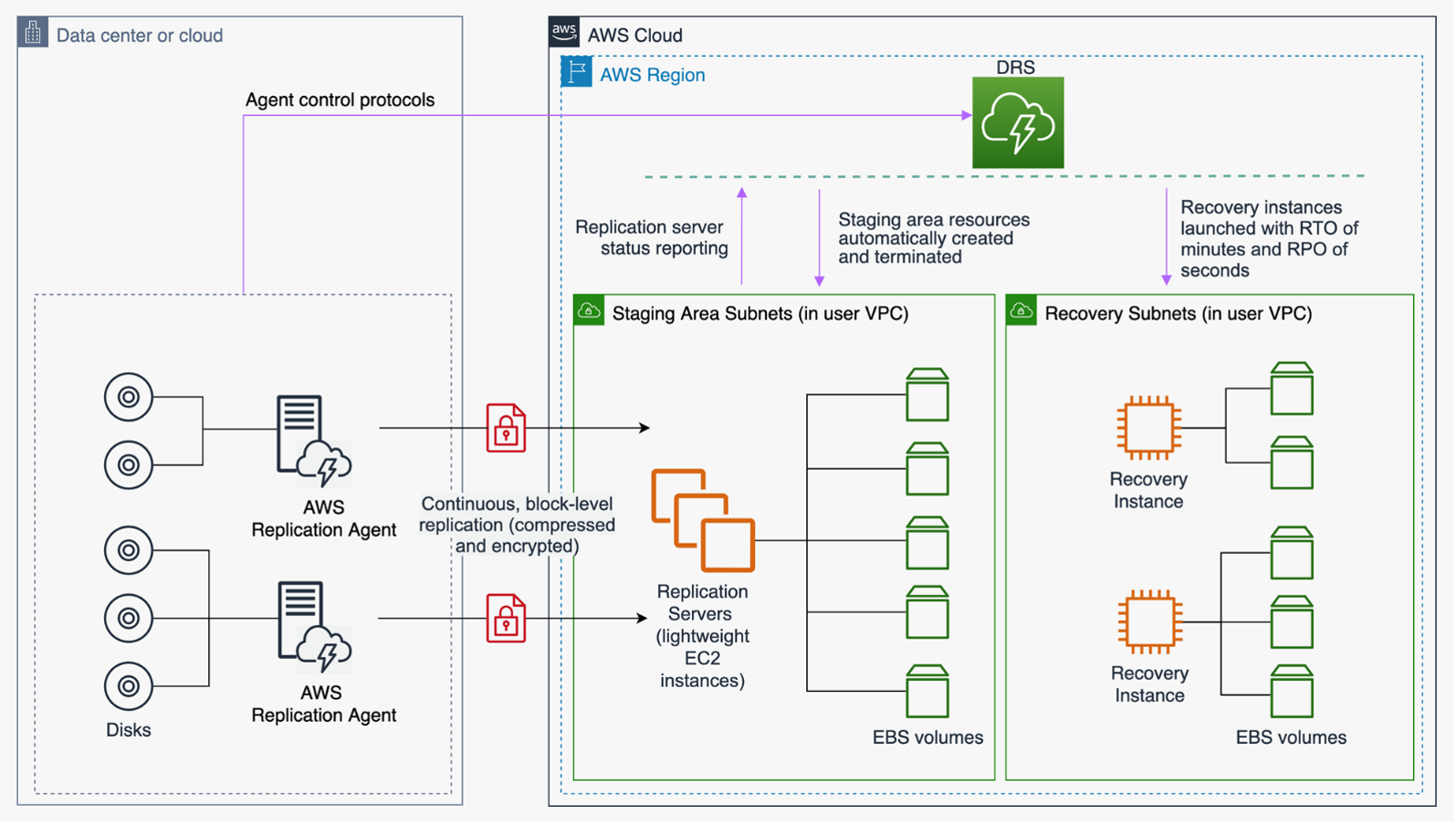
AWS Elastic Disaster Recovery (DRS)
Đây là service đặc biệt dành cho workload on-premises hoặc EC2-based: nó continuously replicate server ở block-level sang AWS, duy trì một "staging area" nhỏ (kiểu Pilot Light), và khi failover, tự động spin up full-capacity environment tại DR Region.
Rất hữu ích khi bạn đang migrate từ on-premises lên AWS và cần DR ngay cả trong giai đoạn chuyển đổi.
Chiến lược 3: Warm Standby
Warm Standby là gì?
Warm Standby đẩy Pilot Light lên một bậc: thay vì "tắt" servers tại DR Region, bạn luôn duy trì một bản thu nhỏ của môi trường production đang hoạt động. DR Region có thể nhận traffic ngay lập tức — chỉ ở capacity thấp hơn. Khi failover, bạn chỉ cần scale up chứ không cần deploy từ đầu.
Đặc điểm:
- RTO: Vài phút (chỉ cần scale up, không cần boot servers)
- RPO: Gần bằng 0 (nhờ continuous replication)
- Chi phí: Cao hơn Pilot Light — vì servers DR Region luôn chạy (dù ít hơn production)
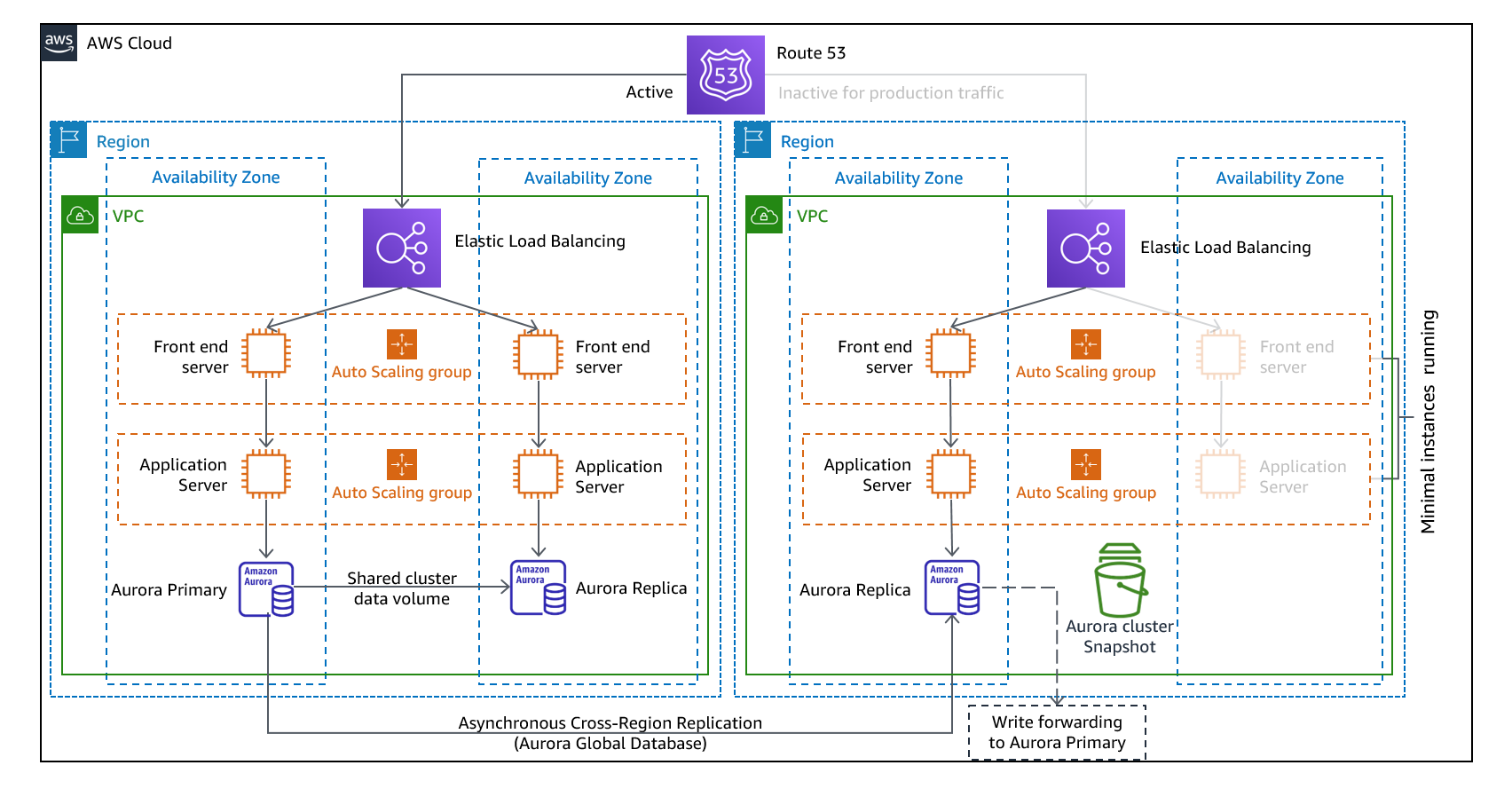
Sự Khác Biệt Giữa Pilot Light và Warm Standby
Đây là điểm hay bị nhầm lẫn:
| Tiêu chí | Pilot Light | Warm Standby |
|---|---|---|
| Application servers tại DR | Chưa deploy | Đang chạy (ít instances) |
| Khả năng nhận traffic ngay | Không | Có (capacity thấp) |
| Thời gian failover | Vài chục phút | Vài phút |
| Chi phí DR ongoing | Thấp hơn | Cao hơn |
| Khi failover cần làm gì | Deploy servers + Scale up | Chỉ Scale up |
Nguyên tắc đơn giản: Pilot Light = "bật lên" rồi scale. Warm Standby = chỉ cần scale.
Scale Up Với Amazon EC2 Auto Scaling
Khi failover xảy ra và bạn cần tăng capacity DR Region lên production level, Amazon EC2 Auto Scaling là công cụ chính:
- Tăng
desired capacitycủa Auto Scaling Group lên bằng với production - Có thể thực hiện qua Console, AWS CLI, SDK, hoặc bằng cách redeploy CloudFormation template với giá trị mới
Lưu ý quan trọng: Auto Scaling là control plane operation — nó phụ thuộc vào API của AWS, có thể không available trong một số tình huống regional outage. Đây là trade-off bạn phải chấp nhận khi chọn Warm Standby.
Nếu muốn loại bỏ hoàn toàn dependency này, bạn có thể pre-provision đủ capacity tại DR Region để handle full production traffic ngay lập tức — đây gọi là Hot Standby, một dạng đặc biệt của Warm Standby với chi phí cao hơn nhưng RTO gần bằng 0.
Khi nào nên dùng Warm Standby?
- Workload production quan trọng, không thể chịu downtime quá 15-30 phút
- Budget cho phép duy trì hạ tầng DR đang chạy liên tục
- Cần có khả năng test DR thường xuyên mà không ảnh hưởng production (vì DR environment luôn running)
- RPO yêu cầu gần bằng 0
Chiến lược 4: Multi-Site Active/Active
Multi-Site Active/Active là gì?
Đây là chiến lược mạnh nhất và tốn kém nhất: bạn chạy workload đồng thời tại nhiều AWS Regions, tất cả đều đang thực sự phục vụ traffic. Khi một Region gặp sự cố, traffic tự động được route sang các Region còn lại — không cần "failover" theo nghĩa truyền thống.
Đặc điểm:
- RTO: Gần bằng 0 (không có failover, traffic chỉ đơn giản là đi sang Region khác)
- RPO: Gần bằng 0 (với asynchronous replication) — ngoại trừ data corruption phải dùng backup
- Chi phí: Cao nhất — bạn phải trả cho full infrastructure ở mọi Region
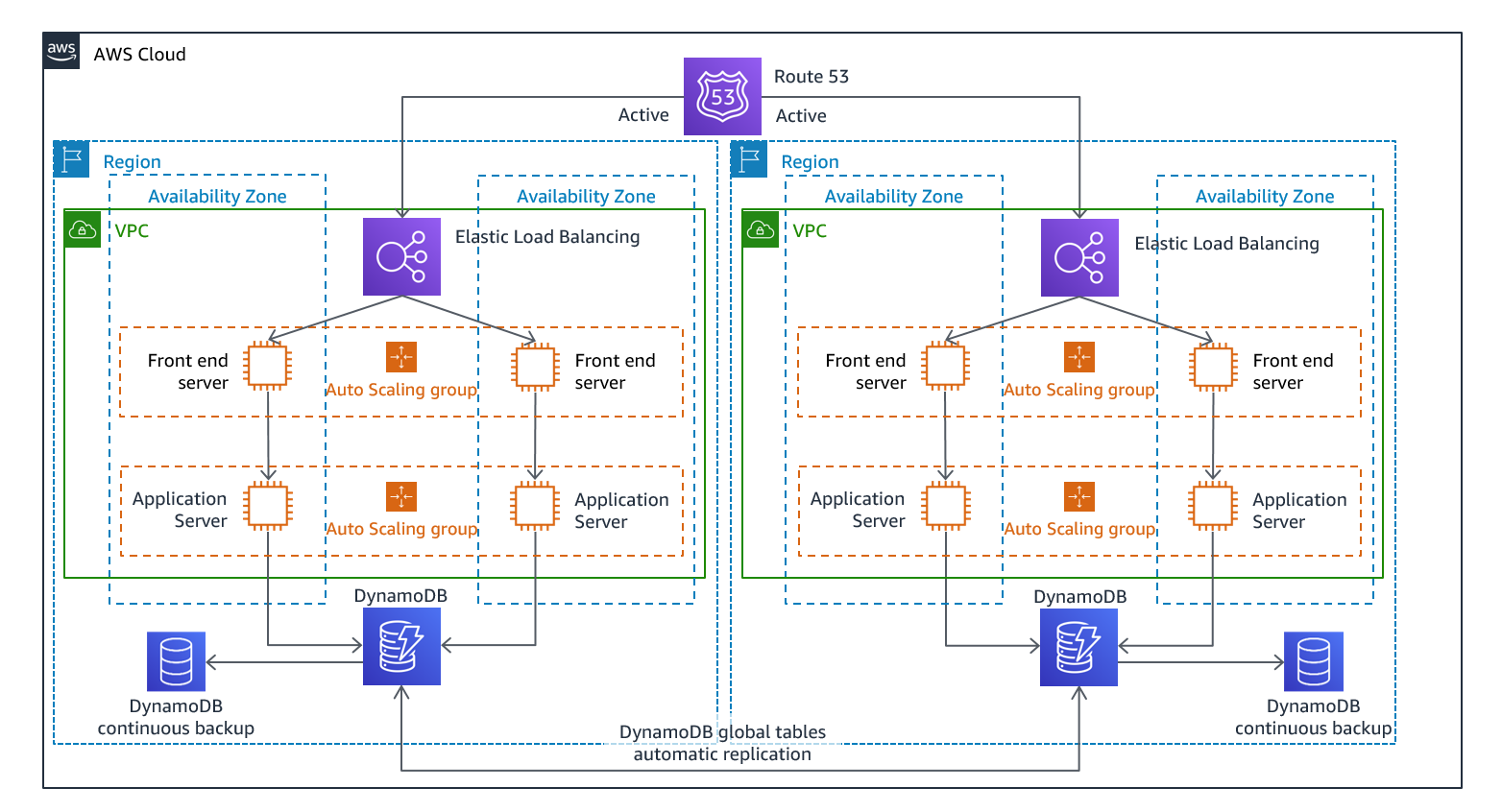
Không Có "Failover" — Chỉ Có Traffic Routing
Với Active/Active, khi Region A có vấn đề, Route 53 health checks hoặc Global Accelerator tự động ngừng gửi traffic đến Region A và toàn bộ tải đổ vào Region B (và các Region khác nếu có). Người dùng có thể nhận thấy latency tăng nhẹ, nhưng không có downtime.
Điều này đòi hỏi bạn phải đảm bảo các Region còn lại có đủ capacity để handle toàn bộ traffic khi một Region fail. Đây thường là yêu cầu over-provisioning 50-100% capacity.
Thách Thức Lớn Nhất: Write Consistency
Với active/passive, tất cả writes đi về Primary Region. Với active/active, khi user ở Singapore write vào Region Singapore và user ở Tokyo write vào Region Tokyo cùng lúc — làm sao đảm bảo data consistency? AWS cung cấp 3 patterns:
Write Global — Tập trung write vào một Region:
Tất cả write requests được route đến một "write Region" duy nhất, các Region khác chỉ serve reads.
- Aurora Global Database phù hợp nhất: supports write forwarding — secondary Regions tự động forward write requests về primary Region. Khi primary Region fail, promote secondary lên primary trong dưới 1 phút.
Write Local — Write tại Region gần nhất:
User ở đâu thì write vào Region đó, replication đồng bộ sau.
- Amazon DynamoDB Global Tables là lựa chọn tốt nhất: hỗ trợ read và write tại mọi Region, dùng "last writer wins" để giải quyết conflict. Đây là lựa chọn phù hợp cho workload cần throughput cao và không yêu cầu strong consistency cho concurrent writes.
Write Partitioned — Phân vùng write theo key:
Assign writes đến Region cụ thể dựa trên partition key (ví dụ: User ID hash). Tránh được conflict hoàn toàn.
- Amazon S3 Bidirectional Replication hỗ trợ cấu hình này giữa 2 Regions. Cần bật
replica modification synctrên cả hai bucket.
So Sánh Active/Active vs Hot Standby
Multi-Site Active/Active: Cả hai Region đều serve traffic bình thường. Tốt nhất khi bạn cần distribute traffic theo geography để giảm latency.
Hot Standby (Active/Passive với full provisioning): Region DR đã sẵn sàng nhưng không nhận traffic thường. Failover khi cần. Đơn giản hơn về mặt data consistency nhưng tốn tiền hơn vì Region DR "ngồi không" chờ.
Hầu hết teams nếu đã bỏ tiền setup full environment ở Region thứ hai thì sẽ dùng Active/Active để tận dụng investment — vừa có DR, vừa giảm latency cho users.
Khi nào nên dùng Multi-Site Active/Active?
- Ứng dụng mission-critical — downtime tính bằng giây là không thể chấp nhận
- Users phân bố trên nhiều châu lục, cần low latency globally
- Regulatory requirements yêu cầu zero downtime
- Revenue impact của downtime rất cao (e-commerce, fintech, gaming)
So Sánh 4 Chiến Lược
| Chiến lược | RTO | RPO | Chi phí | Độ phức tạp | Use case điển hình |
|---|---|---|---|---|---|
| Backup & Restore | Giờ - Ngày | Giờ | Thấp nhất | Thấp | Dev/Test, internal tools |
| Pilot Light | 10-30 phút | Phút | Trung bình | Trung bình | Startup với budget hạn chế |
| Warm Standby | 5-15 phút | Giây - Phút | Cao | Cao | E-commerce, SaaS production |
| Multi-Site Active/Active | Giây | Giây | Cao nhất | Rất cao | Fintech, gaming, mission-critical |
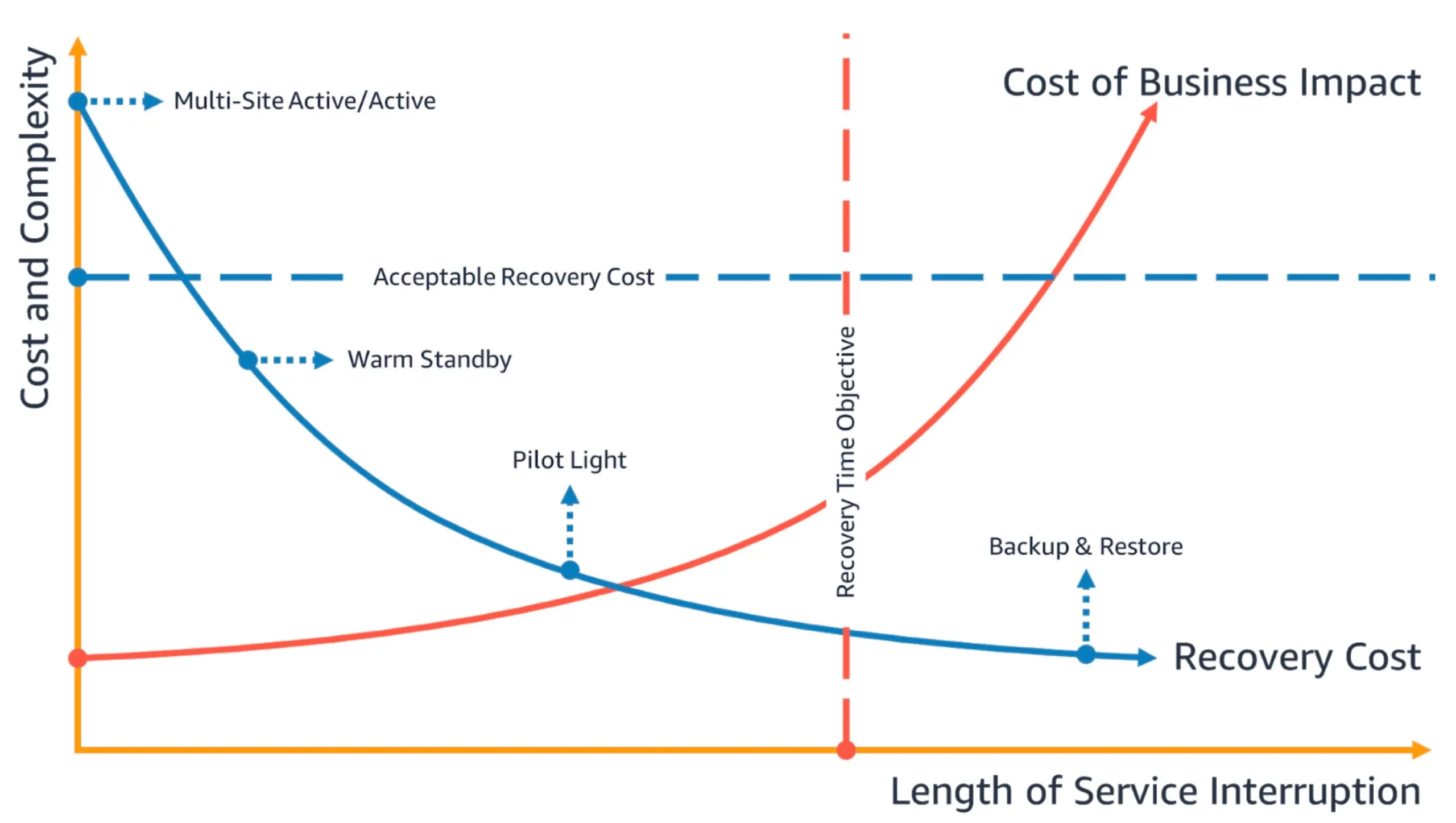
Data Plane vs Control Plane — Điều Ít Người Biết
Khi thiết kế DR, AWS khuyến nghị bạn chỉ dùng data plane operations trong quá trình failover, không phụ thuộc vào control plane.
Tại sao?
- Data Plane: Xử lý traffic thực tế — serve requests, read/write data. Được thiết kế với higher availability goals.
- Control Plane: Quản lý và cấu hình môi trường (deploy EC2, tạo resources, thay đổi config). Ít reliable hơn, đặc biệt khi Region đang gặp vấn đề.
Ví dụ thực tế:
- Route 53 health-check-based failover → data plane ✅ (reliable)
- Thay đổi weighted routing policy qua Console → control plane ⚠️ (có thể không available khi Region gặp sự cố)
- Amazon Application Recovery Controller (ARC) failover API → data plane ✅
- Manually scale Auto Scaling Group → control plane ⚠️
Khi viết runbook failover, hãy kiểm tra từng step và ưu tiên data plane alternatives.
Redundancy Options: Single Region vs Multi-Region
Ngoài 4 chiến lược DR, bạn cũng cần quyết định phạm vi geographic của DR plan:
Multiple Availability Zones (Same Region)
Bảo vệ trước: Sự cố một data center vật lý (điện, network, thiên tai cục bộ)
Mỗi AZ trong một Region hoàn toàn độc lập về điện, network, cooling. Khoảng cách giữa các AZ lên đến 60 dặm nhưng latency chỉ 1-2ms.
Đây là baseline minimum cho mọi production workload. RDS Multi-AZ, ALB across multiple AZs, EC2 Auto Scaling group spanning 3 AZs — đây là thiết kế cơ bản nhất.
Multiple AZs + Backup to Another Region
Bảo vệ trước: Regional outage (toàn bộ Region gặp sự cố)
Thêm backup định kỳ sang Region DR bằng AWS Backup cross-region copy. Đơn giản hơn và rẻ hơn nhiều so với multi-region deployment thực sự.
Phù hợp với Backup & Restore hoặc Pilot Light strategy.
Multiple AWS Regions (Active Deployment)
Bảo vệ trước: Full regional outage — thậm chí nhiều data center ở cùng một geographic area
Đây là mức cao nhất. Workload được deploy và chạy thực sự tại nhiều Regions. Kết hợp với Warm Standby hoặc Multi-Site Active/Active.
Đừng Quên: Test DR Của Bạn
Một DR plan chưa được test = Không có DR plan.
Nhiều teams bỏ công xây dựng DR architecture công phu nhưng chưa bao giờ thực sự thử failover. Đến khi thảm hoạ xảy ra mới phát hiện backup bị corrupt, IAM permissions thiếu, hoặc RTO thực tế gấp 3 lần dự kiến.
AWS khuyến nghị:
- Định kỳ test backup restoration — không chỉ tạo backup mà còn phải verify restore được
- Game day exercises — mô phỏng thảm hoạ và chạy failover trong môi trường staging
- Chaos Engineering — sử dụng AWS Fault Injection Simulator (FIS) để inject failures có kiểm soát
- Dùng AWS Resilience Hub — công cụ tự động assess workload, validate RTO/RPO targets và đưa ra recommendations
Resilience Hub scan architecture của bạn và liên tục track xem bạn có đang meet RTO/RPO targets đã định không — rất hữu ích để đảm bảo DR không bị "mục rữa" theo thời gian.
Cloud Exam Pro đang dùng chiến lược gì
CloudExam.pro là hệ thống luyện thi chứng chỉ AWS chạy trên AWS với sơ đồ kiến trúc như bên dưới:
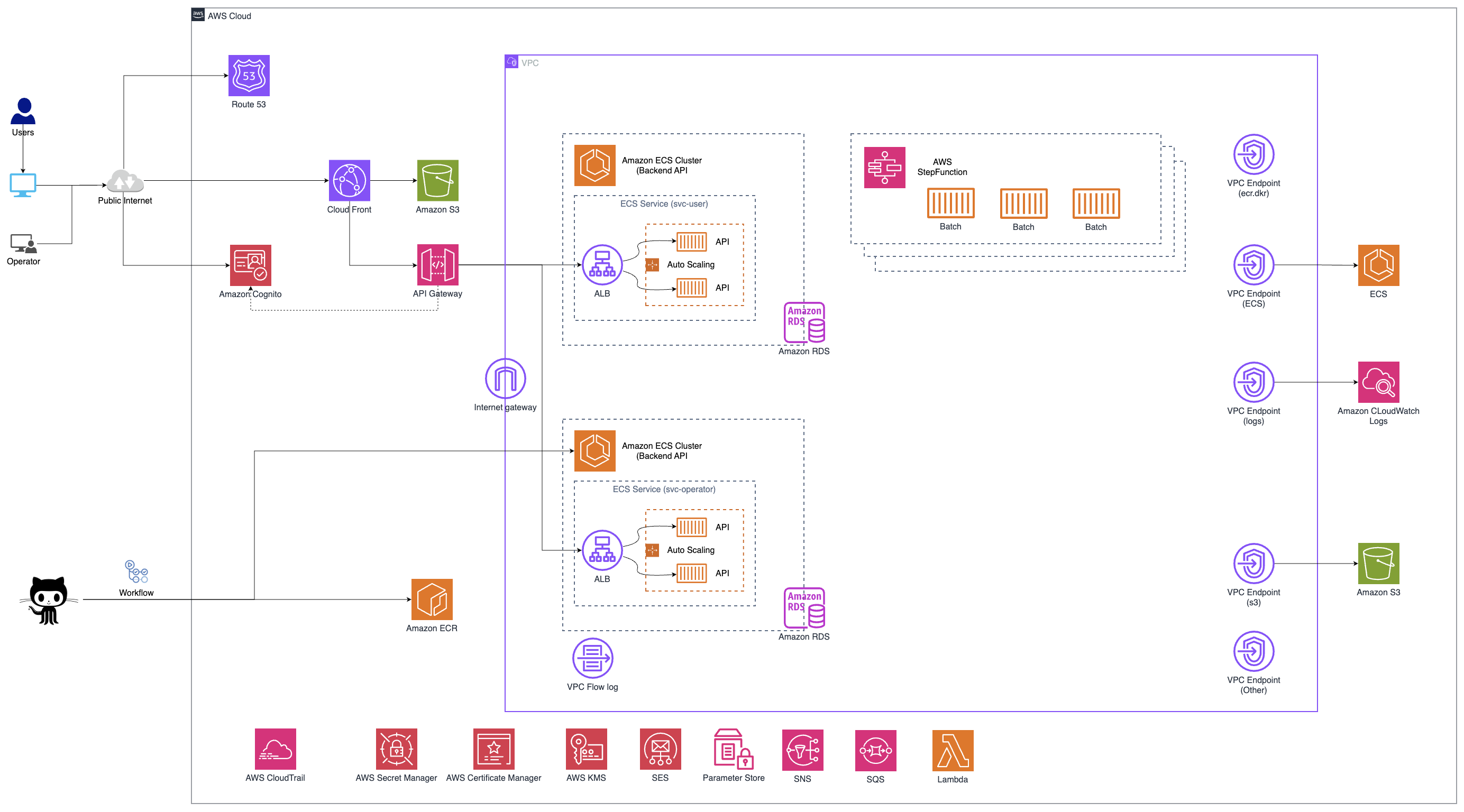
Hạ tầng đặt tại Region Singapore với lý do
- Giảm độ trễ đến User (chủ yếu tại Việt Nam)
- Hạ tầng ổn định (Không ảnh hưởng nhiều bởi thiên tai như động đất, sóng thần v.v và cũng ổn định về mặt chính trị)
- Phục vụ hầu hết các Service AWS hiện có
Bảo vệ dữ liệu
Dữ liệu của hệ thống chủ yếu nằm ở S3 và RDS
- S3 Standard lưu dữ liệu trên ít nhất 3 Availability Zones
- RDS sử dụng Automatic backup
RDS automated backup gồm hai phần:
- Daily snapshot — chụp 1 lần/ngày trong backup window
- Transaction logs — backup mỗi 5 phút liên tục
Kết hợp lại, RDS hỗ trợ point-in-time recovery đến bất kỳ giây nào trong retention period. Trong trường hợp xấu nhất (thảm hoạ xảy ra ngay trước lần log backup tiếp theo), bạn mất tối đa 5 phút dữ liệu.
→ RPO thực tế của RDS automated backup ≈ 5 phút
Điều gì xảy ra nếu Region Singapore sập
- Cloud Exam Pro có thể dựng lại toàn bộ hệ thống trong vòng 1 ngày. Hầu hết hạ tầng sử dụng IaC (CloudFormation)
- Dữ liệu bị mất hoàn toàn (S3 và Database)
Action nên làm
- Sử dụng S3 cross region replication để copy data trên S3 sang 1 region khác
- Sử dụng AWS Backup để backup cho RDS và copy 1 bản snapshot định kỳ sang Region khác.
Cloud Exam Pro không phải là hệ thống quá quan trọng, nên có thể chấp nhận down time 1 ngày trong trường hợp Region Singapore sụp đổ. Tuy nhiên khả năng này cực kỳ hiếm xảy ra. Mình sẽ cân nhắc vấn đề chi phí, RPO, RTO để đưa ra chiến lược phù hợp.
Kết Luận
Chọn DR strategy không phải là bài toán kỹ thuật thuần túy — nó là bài toán kinh doanh. Hãy bắt đầu bằng câu hỏi:
- Nếu hệ thống down X giờ, thiệt hại tài chính/uy tín là bao nhiêu? → Xác định RTO mục tiêu
- Nếu mất Y giờ dữ liệu, hậu quả là gì? → Xác định RPO mục tiêu
- Budget cho DR là bao nhiêu? → Chọn strategy phù hợp
Sau đó mới đến thiết kế kỹ thuật.
Một lộ trình thực tế cho nhiều teams:
- Bước 1: Đảm bảo Multi-AZ cho tất cả production workloads (non-negotiable)
- Bước 2: Setup Backup & Restore cross-region + IaC với CloudFormation/CDK
- Bước 3: Upgrade lên Pilot Light khi business phát triển và RTO cần giảm
- Bước 4: Evaluate Warm Standby hoặc Active/Active khi revenue impact của downtime đủ lớn để justify chi phí
Không có một "đúng" hay "sai" — chỉ có đúng cho workload của bạn.
Về tác giả: Mình là Phong — Cloud Solutions Architect với hơn 5 năm kinh nghiệm thiết kế hạ tầng cloud cho khách hàng doanh nghiệp. Founder của CloudExam.pro — nền tảng luyện thi AWS certifications hiệu quả cho người Việt.
Tham khảo: