
Building a Recommender System Integrate Generative AI for the Marketing Industry
Câu chuyện khách hàng:
T là một tập đoàn kinh doanh về mảng điện, gas và bán các thiết bị điện gia dụng,.. lớn nhất ở Kansai, Japan. Họ muốn build một hệ thống đề xuất thông minh như các sàn thương mại đt như tiktok, shoppe, amazon… Yêu cầu có thể đề xuất real-time để tăng trải nghiệm người dùng, đối với các người dùng không đăng kí tài khoản cũng có thể sử dụng. Khách hàng không muốn quan tâm, quản lí về mặt hạ tầng ứng dụng, mã nguồn blabla… Họ chỉ tập trung về chiến lược kinh doanh bán hàng. Hệ thống có thể scale up-down linh hoạt trong các big sale event, release sản phẩm mới.
Tổng quan hệ thống:
- Hạ tầng triển khai trên môi trường AWS, multi-region, multi-AZ, sử dụng ControlTower quản lý account doanh nghiệp.
- Front-end: dùng ReactJS để build UI web/app tích hợp với Amazon Amplify.
- Back-end: dùng Java Spring code logic API, build thành các images, push image lên ECR và deploy với ECS Fargate. Tích hợp auto scales dựa trên chỉ số CPU từ A đến Z.
- Data/Machine learning: sử dụng combo AWS Personalize + Databrew của AWS.
Quy trình triển giải pháp Machine Learning bao gồm 5 bước:
Bước 1: Gathering data/Data collection: chia làm 3 bộ dữ liệu chính
- UserEvent/ Interactions: thu thập dữ liệu tương tác của người dùng (lượt xem sản phẩm, lượt nhấp vào sản phẩm, lượt mua sản phẩm, thêm vào giỏ hàng…); bộ dữ liệu này có vai trò cực kì quan trọng trong việc bán hàng, đặc biệt là lĩnh vực thương mại điện tử.
- Thông qua các thư viện js “Click Stream Events” trên web/app -> Dữ liệu gửi lên thông qua API Gateway -> Đưa vào Kinesis Data Streams -> Kinesis Data Firehouse -> Cuối cùng lưu trữ S3
- Item metadata: thông tin chi tiết về sản phẩm (tên sp, mô tả, giá, phân loại, hình ảnh,…)
- export từ db RDS -> file csv
- User metadata: thông tin cá nhân của người dùng (tên, tuổi, mail, location,… )
- export từ db RDS -> file csv
Bước 2: Data pre-processing:
- Sử dụng AWS Databrew (visual data preparation tool, over 250 pre-built transformations, all without code) thực hiện ETL dữ liệu, loại bỏ các giá trị empty, duplicate, reformat data (string -> int, long,…). => Nhanh, gọn, lẹ khỏi phải viết code python.
- Phân tích data tạo biểu đồ dựa vào số liệu, export pdf & share data cho các bác Nhật review.
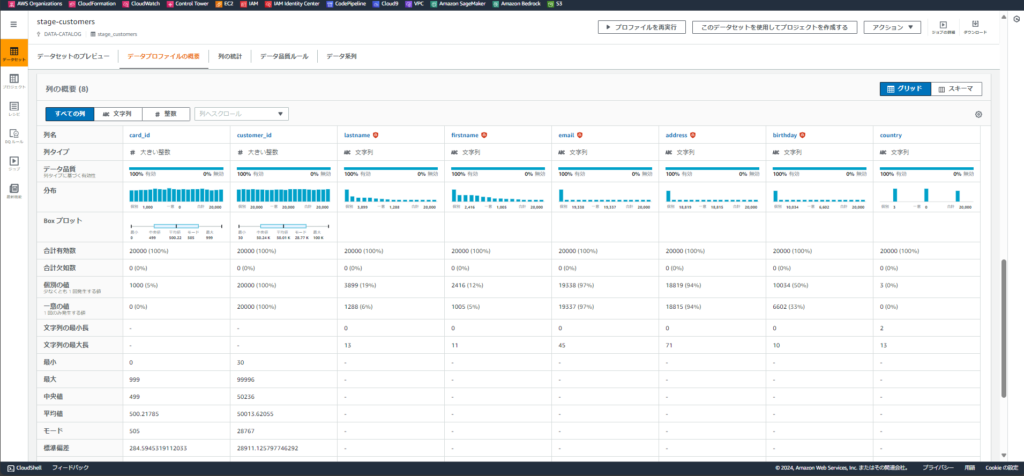
Sau khi ETL, datasets sẽ được lưu multi-region ở AWS S3, bật S3 versioning và sử dụng KMS mã hóa dữ liệu theo best practice của AWS. Tích hợp S3 lifecycle để tiết kiệm chi phí.
Bước 3: Xây dựng mô hình & huấn luyện mô hình (Model training) với AWS Personalize
Sau khi import datasets vào Personalize, Amazon Personalize cung cấp các công thức (recipes), là các thuật toán được thiết kế sẵn để giải quyết các use-case người dùng.
Hệ thống sử dụng 4 thuật toán built-in tương ứng với 4 model cho từng use-case của khách hàng:
- USER_PERSONALIZATION: đề xuất các sản phẩm/dịch vụ cho người dùng từ danh mục sp, được sử dụng ở homepage, để tăng tính cá nhân hóa trải nghiệm người dùng.
- Ví dụ: Khi người dùng đăng nhập lần 2-3, trang chủ sẽ ưu tiên hiển thị các sản phẩm phù hợp với sở thích của user dựa trên lịch sử tương tác trước đó.
- Thuật toán sử dụng: HRNN (Hierarchical Recurrent Neural Network): thiết kế để xử lý dữ liệu lịch sử người dùng có thứ tự theo thời gian, sử dụng các mạng nơ-ron hồi tiếp (Recurrent Neural Networks – RNNs) để dự đoán hành vi của người dùng dựa trên chuỗi tương tác trước đó.
- RELATED_ITEM: gợi ý các sản phẩm tương đồng với sản phẩm đang xem (apply detail page)
- Ví dụ: Nếu khách hàng thường mua các bếp điện, hệ thống sẽ đề xuất các bếp điện mới, bếp gas,…cùng loại mà người dùng chưa xem.
- Thuật toán sử dụng: Cosine Similarity: phương pháp phổ biến để đo lường độ tương đồng giữa hai vectơ; vectơ thường biểu diễn các mục dựa trên các đặc trưng của chúng. Cosine Similarity là một giá trị từ -1 (hoàn toàn không tương đồng) đến 1 (hoàn toàn tương đồng), với 0 thể hiện sự độc lập.
- PERSONALIZED_RANKING: Xếp hạng danh sách các sp đề xuất cho user khi user tìm kiếm một sản phẩm bất kì dựa trên lượt đánh giá/tương tác.
- Ví dụ: Khi user tìm kiếm 1 chiếc bếp điện, thì hệ thống sẽ sắp xếp và đề xuất danh sách sản phẩm dựa trên lượt đánh giá/bình chọn (1 sao -> 5 sao)
- USER_SEGMENTATION: phân khúc khách hàng, là quá trình chia nhỏ đối tượng khách hàng thành các nhóm nhỏ dựa trên các đặc điểm như nhân khẩu học, hành vi mua sắm và tâm lý khách hàng.
- Ví dụ: Phân khúc người dùng gồm 3 nhóm:
- Nhóm 1: Người dùng thường xuyên mua sản phẩm điện tử.
- Nhóm 2: Người dùng quan tâm đến bộ chăm sóc y tế.
- Nhóm 3: Người dùng chưa từng thực hiện mua hàng nhưng có lịch sử xem sản phẩm nhiều lần.
- Chiến lược kinh doanh, marketing và quảng cáo:
- Gửi email với ưu đãi giảm giá (5,10,15%) cho Nhóm 1 về các sản phẩm điện tử mới sản xuất.
- Hiển thị quảng cáo trên mạng xã hội, phát tờ rơi cho Nhóm 2.
- Cung cấp phiếu giảm giá sâu,event lớn, voucher freeship cho Nhóm 3 để khuyến khích mua hàng.
- Thuật toán sử dụng: K-Nearest Neighbors (kNN): Hoạt động bằng cách nhóm các điểm dữ liệu liên quan sử dụng thuật toán Unsupervised Learning (Học không giám sát) sẽ dựa vào cấu trúc của dữ liệu để thực hiện phân nhóm (clustering).
- Ví dụ: Phân khúc người dùng gồm 3 nhóm:
Sau khi training model thành công được gọi là Solution (Trained Model), mỗi Solution nhiều version.
Event Tracker trong AWS Personalize tính năng đề xuất items dựa trên các sự kiện từ user theo thời gian thực (real-time events) và liên kết với tập dữ liệu dataset dùng để train model.
Luồng xử lý của Event Tracker trong AWS Personalize
- Từ Font-end, các hoạt động của người dùng (click xem sp, thêm vào giỏ hàng, hoàn tất thanh toán, tìm kiếm…) được gửi đến Amazon Kinesis Data Stream, bao gồm các thông tin chính như UserID, ItemID, EventType, TimeAction.
- Sử dụng Lambda function, viết code convert data từ Kinesis Data Streams đúng format của Personalize Event Tracker và ghi data vào Event Tracker (sử dụng PutEvents API).
- Event Tracker phản ánh các bản cập nhật theo thời gian thực, nó cung cấp một API Endpoint để gọi đến các model đã training.
- Ví dụ: User input ( view item A, EventType: View, UserID: 123456 => ngay lập tức danh sách recommend các sản phẩm tương đồng với itemA được hiển thị).
Có 1 điểm rất hay khi sử dụng EventTracker với thuật toán USER_PERSONALIZATION, Amazon Personalize sẽ auto re-training sau mỗi 2h nếu một item (sp) không được thêm vào dataset group được liên kết với Event Tracker. Các item vừa được thêm vào sau khi re-training kết thúc sẽ được phản ánh trong kết quả đề xuất.
- Ví dụ: Danh sách data items lúc đem đi training có 100 sản phẩm, sau 1 tuần thì phát hành thêm 10 sản phẩm mới. (giải pháp truyền thống là phải tự đi export data và training lại, nâng cấp revision) Với Event Tracker, hệ thống sẽ tự kiểm tra nếu 10 sản phẩm mới không nằm trong tệp dataset được liên kết với Event Tracker. Sau 2h, model sẽ tự động được đào tạo lại, và sản phẩm đó sẽ được đưa vào trong danh sách gợi ý ngay lập tức. (không bị tính phí re-training và không phải thực hiện training manual)
- Đối với các thuật toán khác, không tự động cập nhật mô hình dữ liệu. Trong trường hợp này, cần huấn luyện lại (re-training) mô hình để phản ánh các item trong kết quả gợi ý.
Khi có người dùng mới (new user):
- Nếu một người dùng mới được thêm vào mô hình huấn luyện gần nhất, kết quả gợi ý ban đầu sẽ dựa vào mục mà người đó tương tác nhiều nhất.
- Càng nhiều dữ liệu tương tác từ người dùng mới, gợi ý sẽ càng chính xác.
Đối với người dùng ẩn danh (anonymous users):
- Người dùng ẩn danh (không có UserId trong mô hình) sẽ được theo dõi dựa trên sessionId (ID phiên làm việc). Sau khi người dùng đăng ký và đăng nhập, gợi ý sẽ được chuyển sang dựa trên UserId thay vì sessionId.
- Điều này cho phép hệ thống tiếp tục đưa ra gợi ý ngay cả khi người dùng sử dụng ứng dụng ở chế độ ẩn danh.
Bước 4: Đánh giá mô hình (Model evaluation) + Deploy model
Model evaluation: chia làm 2 phần
Phần 1: Đánh giá dựa trên chỉ số model

F1 Score
- Giá trị: 1.000
- Ý nghĩa: F1 score là trung bình điều hòa của độ chính xác (precision) và độ nhạy (recall). Giá trị 1.000 có nghĩa là mô hình đạt hiệu suất hoàn hảo trong việc đưa ra các recommend sản phẩm, phân khúc người dùng, phân loại sản phẩm theo cụm đặc trưng ( dựa trên lịch sử người dùng đã tương tác), không có sai sót nào. Công thức tính F1 score:
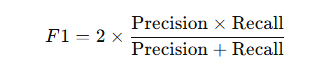
- Nếu F1 score = 1.000, điều này cho thấy mô hình có cả precision và recall đạt mức tối đa (1.000).
Phần 2: Đánh giá từ 1 bộ hơn 300 TC từ khách hàng định nghĩa. (test chạy bằng cơm)
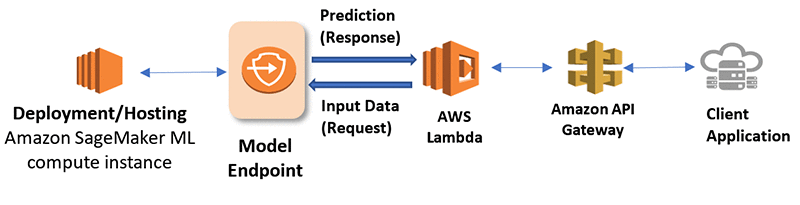
Deploy model: Sau khi model được deploy trên SageMakerEndpoint của AWS thì user/application có thể invoke API endpoint để lấy kết quả.
- Client -> API Gateway -> sử dụng lambda để invoke SageMaker Endpoint API
Bước 5: Monitor Model
- Log sẽ được lưu trữ và gửi từ CloudWatch đến Grafana được host trên EC2 để tạo Dashboard theo dõi hiệu suất Model và số lượng yêu cầu API.
Sau khi GenerativeAI bùng nổ 2023-2024, nó như làn một gió mát thổi vào sa mạc khô cằn, vì thế nhu cầu sử dụng GenAI tạo ra cho ngành quảng cáo và tiếp thị (Advertising and Marketing Industry) ngày càng được ưu chuộng.
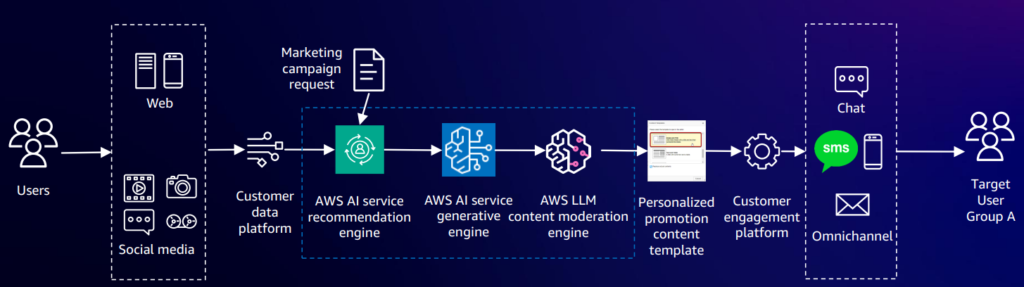
Nắm bắt được tâm sinh lí của khách hàng Nhật Bổn, bên nhà F*** đề xuất với khách hàng cho ra đời giải pháp GenAI tích hợp với hệ thống đề xuất Personalize; mục đích để tạo nội dung quảng cáo (ad copy) tự động dựa trên hình ảnh sản phẩm từ DB, thông tin về sản phẩm/dịch vụ và đối tượng/mục tiêu của chiến dịch quảng cáo. (đã được xử lý và thu thập ở mục USER_SEGMENTATION phân khúc khách hàng).
- Người dùng cung cấp dữ liệu đầu vào.
- Chọn hình ảnh sản phẩm muốn quảng cáo, hình ảnh được lưu trong S3.
- Chọn loại dịch vụ quảng cáo (Mail Marketing/SMS/WebContent/Post SNS…)
- Đối tượng mục tiêu (nhóm người dùng đưuọc phân khúc từ Amazon Personalize)
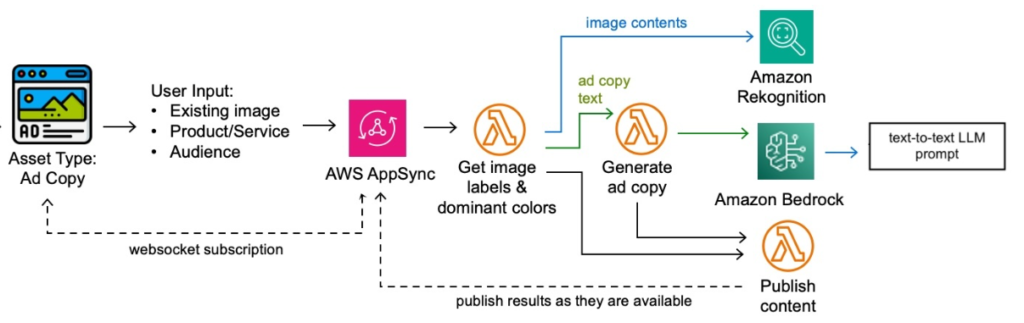
- AWS AppSync có thể dễ dàng xây dựng các API GraphQL mà không cần quản lý cơ sở hạ tầng.
- Dữ liệu đầu vào từ người dùng được gửi đến hệ thống qua AWS AppSync, thông qua kết nối websocket subscription, cho phép cập nhật kết quả theo thời gian thực khi xử lý dữ liệu.
- Xử lý hình ảnh bằng Amazon Rekognition:
- Hình ảnh quảng cáo được gửi đến Amazon Rekognition, một dịch vụ phân tích các đối tượng, cảnh vật, và ngữ cảnh trong hình ảnh của AWS.
- Rekognition phân tích để xác định: + Các nhãn hình ảnh (image labels). + Màu sắc chủ đạo (dominant colors) trong hình ảnh. => Điều này giúp hệ thống hiểu được nội dung của hình ảnh (ví dụ: ảnh có hoa, người chạy bộ, thức ăn, v.v.) và sử dụng thông tin này để tạo ra nội dung quảng cáo chính xác và có ý nghĩa.
- Tạo nội dung quảng cáo (Ad Copy) bằng Amazon Bedrock với LLM Titan Image Generator G1 v2.
- Sau khi nhận dữ liệu phân tích hình ảnh, thông tin sản phẩm/dịch vụ và đối tượng mục tiêu được kết hợp để tạo prompt (lời nhắc) cho mô hình ngôn ngữ (LLM).
- Amazon Bedrock, nền tảng xử lý mô hình ngôn ngữ AI của AWS, được sử dụng để tạo nội dung quảng cáo tự động dựa trên prompt.
- Kết quả được xuất bản:
- Nội dung quảng cáo được tạo ra sẽ được gửi về phía người dùng qua AWS AppSync, lưu nội dung vào hệ thống chiến dịch để quảng cáo.
Mở rộng: Có thể phát triển thêm tính năng “switch models” ( tự do chuyển đổi giữa các model hàng đầu của OpenAI, IBM, AWS,… mô hình giá càng cao chất lượng output cho ra sản phẩm càng tốt ), mỗi model đã được training data riêng biệt, vì thế nó sẽ có 1 cách "thể hiện riêng", sẽ mang tính đột phá, thú vị.
Cùng chém gió xíu một vài lợi ích và hiệu quả mà hệ thống GenAI mang lại:
- Tự động hóa quy trình: Thay vì sử dụng nội dung thuần text, hệ thống tạo ra nội dung quảng cáo bao gồm hình ảnh/text/màu sắc phù hợp và chính xác hơn.
- Tối ưu chi phí và thời gian: để làm ra 1 bài pr/video về sản phẩm mới thì cần có sự hợp tác designer/copywriter/martketing... + thời gian tối thiểu 1 tuần cho khâu lên ý tưởng/thiết kế/phát triển/đánh giá. Còn nếu dùng giải pháp genAI thì chỉ mất khoảng 1 ngày là có thể tạo ra cả 100 bài/video pr sản phẩm (dùng nhiều, trả tiền nhiều :)) nếu ko phù hợp có thể tải về máy tùy chỉnh lại, ko sợ vi phạm bản quyền).
- Bàn về cost thì tiền nuôi team designer/copywriter/martketing chắc chắn lớn hơn trả cho AWS. Nếu chiến dịch có hàng trăm sp thì thời gian release sản phẩm sẽ nhanh hơn rất rất nhiều nhưng vẫn "đảm bảo chất lượng" (nếu sử dụng các model hiện đại, tiên tiến), đó là cái mà doanh nghiệp quan tâm nhất trong kinh doanh.
- Sau khi ứng dụng giải pháp ML cho đề xuất sản phẩm + chiến lược phân khúc người dùng cho thị trường marketing, revenus trộm vía tăng trưởng gần 230% so với năm trước.