Giới thiệu tổng quan
- AWS experience: Advanced
- Time to complete: 90~120 minutes
- AWS Region: United States (N.Virginia)
- Cost to complete: ~5-8$ (Free Tier eligible)
- Services used: Amazon SageMaker AI
1. Chuẩn bị
Amazon SageMaker Studio là một môi trường phát triển tích hợp (IDE) dựa trên web cho phép bạn Build, Train, Debug, Deploy và Monitor các mô hình ML của mình. Studio cung cấp tất cả các công cụ bạn cần để đưa các model của mình từ thử nghiệm đến môi trường thực tế đồng thời nâng cao năng suất của bạn.
1.1 Tạo SageMaker Studio
Ở bước chuẩn bị này, chúng ta sẽ tiến hành khởi tạo Amazon SageMaker Studio.
- Đăng nhập vào AWS Management Console, chọn Region Singapore, sau đó tìm kiếm và truy cập dịch vụ Sage Maker AI.
- Ở tab bên trái: Chọn Admin configurations -> Domains -> Setup for single user (Quick setup). SageMaker Domain là kho lưu trữ trung tâm để quản lý cấu hình SageMaker cho tổ chức của bạn.
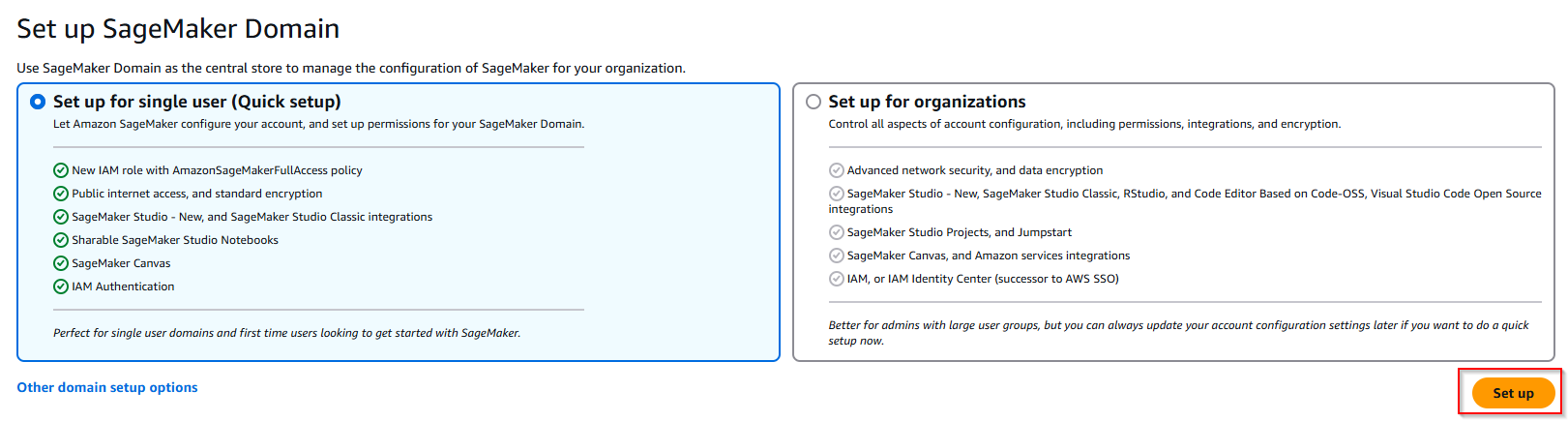
- Sau khi quá trình khởi tạo Sage Maker Studio hoàn tất, tiếp theo sẽ tạo User profiles.

- Nhập thông tin user profiles, Name: admin-workshopsagemaker, Execution role: chọn Create a new role -> Chọn option Any S3 bucket (Nếu đã có S3 bucket dùng để lưu dataset thì chọn Specific S3) -> Create role.


- Configure Application, giữ các giá trị mặc định. Chọn Next.

- Customize Studio UI, giữ các giá trị mặc định. Chọn Next.

- Data and storage settings, điền thông tin: Posix User(Uid): 1001 và Posix Group ID(Gid): 10000
- POSIX User ID (Uid): Đây là con số định danh duy nhất cho mỗi người dùng trong hệ thống Linux/Unix. Ví dụ,
1001 nghĩa là người dùng này sẽ có UID = 1001 trên các máy Linux, giúp phân biệt với các user khác. - POSIX Group ID (Gid): Tương tự như UID, GID là con số định danh cho một nhóm. Người dùng này sẽ thuộc về nhóm có GID =
10000. Các quyền (permission) trên hệ thống file Linux sẽ dựa trên UID/GID để cho phép (hoặc không cho phép) người dùng đọc, ghi, thực thi,… trên các file/thư mục.
- Review and submit

- Sau khi quá trình khởi tạo User hoàn tất , click Open Studio.

- Đây là giao diện khởi đầu của Sage Maker AI Studio :

- Tiếp theo, khởi tạo JupyterLab phục vụ cho việc chạy các đoạn code ML. Chọn Create JupyterLab space. Đặt tên là cmp-jupyterLab -> chọn option Share with my domain -> Create space.


- Chọn cấu hình để chạy Notebook. Instance type: ml.t3.medium để tiết kiệm chi phí trong bài thực hành. Chọn nút Run space.

- Sau khi instance được khởi tạo, chọn Open để truy cập vào môi trường Notebook. Lưu ý: AWS sẽ tính phí dựa trên thời gian sử dụng instance, nếu không có nhu cầu sử dụng thì hãy Stop.

1.2 Tải Github repo
- Đây là giao diện Notebook. Tiếp theo, tải file Notebook đã được chuẩn bị sẵn trong bài thực hành. Chọn mục Git -> Git clone

- Nhập thông tin repo chứa file notebook đã được chuẩn bị:
https://github.com/gautrucdethuong/numpy_xgboost_direct_marketing_sagemaker.git


- Bạn đã hoàn thành bước setup và chuẩn bị môi trường. Ở bước tiếp theo chúng ta sẽ tìm hiểu về Feature Engineering.
2. Feature Engineering
Trong phần này, bạn sẽ đảm nhận vai trò của một nhà phát triển ML làm việc tại một ngân hàng. Bạn đã được yêu cầu "phát triển một model ML để dự đoán liệu khách hàng có đăng ký chứng chỉ tiền gửi (CD)" hay không (CD là một hình thức đầu tư an toàn và có lợi suất cố định trong một khoảng thời gian nhất định, xem chi tiết ở đây), model sẽ được train về bộ dữ liệu tiếp thị chứa thông tin về nhân khẩu học của khách hàng.
Trong phần này, bạn sẽ tìm hiểu về phần được hightlight trong qui trình ML bên dưới:
- Chúng ta sẽ tập trung vào Feature Engineering và Visualization, tìm hiểu cách sử dụng Amazon SageMaker Data Wrangler để chuẩn bị data cho ML. Chúng ta cũng sẽ sử dụng Amazon SageMaker Feature để lưu trữ, sử dụng và chia sẻ các machine learning (ML) feature.

2.1 Chuẩn bị Dataset
Chuẩn bị Dataset và upload lên S3 bucket
- Kết nối tới địa chỉ sau trên trình duyệt của bạn và download dataset dưới đây để chuẩn bị cho bài lab.
https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip
- Giải nén và lưu vào máy tính của bạn.
- Vào giao diện AWS Management Console và truy cập vào dịch vụ S3.
- Bucket sagemaker-studio-xxx được tạo tự động khi bạn tạo SageMaker Studio domain trong phần chuẩn bị.
- Thực hiện Upload các file lên S3 bucket.

- Bạn đã hoàn thành bước upload dataset vào Amazon S3. Ở bước tiếp theo chúng ta sẽ cấu hình tính năng Data Wrangler.
2.2 Cài đặt Data Wrangler
- Quay trở lại SageMaker Studio. Tại menu bên trái , click vào Data Wrangler -> Chọn nút Run in Canvas.
- Workspace instance (Session-Hrs) charges: $1.9/hour. Chi tiết về giá tham khảo trang chủ AWS.
- Data processing charges

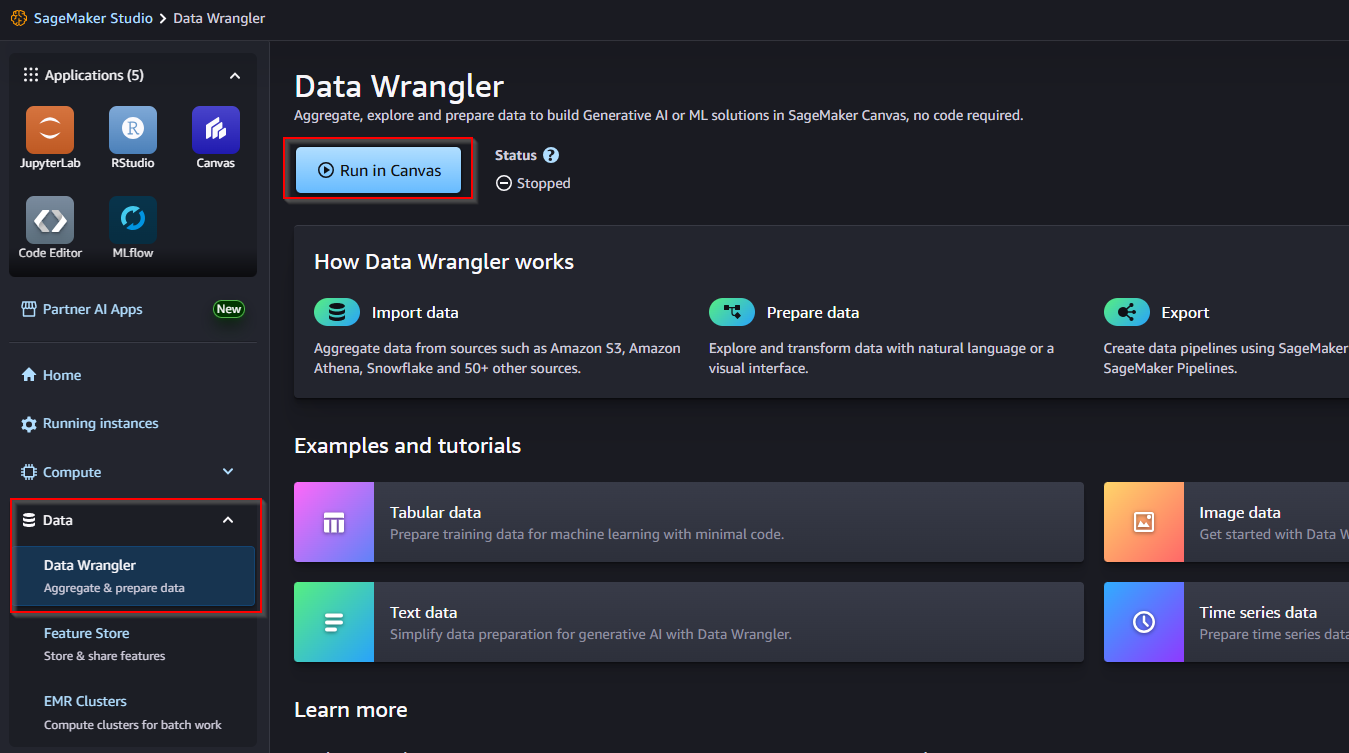
- Amazon SageMaker Data Wrangler là công cụ tiền xử lý dữ liệu cho workflow AI/ML, giảm thời gian chuẩn bị dữ liệu như clean file csv, hình ảnh và văn bản thời gian từ nhiều tuần xuống còn vài giờ. Với SageMaker Data Wrangler, bạn có thể đơn giản hóa việc chuẩn bị dữ liệu và thiết kế tính năng thông qua giao diện ngôn ngữ tự nhiên và trực quan. Nhanh chóng chọn, nhập và chuyển đổi dữ liệu bằng SQL và hơn 300+ phép chuyển đổi tích hợp mà không cần viết mã. Tạo báo cáo dữ liệu trực quan để phát hiện các bất thường trên các loại dữ liệu và ước tính hiệu suất mô hình. Mở rộng quy mô để xử lý hàng petabyte dữ liệu.

- Tiếp theo, thực hiện import data từ S3.
- Click Import and prepare ở giữa màn hình.
- Dataset type: chọn Tabular
- chọn file bank-additional-full.csv.

- Nhấn Next -> Click Import
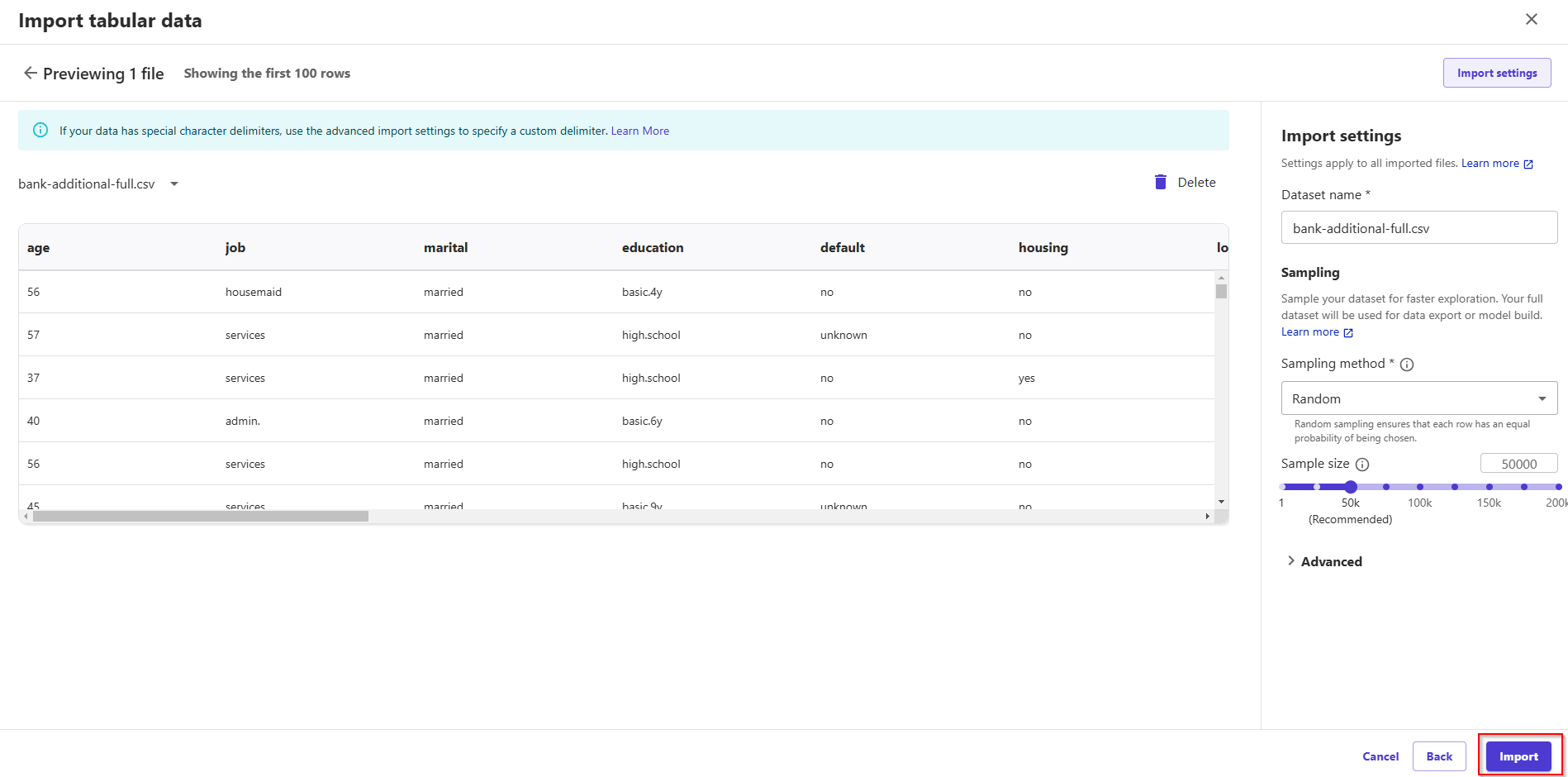
- Bạn đã hoàn thành bước tạo Data Wrangler Flow và Import Dataset từ S3. Bước tiếp theo chúng ta sẽ thực hiện một số phân tích cơ bản.
2.3 Phân tích Dataset
- Sau khi cấu hình import Dataset xong, chúng ta sẽ thấy Data Flow được biểu diễn như hình dưới.
- Trong Amazon SageMaker Data Wrangler, Data Flow (hoặc Data Wrangler Flow) là một luồng thao tác (data pipeline) giúp bạn:
- Nạp dữ liệu (import data) từ nhiều nguồn (S3, Redshift, Athena, v.v.).
- Biến đổi (transform) dữ liệu theo từng bước (operator) trong một giao diện trực quan.
- Xem trước và đánh giá kết quả biến đổi qua các bước (bạn có thể lọc, gộp cột, chuyển đổi kiểu dữ liệu, áp dụng hàm thống kê, chuẩn hoá text, v.v.).
- Xuất dữ liệu ra S3, feature store, hoặc dùng ngay trong các quy trình huấn luyện (training) và dự đoán (inference).

- Click tab Data, bạn sẽ có cái nhìn tổng quan về tập dữ liệu với tên và loại cột:

- Thông tin chi tiết của các features được mô tả dưới đây:
Thông tin cá nhân
- age : Tuổi khách hàng (numeric)
- job : Nghành nghề ( Chia theo nhóm : ‘admin.’, ‘services’, …)
- marital : Tình trạng hôn nhân ( Chia theo nhóm : ‘married’, ‘single’, …)
- education : Tình trạng học vấn ( Chia theo nhóm : ‘basic.4y’, ‘high.school’, …)
Sự kiện khách hàng
- default : Có sử dụng credit hay không ? ( Chia theo nhóm: ‘no’, ‘unknown’, …)
- housing : Có vay mua nhà không ? ( Chia theo nhóm: ‘no’, ‘yes’, …)
- loan : Có khoản vay cá nhân không ? ( Chia theo nhóm: ‘no’, ‘yes’, …)
Thông tin liên lạc phục vụ marketing
- contact : Phương thức liên lạc ( Chia theo nhóm: ‘cellular’, ‘telephone’, …)
- month : Tháng liên lạc lần cuối trong năm ( Chia theo nhóm: ‘may’, ‘nov’, …)
- day_of_week : Ngày liên lạc lần cuối trong tuần ( Chia theo nhóm: ‘mon’, ‘fri’, …)
- duration : Thời gian lần liên lạc cuối, theo giây(numeric). Ghi chú quan trọng: Nếu duration = 0 thì y = ‘no’.
Thông tin chương trình
- campaign : Số lượng liên lạc thực hiện trong campaign (chương trình )với khách hàng (numeric, kèm lần liên lạc cuối)
- pdays : Số ngày đã qua từ khi khách hàng liên lạc lần cuối từ một chương trình trước. (numeric)
- previous : Số lần liên lạc thực hiện trước chương trình với khách hàng.(numeric)
- poutcome : Kết quả của chương trình marketing. ( Chia theo nhóm: ‘nonexistent’,‘success’, …)
Yếu tố tác động bên ngoài.
- emp.var.rate : Tỷ lệ thay đổi việc làm - chỉ số hàng quý (numeric)
- cons.price.idx : Chỉ số giá tiêu dùng - chỉ số hàng tháng (numeric)
- cons.conf.idx : Chỉ số niềm tin người tiêu dùng - chỉ số hàng tháng (numeric)
- euribor3m : Lãi suất Euribor 3 tháng - chỉ báo hàng ngày (numeric)
- nr.employed : Số lượng nhân viên - chỉ số hàng quý (numeric)
Biến mục tiêu.
- y : Khách hàng có gửi tiền theo kỳ hạn không ?(binary: ‘yes’,‘no’)
2.4 Phân tích tương quan giữa feature và biến số mục tiêu
- Trước khi phân tích sự tương quan của dữ liệu, chúng ta hãy tạo bảng báo cáo phân tích chi tiết tổng quan của dữ liệu đã import.
Click dấu + , chọn option Get data insights. Nhập name là BankingDataDetails -> Click Create.

Chọn loại Instance type: ml.m5.4xlarge để chạy processing job.

Processing Jobs chạy được phản ánh qua SageMaker Console. Có thể monitor job trong quá trình chạy.

Sao khi Job chạy hoàn thành, Data Wrangler cung cấp cho chúng ta 1 bản báo cáo chi tiết về dữ liệu dataset hiện tại. Douple click vào icon Data Quality And Insights Report để xem chi tiết:
Ví dụ:
- Number of features: 21
- Number of rows: 41188
- Missing: 0%
- Valid: 100%
- Duplicate rows: 0.0583%


- Tiếp theo, thực hiện phân tích sự tương quan giữa feature Tuổi và biến mục tiêu y.
- Click tab Analyses.
- Analysis type: Histogram.
- Analytics name: đặt tên là Age.
- Click chọn cột age tại mục X asis.
- Click chọn cột y tại mục Color by.
- Click Preview để xem analysis. Bạn sẽ thấy biểu đồ trực quan về mối tương quan của feature Tuổi của một người lên biến mục tiêu y.
- Click Update để lưu thông tin analysis.

📌Giải thích sơ qua về biểu đồ:
X axis (age):
- Trục hoành hiển thị độ tuổi từ 10-100
- Dữ liệu được chia thành các khoảng tuổi (bins) để tạo histogram
Color by (Y):
- Phân chia dữ liệu theo biến mục tiêu Y với 2 giá trị:
- Màu xanh (no): Nhóm có giá trị Y = "no"
- Màu cam (yes): Nhóm có giá trị Y = "yes"
Mục đích phân tích: Biểu đồ này giúp visualize mối quan hệ giữa độ tuổi và biến mục tiêu Y, cho phép:
- Xem phân bố độ tuổi của từng nhóm (yes/no)
- Nhận biết xu hướng: nhóm "yes" tăng dần theo độ tuổi, đặc biệt từ 30-50 tuổi. Phần lớn dữ liệu tập trung ở độ tuổi 30-40, với đỉnh cao nhất khoảng 35 tuổi (gần 17,000 bản ghi)
- Đánh giá độ tuổi có phải là yếu tố quan trọng để dự đoán biến Y hay không
- Thực hiện tương tự để tạo anlysis tương quan giữa ngành nghề và biến mục tiêu y. Nhấn vào icon dấu + để tạo thêm trang phân tích. Nhập các thông tin như trong ảnh

📌Giải thích sơ qua về biểu đồ: Biểu đồ histogram này phân tích mối quan hệ giữa nghề nghiệp (Job) và biến mục tiêu Y:
Phân bố nghề nghiệp:
- Admin: Chiếm đa số (~10,500 người), với tỷ lệ "yes" (màu cam) khá thấp
- Blue-collar: Nhóm thứ 2 (~9,000 người), tỷ lệ "yes" rất thấp
- Technician: Khoảng 6,500 người, tỷ lệ "yes" thấp
- Services: ~4,000 người
- Management: ~3,000 người, có tỷ lệ "yes" cao hơn các nhóm khác
Nhận xét quan trọng:
- Retired (hưu trí): Mặc dù số lượng ít (~1,000 người) nhưng có tỷ lệ "yes" cao nhất (khoảng 25-30%)
- Student (sinh viên): Cũng có tỷ lệ "yes" tương đối cao
- Các nghề nghiệp khác có tỷ lệ "yes" khá thấp và đồng đều
Ý nghĩa: Nghề nghiệp có ảnh hưởng rõ rệt đến biến mục tiêu Y. Đặc biệt, người hưu trí và sinh viên có xu hướng "yes" cao hơn, có thể do:
- Có nhiều thời gian rảnh hơn
- Ít áp lực tài chính từ công việc
- Nhu cầu và hành vi khác biệt so với nhóm đang làm việc
Đây là feature quan trọng cho mô hình dự đoán.
- Thực hiện tương tự để tạo anlysis tương quan giữa tình trạng hôn nhân và biến mục tiêu y.
- Analysis tương quan theo tình trạng hôn nhân.

- Bạn đã hoàn thành tạo các phân tích tương quan giữa các feature và biến mục tiêu. Khi bạn thực hiện phân tích tương quan (correlation) giữa các biến đầu vào (features) và biến mục tiêu (target), mục đích chính là để:
- Xác định mức độ liên hệ giữa từng đặc trưng (feature) với biến mục tiêu, từ đó thấy được biến nào có đóng góp/ảnh hưởng lớn đến kết quả dự đoán.
- Phát hiện hiện tượng đa cộng tuyến (multicollinearity). Nếu hai hoặc nhiều feature có tương quan quá cao với nhau, việc giữ tất cả những feature này đôi khi có thể gây nhiễu mô hình hoặc làm mô hình bị overfit.
- Hỗ trợ lựa chọn đặc trưng (feature selection). Dựa vào mức độ tương quan, bạn có thể:
- Loại bớt các feature ít tương quan hoặc trùng lặp thông tin.
- Tập trung vào những feature thật sự quan trọng, giúp mô hình gọn nhẹ hơn.
- Bước tiếp theo, chúng ta sẽ thực hiện chuyển đổi dữ liệu.
2.5 Chuyển đổi dữ liệu
Làm sạch dữ liệu là một phần quan trọng nhất của hầu hết mọi dự án Machine Learning. Nó được cho là mang lại rủi ro lớn nhất nếu thực hiện không đúng cách, chất lượng model sẽ phụ thuộc vào ~70% dữ liệu đầu vào.
Chúng ta sẽ cùng thực hiện một vài chuyển đổi tùy chỉnh có chứa một số lệnh Python Pandas thực hiện các việc sau.
- Click tab Data -> Chọn nút Add transform.

- Click Custom Transform, sau đó click chọn Python (Pandas).

import time
import pandas as pd
# Change the value . into _
df = df.replace(regex=r'\.', value='_') # Thay dấu '.' thành '_'
df = df.replace(regex=r'\_$', value='') # Xóa dấu '_' ở cuối string
# Add two new indicators
df["no_previous_contact"] = (df["pdays"] == 999).astype(int)
df["not_working"] = df["job"].isin(["student", "retired", "unemployed"]).astype(int)
# Add unique ID and event time for features store
df['FS_ID'] = df.index + 1000 # Tạo unique ID (bắt đầu từ 1000)
current_time_sec = int(round(time.time())) # Thêm timestamp hiện tại
df['FS_time'] = pd.Series([current_time_sec]*len(df), dtype="float64")
- Click Preview.
- Click Add.

Giải thích qua đoạn code trên dùng để thực hiện data preprocessing (trường hợp này demo sử dụng custom code làm chuyển đổi dữ liệu) và feature engineering:
Data Cleaning:
df = df.replace(regex=r'\.', value='_') # Thay dấu '.' thành '_'
df = df.replace(regex=r'\_$', value='') # Xóa dấu '_' ở cuối string
Feature Engineering - Tạo 2 biến mới:
a. no_previous_contact:
- Kiểm tra nếu
pdays == 999 (không liên hệ trước đó) - Chuyển thành binary indicator (0/1)
b. not_working:
- Kiểm tra nếu nghề nghiệp thuộc nhóm không làm việc: "student", "retired", "unemployed"
- Chuyển thành binary indicator (0/1)
Mục đích:
- Làm sạch dữ liệu và tạo features mới có ý nghĩa
- Chuẩn bị dữ liệu cho hệ thống Feature Store
- Biến
not_working phù hợp với phân tích histogram trước đó (retired, student có tỷ lệ "yes" cao)
Kết quả sau khi apply đoạn code trên
- Bước tiếp theo chúng ta sẽ xóa feature duration khỏi Dataset (feature không quan trọng) vì chúng cần được dự báo với độ chính xác cao để sử dụng làm dữ liệu đầu vào cho các dự đoán trong tương lai. ( Ở bước này chúng ta sẽ sử dụng các hàm built-in SageMaker Wrangler hỗ trợ)
- Click Add transform
- Click Manage Column.
- Click chọn Drop column.
- Click chọn cột duration.
- Click Preview để xem trước dữ liệu.
- Click Add để thêm bước biến đổi vào data flow.

- Chúng ta sẽ làm tương tự bước trên để loại bỏ năm cột sau đây (các feature không quan trọng) và thêm các bước chuyển đổi đó vào data flow.
- emp.var.rate
- cons.price.idx
- cons.conf.idx
- euribor3m
- nr.employed

- Tiếp theo chúng ta sẽ thực hiện Encoding data với các biến phân loại để chuyển đổi các biến phân loại thành tập hợp các chỉ số.
- Encoding data là một trong những bước xử lí data trước khi trở thành input cho các machine learning model. Về cơ bản thì machine learning cần làm các phép tính, nếu data dạng số thì không vấn đề gì, nhưng nếu data ở dạng chữ (categorical data) thì không thể làm được như vậy. Chính vì thế, giải pháp là encoding.

- Chúng ta sẽ sử dụng tính năng Encode Categorical của Data Wrangler để thực hiện việc biến đổi.
- Click chọn Ordinal encode. (tìm hiểu thêm các loại encode tại đây)
- Click chọn cột job.
- Click Preview.
- Click Add để thêm biến đổi vào luồng dữ liệu.

- Chúng ta có thể sử dụng cùng một phương pháp cho phần còn lại của các cột phân loại sử dụng Custom Transform để thực hiện encoding cho tất cả các cột phân loại trong một bước bằng cách sử dụng Custom Transform với Python (Pandas).
- Click Custom Transformation.
- Click chọn Python (Pandas).
- Sử dụng đoạn mã dưới đây.
import pandas as pd
df=pd.get_dummies(df)
- Click Preview để xem trước.
- Click Add để thêm biến đổi vào luồng dữ liệu.

- Bạn đã hoàn thành thêm các bước chuyển đổi dữ liệu vào dataflow. Bước tiếp theo chúng ta sẽ thực hiện export các feature vào SageMaker feature store.
2.6 Feature Store
SageMaker Feature Store là một kho quản lý và lưu trữ các biến đầu vào (features) được sử dụng trong mô hình machine learning (ML). Thay vì mỗi đội nhóm hoặc mỗi lần huấn luyện mô hình lại tạo và lưu riêng các features, Feature Store cho phép:
- Tạo kho lưu trữ tập trung (Centralized Store): Bạn định nghĩa “Feature Group” – một dạng bảng chứa các cột (features) và dòng (bản ghi dữ liệu). Tất cả mô hình hoặc pipeline có thể truy cập tập trung thay vì phải tự làm lại từng bước tiền xử lý.
- Tách biệt môi trường Online và Offline:
- Online Store: phục vụ các yêu cầu suy luận (inference) theo thời gian thực, có khả năng truy xuất dữ liệu “mới nhất” để input vào mô hình.
- Offline Store: lưu lịch sử dữ liệu khối lượng lớn (thường ở S3) để phục vụ huấn luyện (training), phân tích hoặc xây dựng tính năng mới.
- Theo dõi phiên bản, quản lý metadata: Feature Store quản lý thời gian, người tạo, kiểu dữ liệu, version… của từng feature.
- Click tab Data flow.
- Click dấu +.
- Click Export -> Export via Jupyter notebook -> SageMaker Feature Store.
- Chọn Download a local copy
- Click Download


- Thực hiện giải nén và upload 2 file .ipynb và .flow lên SageMaker Notebook đã tạo trước đó.

- Sau khi upload thành công, thực hiện rename: ProcessingBankingCode.ipynb và ProcessingBankingFlow.flow. Mở file .ipynb vừa upload và chọn Kernel Python 3 để thực thi code.

Note: Chúng ta có thể xuất trực tiếp các feature được tạo sau khi chuyển đổi sang Amazon S3. Tuy nhiên trong lab này, trước tiên chúng ta sẽ xuất sang Amazon Feature Store (offline) để minh họa cách sử dụng dịch vụ này.
- Copy và Paste đoạn code dưới đây để cập nhật các thông tin biến (đổi giá trị None -> FS_ID và FS_time) giúp xác định feature store.
record_identifier_feature_name = "FS_ID"
if record_identifier_feature_name is None:
raise SystemExit("Select a column name as the feature group record identifier.")
event_time_feature_name = "FS_time"
if event_time_feature_name is None:
raise SystemExit("Select a column name as the event time feature name.")

Sau đó nhấn Shift + Enter để chạy cell đầu tiên.
- Tiếp tục nhấn Shift + Enter để chạy cell thứ 2 và cell thứ 3.

- Tại cell thứ 4 chúng ta sẽ thay đổi giá trị flow_name = "ProcessingBankingFlow" và enable_online_store = true thành enable_online_store = false vì trong lab này chúng ta không sử dụng tính năng online feature store để thực hiện lấy feature training trong real-time inference.

- Tiếp tục chạy cell 5 và 6 để tạo Feature group name. Sau khi hoàn thành, feature group sẽ được tạo ở Sagemaker studio.


- Xác nhận feature group tạo thành công.

- Chạy tiếp các cell 8 à 9

- Thực hiện upload file ProcessingBankingFlow.flow vào S3 bucket và cấu hình nó làm input cho SageMaker Processing Job.

- Bước cuối cùng, thực hiện chạy Processing Job. Thay đổi instance_type phù hợp với từng tài khoản ( vào Service Quotas -> AWS Service -> Sagemaker -> nhập ml.m5.x4.... ). Lưu ý: container_uri là giá trị động, mỗi region sẽ có 1 uri image public riêng, thay đổi phù hợp giá trị so với region bạn đang sử dụng. (Link tham khảo). Ở đây mình dùng region US -> mã là 663277389841.


- Chạy hết các cell còn lại



- Thông tin chi tiết Job sẽ hiển thị trên giao diện AWS Console. Vào Sagemaker -> Processing Job -> Tên Job

Quay lại SageMaker studio, click mục Feature store, chúng ta sẽ thấy được thông tin feature group đã được tạo.
Truy vấn thông tin từ Feature Store sử dụng Amazon Athena. SageMaker Feature Store metadata cũng được lưu trữ trong AWS Glue Catalog và chúng ta có thể thực hiện truy vấn thông qua Amazon Athena.
Truy cập dịch vụ Athena, chọn Query editor -> chọn Tab Settings -> chọn S3 bucket mà bạn muốn lưu kết quả truy vấn ( ở đây mình sử dụng luôn bucket S3 do sagemaker đã tạo trước đó)
Quay lại tab Editor, thực hiện 1 vài truy vấn nâng cao:
a. Tính độ tuổi trung bình theo từng nhóm nghề nghiệp (job)
SELECT job, AVG(age) AS avg_age
FROM fg_processingbankingflow_53b6af2b_1749390786
GROUP BY job
ORDER BY avg_age DESC;

b. Tính tỉ lệ khách hàng đã kết hôn trong toàn bộ tập dữ liệu
SELECT
ROUND(AVG(CAST(marital_married AS double)) * 100, 2) AS married_percentage
FROM fg_processingbankingflow_53b6af2b_1749390786;

c. Phân tích số lượng theo nhóm job, phân loại theo not_working (có/không)
SELECT job,
SUM(CASE WHEN not_working = 1 THEN 1 ELSE 0 END) AS unemployed,
SUM(CASE WHEN not_working = 0 THEN 1 ELSE 0 END) AS employed
FROM fg_processingbankingflow_53b6af2b_1749390786
GROUP BY job;

- Bạn đã hoàn thành export các feature vào SageMaker feature store. Ở bước tiếp theo, sẽ thực hiện export data vào S3 để thực hiện training model.
2.7 Export Data tới S3 để chuẩn bị cho việc training
Note: Ở bước 2.1 -> 2.6 chúng ta đã thực hiện ETL data -> export data vào Feature store và dùng Athena để query dữ liệu, làm quen với các thao tác kéo thả của Data Wrangler. Ở bước 2.7 chúng ta cũng thực hiện các bước chuyển đổi data tương tự -> export data vào S3, sử dụng code. Mục đích: Biết được 2 cách thực hiện tiền xử lý dữ liệu thông qua Data Wrangler và code trên notebook.
- Quay lại giao diện Notebook và mở file numpy_xgboost_direct_marketing_sagemaker.ipynb.

- Thực hiện Cell 1 và 2 để import các thư viện ML, bằng cách click chọn vào cell và ấn tổ hợp phím Shift + Enter.

- Tương tự cho Cell 3. Đoạn mã đọc tệp CSV “./bank-additional/bank-additional-full.csv” thành DataFrame data. Sau đó, cấu hình cho Pandas hiển thị tối đa 500 cột và chỉ 20 dòng. Cuối cùng, gọi dữ liệu để xem dữ liệu bảng vừa đọc.

- Đến với cell tiếp theo, đầu tiên, vòng lặp duyệt qua các cột kiểu object (trừ cột y), dùng pd.crosstab để thống kê tần suất (theo cột y) cho mỗi giá trị của cột đó. Tiếp theo, vòng lặp cho các cột dạng số (numeric) in tên cột và vẽ biểu đồ histogram, chia theo hai nhóm y (by='y'), giúp so sánh phân phối dữ liệu của từng cột giữa các giá trị y.

- Tiếp theo, đoạn code sẽ:
- data.corr(numeric_only=True): Tính ma trận tương quan (Correlation Matrix) giữa các biến số, giúp xem mối quan hệ tuyến tính giữa các cột numeric.
- pd.plotting.scatter_matrix(data, figsize=(12, 12)): Tạo ma trận biểu đồ phân tán (scatter plot) của tất cả cặp cột trong DataFrame, trực quan hóa tương quan giữa các thuộc tính.
- plt.show(): Hiển thị biểu đồ vừa được tạo.

- Thực thi cell kế tiếp:
- data['no_previous_contact']: Gắn giá trị 1 nếu cột pdays bằng 999 (tức chưa liên lạc lần nào), ngược lại 0.
- data['not_working']: Gắn 1 nếu cột job nằm trong danh sách ['student', 'retired', 'unemployed'], còn lại 0.
- model_data = pd.get_dummies(data, dtype=float): Chuyển các cột phân loại trong data thành dạng biến giả (one-hot encoding) và ép kiểu thành float, lưu kết quả vào model_data.

Tiếp tục, đoạn code này loại bỏ một số cột không muốn sử dụng (ví dụ duration, emp.var.rate, v.v.) ra khỏi DataFrame model_data. Các cột trong danh sách được truyền vào drop và chỉ định axis=1 để xóa theo chiều cột.
Đoạn code ngẫu nhiên trộn (shuffle) toàn bộ dữ liệu model_data (nhờ sample(frac=1, random_state=1729)) rồi chia thành 3 phần theo tỷ lệ 70% – 20% – 10%: train_data (70% đầu), validation_data (20% tiếp theo), test_data (10% cuối).
Ở 2 cell cuối cùng, 2 dòng pd.concat(...) đầu tiên chuyển cột nhãn (‘y_yes’) lên đầu và loại bỏ các cột không cần thiết (y_no, y_yes) trong train_data và validation_data, sau đó lưu dữ liệu thành hai file CSV (train.csv và validation.csv) mà không ghi kèm cột và chỉ số dòng. Sau đó sẽ tải hai file CSV đó lên Amazon S3, để SageMaker có thể lấy dữ liệu và huấn luyện mô hình.


Bạn đã chuẩn bị thành công dữ liệu để train model XGBoost.
Trong phần 2 này, bạn đã trải qua quá trình thiết lập môi trường cần thiết và sử dụng kỹ thuật để làm sạch dữ liệu và chuẩn bị dữ liệu của bạn cho việc build, train model.
Trong phần tiếp theo, chúng ta sẽ thực hiện train, tuning và deploy model XGBoost bằng thuật toán XGBoost tích hợp sẵn của SageMaker.
3. Train/Deploy/Evalution/Tuning
Trong phần này, bạn sẽ tìm hiểu về phần được hightlight trong qui trình ML bên dưới:
- Train model
- Deploy model
- Evalution model
- Tuning model automation

3.1 Train model
XGBoost là một thuật toán tích hợp sẵn (built-in algorithm) trong Amazon SageMaker, dựa trên thư viện eXtreme Gradient Boosting (XGBoost) – một trong những mô hình học máy phổ biến và mạnh mẽ cho các bài toán Hồi quy (Regression) và Phân loại (Classification).
Dưới đây là một số trường hợp sử dụng (use cases) phổ biến:
- Dự đoán gian lận (Fraud Detection): Các giao dịch thanh toán, hoạt động ngân hàng, đăng ký tài khoản… thường có dấu hiệu gian lận.
- Dự báo nhu cầu (Demand Forecasting): Dùng trong bán lẻ, kho vận, quản lý chuỗi cung ứng…kết hợp các biến dự báo về mùa vụ, lễ tết, xu hướng, và các yếu tố bên ngoài (thời tiết, marketing…).
- Phân loại khách hàng (Customer Segmentation) & Churn Prediction: Trong marketing, CRM, bạn có thể dự đoán khả năng rời bỏ (churn) của khách.
- Phân loại và hồi quy chung (General Classification/Regression): dự báo giá nhà, phân loại ảnh có sử dụng đặc trưng tabular, dự đoán tín dụng, v.v.
- Phân tích rủi ro và định giá (Risk Analysis, Pricing): Trong tài chính, bảo hiểm, XGBoost thường được dùng để ước tính xác suất tổn thất, tính phí bảo hiểm, v.v.
- Bước đầu tiên chúng ta sẽ chỉ định vị trí của ECR container.

- Chỉ định vị trí của train và validation data set.

- Quy trình huấn luyện XGBoost trong SageMaker bao gồm:
- Tải dữ liệu (đã chuẩn hoá) lên S3.
- Tạo phiên bản Estimator với
sagemaker.xgboost.estimator.XGBoost (hoặc “BYO container” XGBoost). - Khai báo các tham số training (hyperparameters) như
max_depth, eta, num_round, …trong set_hyperparameters. - Gọi lệnh
.fit(...) chỉ định dữ liệu trên S3, SageMaker sẽ tạo môi trường và huấn luyện tự động. - Sau khi huấn luyện xong, bạn có thể
.deploy(...) mô hình lên endpoint để phục vụ dự đoán real-time.
- Sau khi run cell, có thể thấy quá trình training đang diễn ra.

- Vào giao diện dịch vụ Amazon SageMaker AI.
- Click Training.
- Click Training jobs.
- Sẽ mất 5-10 phút để training job hoàn tất.

- Sau khi hoàn thành quá trình training, model sẽ được đóng gói và lưu ở S3.

- Chúng ta đã hoàn tất bước train cho model XGBoost, bước tiếp theo chúng ta sẽ thực hiện deploy model.
3.2 Deploy model
- Trong bước này chúng ta sẽ thực hiện deploy model dưới dạng một HTTPS endpoint. Quá trình này sẽ mất khoảng 6-8 phút. Bạn cũng có thể chọn mẫu instance type mới hơn như ml.m5.xlarge cho deployment này.
- Pricing: https://instances.vantage.sh/aws/ec2/m4.xlarge

- Quay trở lại management console của dịch vụ Sage Maker để kiểm tra tiến trình deploy endpoint.
- Click Inference.
- Click Endpoints.

- Sau khi tiến trình deploy endpoint hoàn tất bạn có thể tiếp tục làm bước tiếp theo , thực hiện đánh giá model.
3.3 Evalution model
Trong bước này chúng ta sẽ thực hiện format lại CSV data, sau đó chạy model để thực hiện tiên đoán.
Chúng ta sẽ đánh giá hiệu suất của model sử dụng confusion matrix. Trong trường hợp này chúng ta sẽ tiên đoán liệu khách hàng có đăng ký gửi tiền theo kỳ hạn(1) hay không(0).
- Đầu tiên chúng ta sẽ cần xác định cách thức truyền data và nhận data từ endpoint. Data của chúng ta hiện được lưu trữ dưới dạng NumPy arrays trong bộ nhớ của notebook instance. Để gửi nó thông qua HTTP POST request, chúng ta sẽ thực hiện serialize data như một CSV string và decode kết quả CSV đó.

- Tiếp theo chúng ta sẽ tạo một hàm đơn giản để :
- Lặp lại tập test data set của chúng ta.
- Chia nó thành các nhóm nhỏ theo hàng.
- Chuyển đổi các nhóm nhỏ đó thành chuỗi nội dung CSV (lưu ý, trước tiên chúng ta loại bỏ biến mục tiêu khỏi data set).
- Truy xuất các dự đoán theo nhóm nhỏ bằng cách gọi XGBoost endpoint.
- Thu thập các dự đoán và chuyển đổi từ đầu ra CSV mà model của chúng ta cung cấp thành một NumPy array.

- Kiểm tra kết quả confusion matrix để xem hiệu suất kết quả tiên đoán so với kết quả thực tế.

- Như vậy, trong số ~ 4000 khách hàng tiềm năng, mô hình dự đoán 53 người sẽ đăng ký và 101 người trong số họ thực sự đã đăng ký. Chúng ta cũng có 382 người đăng ký thực sự đăng ký mà mô hình đó không dự đoán sẽ đăng ký.

3.4 Automatic model Tuning (Optional advance)
Tune model tự động trên Amazon SageMaker, còn được gọi là Tune hyperparameters, tìm phiên bản tốt nhất của model bằng cách chạy nhiều job training trên dataset.
Ví dụ bài toán: Bạn đang giải quyết bài toán phân loại nhị phân (thành hai nhóm) với dữ liệu tiếp thị. Mục tiêu là tối ưu chỉ số AUC (AUC càng cao, khả năng mô hình phân tách đúng, giá trị AUC nằm trong khoảng 0 đến 1) cho mô hình XGBoost. Bạn không chắc nên chọn giá trị cụ thể nào cho các tham số: eta, alpha, min_child_weight, và max_depth. Thay vào đó, bạn có thể dùng chức năng Tune Hyperparameters của Amazon SageMaker để tự động tìm ra những giá trị “tối ưu” trong khoảng mà bạn đặt ra, giúp mô hình đạt AUC cao nhất.
hyperparameter_ranges = {
'eta': ContinuousParameter(0, 1),
'min_child_weight': ContinuousParameter(1, 10),
'alpha': ContinuousParameter(0, 2),
'max_depth': IntegerParameter(1, 10)
}
Đây là một dictionary định nghĩa phạm vi tìm kiếm của từng siêu tham số, dùng trong thuật toán Bayesian Optimization để tự động tìm giá trị tốt nhất.
| Tham số | Ý nghĩa | Phạm vi tìm kiếm |
|---|
| 'eta' | Tốc độ học (learning rate) của mô hình XGBoost. Giá trị nhỏ (ví dụ 0.01) khiến mô hình học chậm nhưng cẩn thận hơn, giúp giảm nguy cơ overfitting. Giá trị lớn (ví dụ 0.3) đẩy tốc độ học nhanh, nhưng dễ dẫn đến sai số cao. | 0 đến 1 |
| 'min_child_weight' | Số lượng mẫu tối thiểu trong một leaf của cây | 1 đến 10 |
| 'alpha' | Tham số điều chuẩn L1 (L1 regularization) giúp tránh overfitting | 0 đến 2 |
| 'max_depth' | Độ sâu tối đa của cây quyết định mức độ phức tạp mô hình. Cây càng sâu, mô hình có thể học nhiều quy tắc chi tiết nhưng rủi ro overfitting tăng. | 1 đến 10 (nguyên) |
- Chúng ta sẽ điều chỉnh bốn hyperparameters trong ví dụ này:
- Vì chúng ta đang sử dụng thuật toán XGBoost tích hợp sẵn, nó tạo ra hai chỉ số được xác định trước: validatioN:auc và training:auc và chúng ta đã chọn giám sát chỉ số validation:auc. Đọc thêm các model metrics tại đây.

- Bây giờ, chúng ta sẽ tạo một đối tượng Hyperparameter Tuner, chúng ta sẽ truyền vào đối tượng đó:
- XGBoost estimator mà chúng ta đã tạo ở trên
- Tên và định nghĩa chỉ số mục tiêu
- Phạm vi hyperparameters chúng ta muốn.
- Điều chỉnh cấu hình tài nguyên chẳng hạn như Tổng số công việc train sẽ chạy và số lượng công việc train có thể chạy song song.

- Bây giờ chúng ta có thể khởi chạy công việc điều chỉnh hyperparameters bằng cách gọi hàm fit(). Sau khi công việc điều chỉnh hyperparameters được tạo.

- Chúng ta có thể vào bảng điều khiển SageMaker để theo dõi tiến trình của công việc điều chỉnh hyperparameters cho đến khi hoàn thành.
- Click Training.
- Click Hyperparameter tuning jobs.
- Click tên job.
- Chúng ta có thể theo dõi chi tiết các training jobs tại giao diện summary.


- Trạng thái hoàn tất thể hiện công việc tuning hyperparameters đã hoàn tất.

- Sau khi hoàn thành công việc tune model, bạn có thể chọn công việc train có hiệu suất tốt nhất, deploy, thực hiện predict và đánh giá model như các bước đã thực hiện trước. Version: xgboost-250301-0552-019-cd458d12 có metric value cao nhất.


- Có nhiều version model khác nhau được lưu ở S3 output. Bạn có thể chọn model có tỉ lệ chính xác cao nhất để deploy lên môi trường production thông qua SageMaker Endpoint.
- Bạn đã đi qua quá trình preparedata, build , train , tune và deploy model XGBoost bằng cách sử dụng thuật toán tích hợp sẵn của SageMaker AI.
Chúng ta cũng đã sử dụng SageMaker Python SDK để build, tune và deploy model. Bạn cũng đã làm quen với giao diện của SageMaker trong khi thực hiện train, automatic model tuning và deploy model vào môi trường sử dụng.
4. Dọn dẹp tài nguyên
Chúng ta sẽ tiến hành xóa các tài nguyên theo thứ tự sau
- Xóa endpoint đã được deploy, bằng cách thực thi các cell sau.

- Mở giao diện quản trị của Amazon SageMaker AI.
- Click Amazon SageMaker Studio để mở giao diện Amazon SageMaker Studio. Stop và delete instance.

- Thực hiện các bước dưới cho mỗi user được tạo ra.
- Click chọn user.
- Tại trang chi tiết user, thực hiện Delete.
- Click chọn Yes, delete user và gõ delete để xác nhận.
- Click Delete.

- Sau khi thực hiện delete hết user, click chọn Delete Domain.
- Click Delete để hoàn tất việc xóa SageMaker Domain.







