Lab Introduction
- AWS experience: Advanced
- Time to complete: 60 minutes
- AWS Region: US East (N. Virginia) us-east-1
- Cost to complete: $1~2
- Services used: SageMaker AI, Amazon S3, Clarify, Notebook
Architecture Diagram
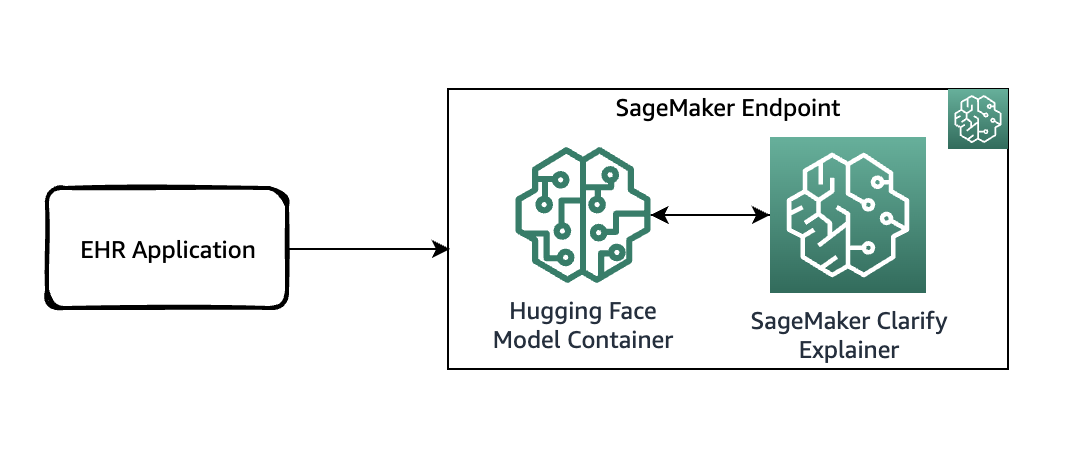
Ngày nay, nơi các dự đoán được đưa ra bởi các thuật toán học máy (ML) ở quy mô lớn, việc các tổ chức công nghệ có thể giải thích cho khách hàng và đội ngũ nội bộ lý do tại sao họ đưa ra một quyết định nhất định dựa trên dự đoán của mô hình ML ngày càng trở nên quan trọng. Việc giải thích các mô hình ML và hiểu được lý do đằng sau các dự đoán thường khó khăn, nhưng lại rất quan trọng để sử dụng ML một cách có trách nhiệm.
AWS SageMaker Clarify là một tính năng nâng cao trong AWS SageMaker giúp phát hiện sai lệch và giải thích các dự đoán của mô hình, cung cấp các công cụ để tăng cường tính công bằng và minh bạch.
Các tính năng chính của SageMaker Clarify:
- Phát hiện sai lệch (Bias Detection): Phân tích dữ liệu và mô hình để tìm ra sai lệch ở nhiều giai đoạn.
- Khả năng giải thích (Explainability): Sử dụng SHAP (SHapley Additive exPlanations) để làm rõ tầm quan trọng của tính năng trong các dự đoán.
- Tích hợp với SageMaker Pipelines(Integration with SageMaker Pipelines): Cho phép giám sát sai lệch và khả năng giải thích từ đầu đến cuối trong toàn bộ quy trình học máy.
1. Prerequisites and Data
1.1 Create Sagemaker notebook
Truy cập dịch vụ Sagemaker AI, bên thanh menu bên trái, chọn Notebooks -> Chọn nút Create notebook instance.
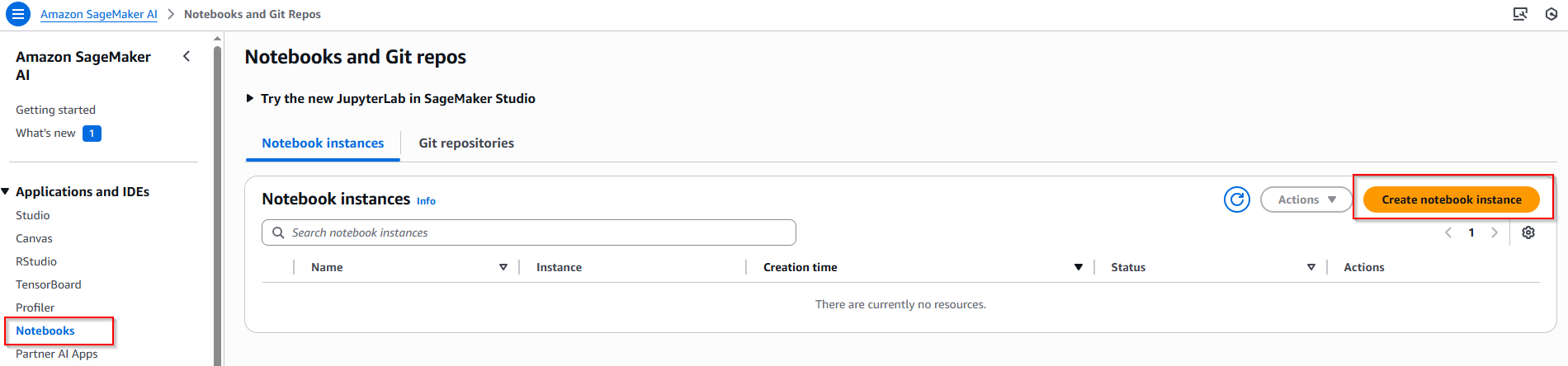
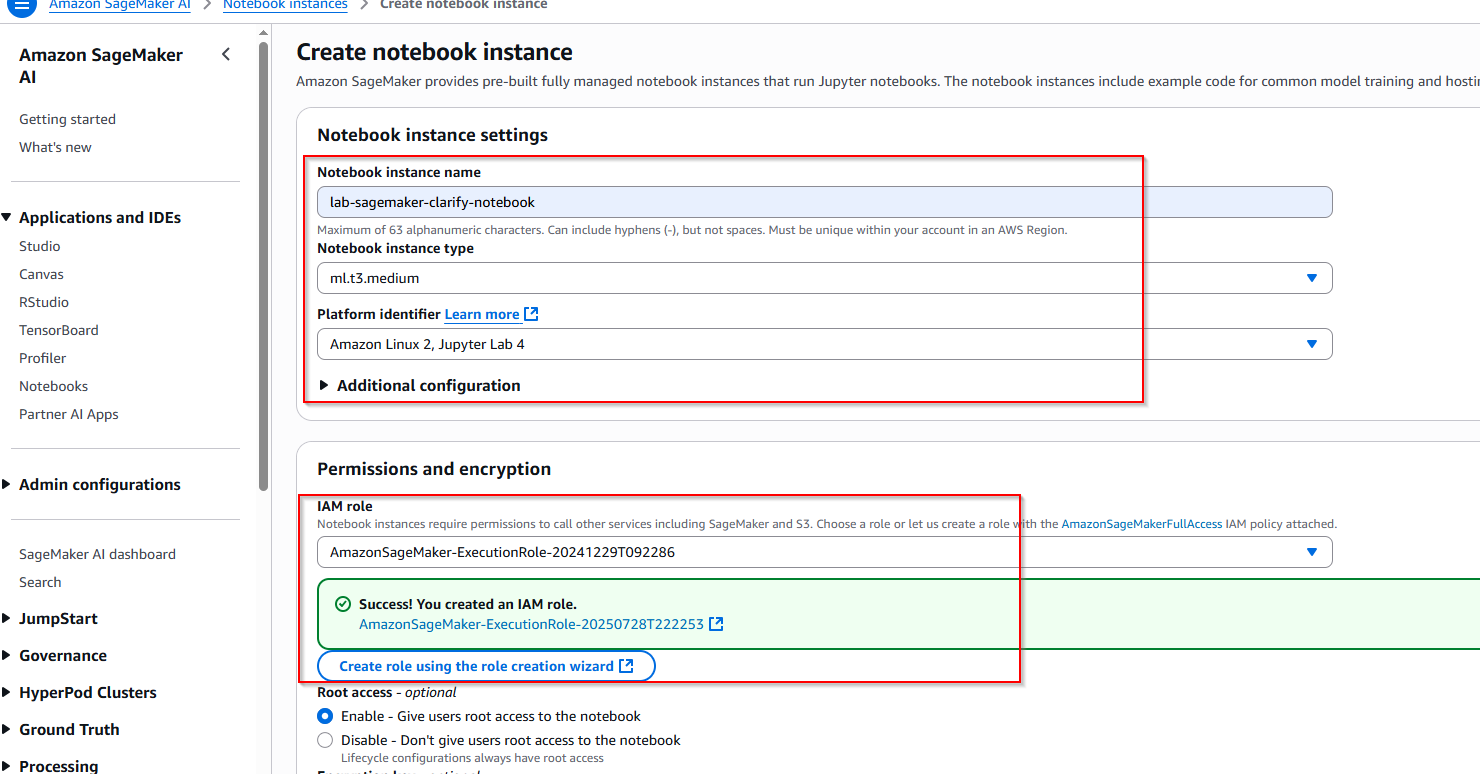
Nhập các thông tin cấu hình bên dưới:
- Notebook instance name: lab-sagemaker-clarify-notebook
- Notebook instance type: ml.t3.medium
- Platform identifier: Amazon Linux 2, Jupyter Lab 4
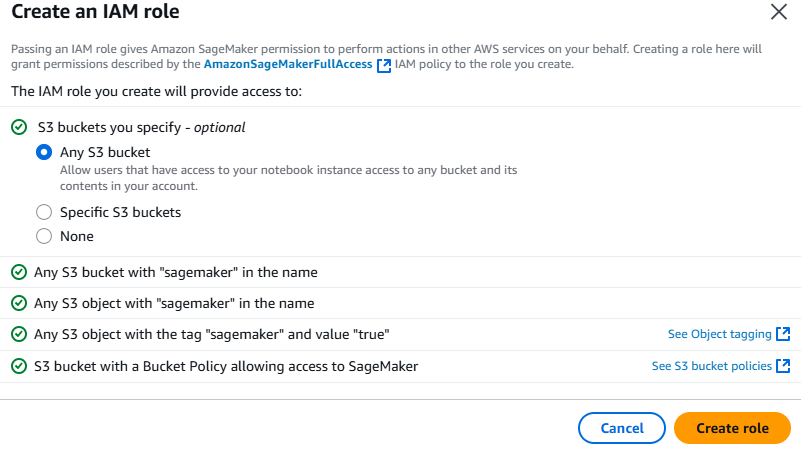
- IAM role: Create a new role -> Any S3 bucket -> Create role
Cuối cùng, chọn nút Create notebook instance
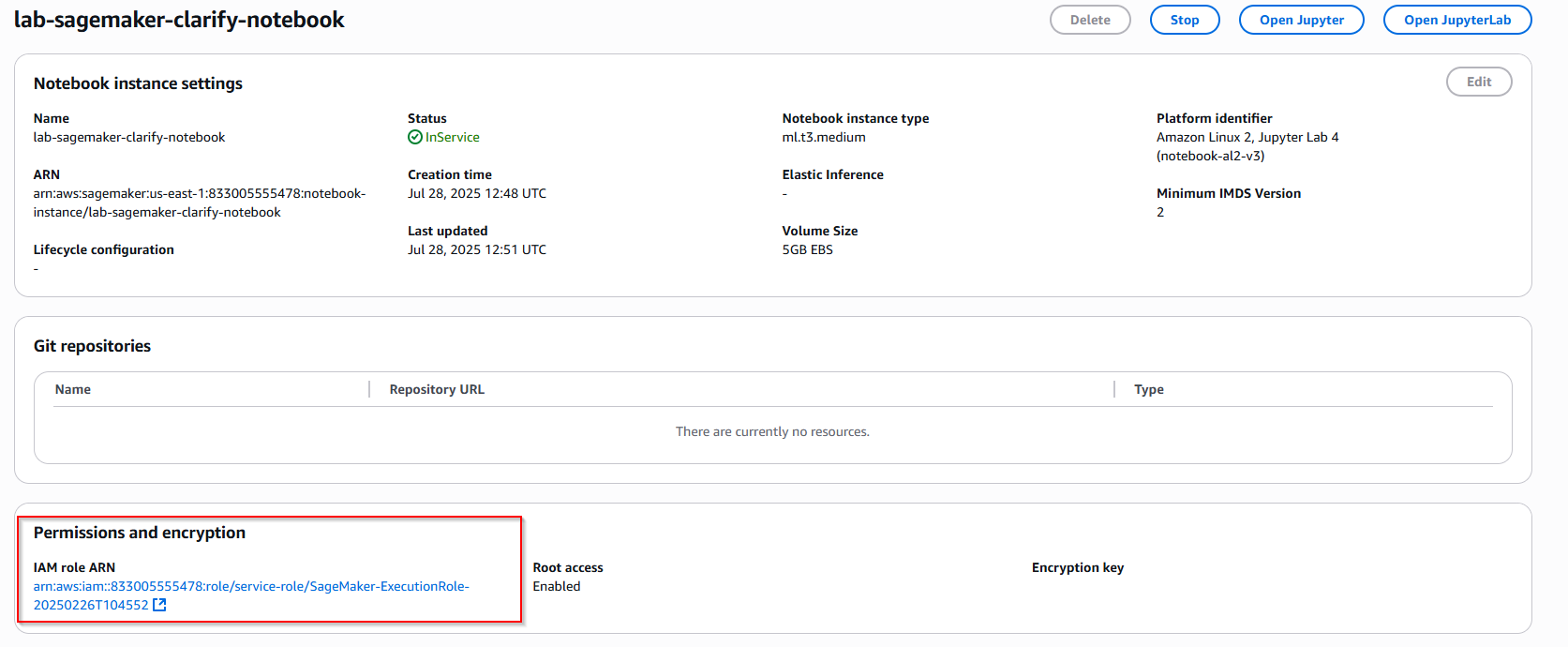
1.2 Update IAM role ARN notebook
- Sau khi notebook tạo thành công, tìm đến mục Permission and encryption -> Nhấn vào IAM role ARN. Hãy note lại IAM role ARN để sử dụng về sau.
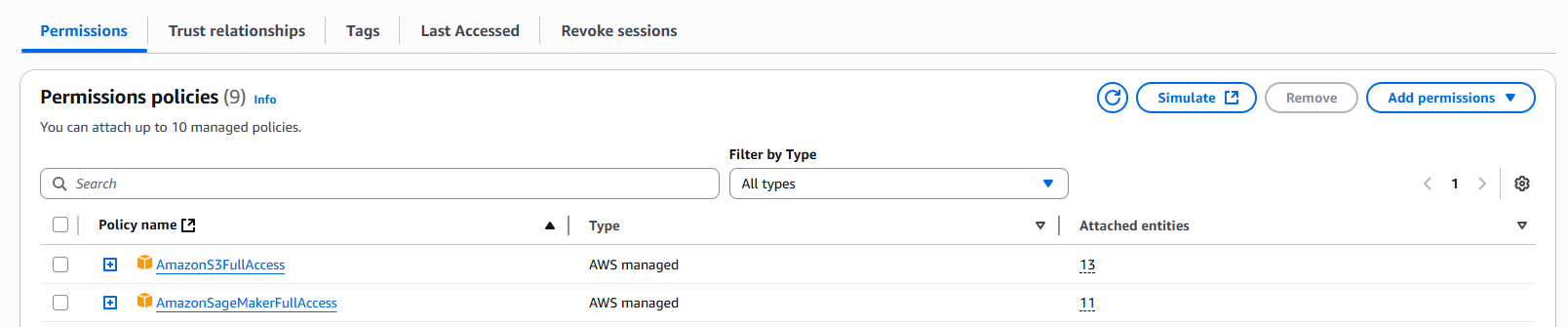
- Nhấn nút Add permission -> thêm quyền AmazonSagemakerFullAccess mục đích để sử dụng tính năng Clarify trogn Sagemaker ( trong dự án thực tế nên giới hạn lại quyền truy cập, trong bài thực hành mình sẽ dùng FullAccess cho nhanh )
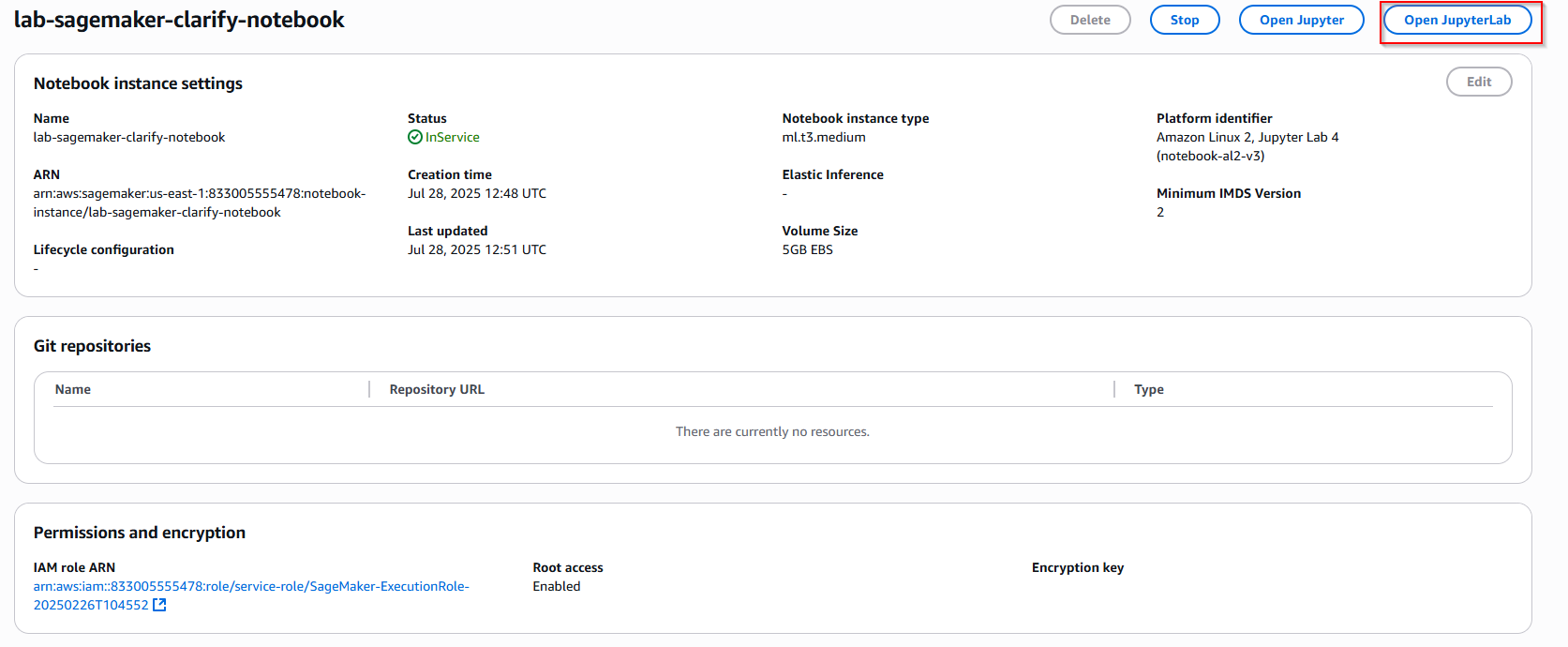
- Quay lại giao diện Sagemaker notebook, nhấn nút Open JupyterLab để mở môi trường notebook.
- Đây là giao diện Sagemaker Notebook, tiếp tục chọn icon conda_pytorch_p310 để tiến hành chạy code.

- Chúng ta sẽ thực hiện copy + run từng cell code bên dưới để xem kết quả (note: nhấn shift+enter để chạy 1 cell)

1.3 Importing Libraries
Bước đầu tiên, chúng ta sẽ setup môi trường Python và cài đặt các thư viện cần thiết:
- pandas and numpy for data manipulation and numerical operations.
- os and boto3 for operating system and AWS SDK operations.
- datetime for handling date and time data.
Copy đoạn code đã chuẩn bị sẵn vào cell trong notebook, sau đó nhấn Shift+Enter để chạy từng dòng.
import pandas as pd
import numpy as np
import os
import boto3
from datetime import datetime
from sagemaker import session, get_execution_role
from sklearn.model_selection import train_test_split

1.4 Initializing Configurations
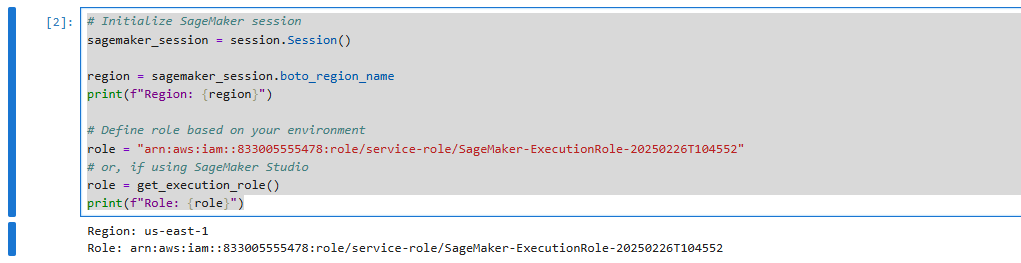
Khởi tạo SageMaker session và sử dụng IAM role ARN (đã note ở trên) để tương tác với các dịch vụ khác AWS
Ở mục role, thay thế bằng role_arn của bạn.
# Initialize SageMaker session
sagemaker_session = session.Session()
region = sagemaker_session.boto_region_name
print(f"Region: {region}")
# Define role based on your environment
role = "arn:aws:iam::833005555478:role/service-role/SageMaker-ExecutionRole-20250226T104552"
# or, if using SageMaker Studio
role = get_execution_role()
print(f"Role: {role}")
1.5 Downloading the Data
Việc hiểu biết thấu đáo về tập dữ liệu của chúng ta là rất quan trọng để xác định và giải quyết các thiên vị tiềm ẩn. Tập dữ liệu bao gồm: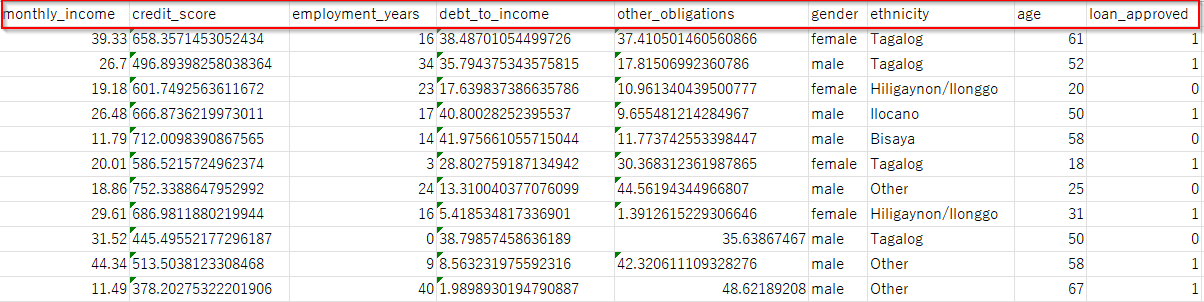
- Thu nhập hàng tháng (Monthly Income): Một tính năng số biểu thị thu nhập của người nộp đơn, một yếu tố quan trọng trong các quyết định cho vay. (ví dụ: lương anh A là 15 triệu với khoảng vay là 500 triệu trong 2 năm lãi suất 3%/năm)
- Điểm tín dụng (Credit Score): Cho biết mức độ tín nhiệm của người nộp đơn, rất quan trọng đối với việc phê duyệt khoản vay.
- Số năm làm việc (Employment Years): Biểu thị thời gian làm việc, có khả năng ảnh hưởng đến các quyết định cho vay.
- Tỷ lệ Nợ trên Thu nhập và các nghĩa vụ khác (Debt-to-Income Ratio and Other Obligations): Đánh giá sự ổn định tài chính và khả năng trả nợ.
- Giới tính (Gender): Một thuộc tính nhạy cảm có thể là cơ sở cho thiên vị giới tính trong các quyết định cho vay.
- Dân tộc (Ethnicity): Phản ánh sự đa dạng về văn hóa ở Philippines, một yếu tố tiềm ẩn gây ra thiên vị sắc tộc.
- Tuổi tác (Age): Phạm vi từ 18 đến 70, và có thể ảnh hưởng đến các quyết định, dẫn đến phân biệt tuổi tác.
- Biến mục tiêu (loan_approved) là trạng thái phê duyệt khoản vay, mà chúng ta sẽ phân tích thiên vị bằng cách sử dụng SageMaker Clarify.
Tạo một S3 bucket và upload tệp dataset lên S3 bucket.
1.6 Preprocessing
Tiền xử lý bao gồm việc chuẩn hóa dữ liệu và mã hóa phân loại, mục đích chuẩn bị tập dữ liệu cho các mô hình học máy.
- Scaling the numerical features:
import pandas as pd
import boto3
from sklearn.preprocessing import StandardScaler
s3_bucket = 's3://channy-demo-s3-vector-786521'
s3_key = 'philippines_loans_data.csv'
s3_path = f's3://{s3_bucket}/{s3_key}'
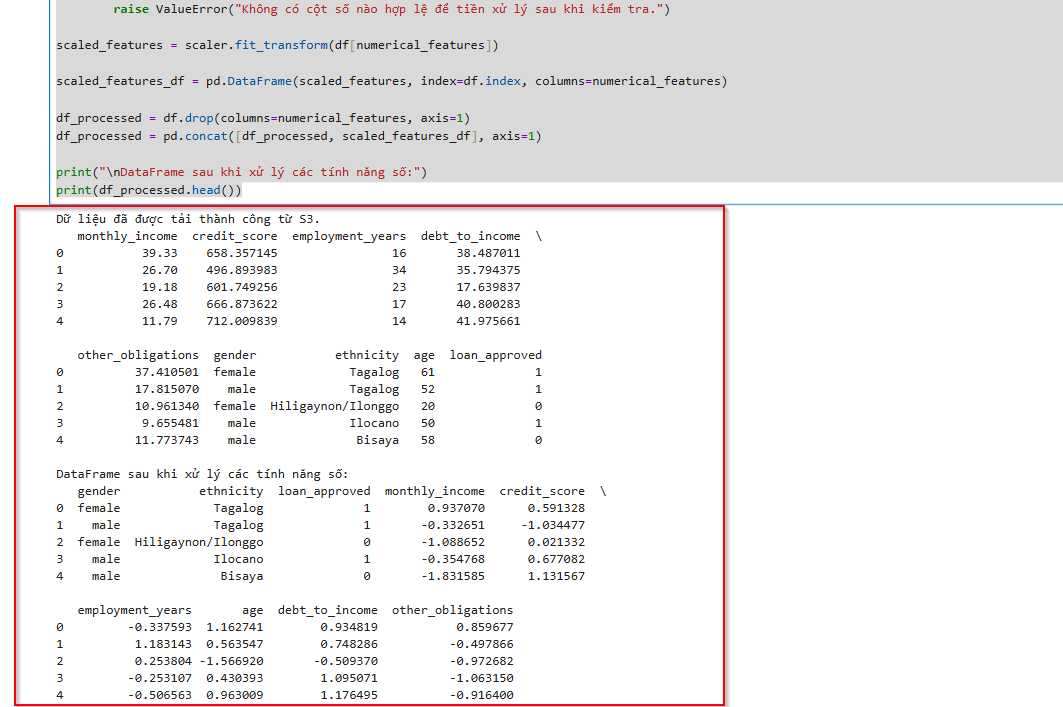
try:
df = pd.read_csv(s3_path)
print("Data was successfully loaded from S3.")
print(df.head())
except Exception as e:
print(f"Error loading data from S3: {e}")
numerical_features = ["monthly_income", "credit_score", "employment_years", "age", "debt_to_income", "other_obligations"]
scaler = StandardScaler()
missing_cols = [col for col in numerical_features if col not in df.columns]
if missing_cols:
print(f"Warning: The following columns were not found in the DataFrame: {missing_cols}")
numerical_features = [col for col in numerical_features if col not in missing_cols]
if not numerical_features:
raise ValueError("There are no valid numeric columns to preprocess after checking.")
scaled_features = scaler.fit_transform(df[numerical_features])
scaled_features_df = pd.DataFrame(scaled_features, index=df.index, columns=numerical_features)
df_processed = df.drop(columns=numerical_features, axis=1)
df_processed = pd.concat([df_processed, scaled_features_df], axis=1)
print("\nDataFrame after processing numeric features:")
print(df_processed.head())
- Splitting the dataset:
test_size=0.2: Tham số này quy định tỉ lệ kích thước của tập dữ liệu kiểm tra. Trong trường hợp này, 20% (0.2) dữ liệu sẽ được sử dụng cho tập kiểm tra (testing_data), và 80% còn lại sẽ được sử dụng cho tập huấn luyện (training_data).- Hàm sẽ trả về hai dataframe mới:
training_data: Chứa 80% dữ liệu gốc, dùng để huấn luyện mô hình.testing_data: Chứa 20% dữ liệu gốc, dùng để đánh giá hiệu suất của mô hình sau khi đã huấn luyện.
training_data, testing_data = train_test_split(df, test_size=0.2,
random_state=0)

- Encoding categorical columns:
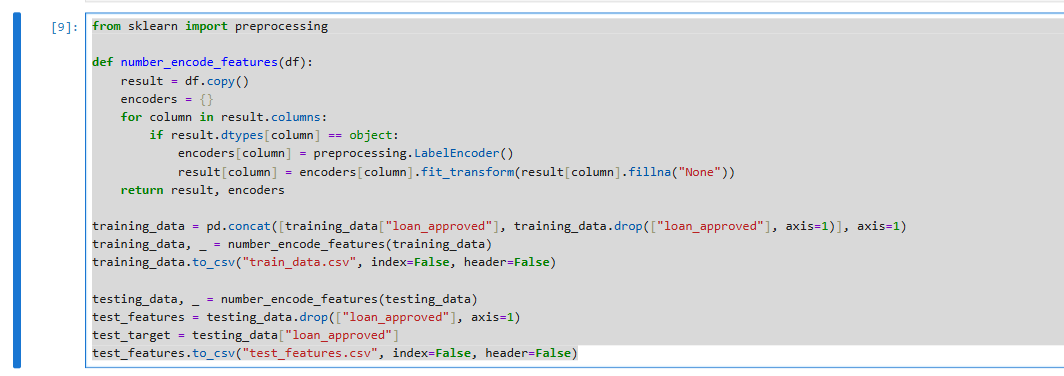
from sklearn import preprocessing
def number_encode_features(df):
result = df.copy()
encoders = {}
for column in result.columns:
if result.dtypes[column] == object:
encoders[column] = preprocessing.LabelEncoder()
result[column] = encoders[column].fit_transform(result[column].fillna("None"))
return result, encoders
training_data = pd.concat([training_data["loan_approved"], training_data.drop(["loan_approved"], axis=1)], axis=1)
training_data, _ = number_encode_features(training_data)
training_data.to_csv("train_data.csv", index=False, header=False)
testing_data, _ = number_encode_features(testing_data)
test_features = testing_data.drop(["loan_approved"], axis=1)
test_target = testing_data["loan_approved"]
test_features.to_csv("test_features.csv", index=False, header=False)
- Mã hóa số (Label Encoding): Chuyển đổi các cột văn bản (category) trong DataFrame thành số nguyên bằng
LabelEncoder. - Tiền xử lý dữ liệu huấn luyện: Áp dụng mã hóa số lên
training_data và lưu kết quả vào "train_data.csv". - Tiền xử lý dữ liệu kiểm tra: Áp dụng mã hóa số lên
testing_data, tách thành test_features và test_target, sau đó lưu test_features vào "test_features.csv".
2. Model Training
2.1 Putting Data Split into S3
Tạo 1 prefix sagemaker-clarify-article/philippines-loan trong S3 bucket dùng để lưu trữ dataset sau khi splitting
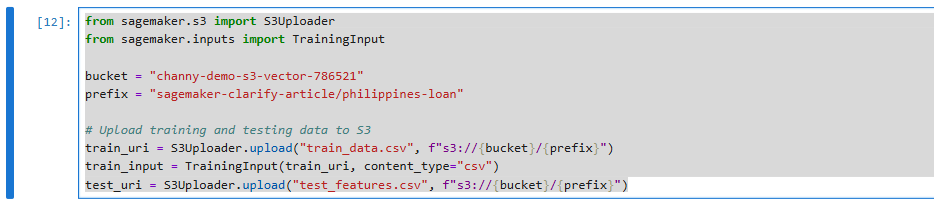
from sagemaker.s3 import S3Uploader
from sagemaker.inputs import TrainingInput
bucket = "channy-demo-s3-vector-786521"
prefix = "sagemaker-clarify-article/philippines-loan"
# Upload training and testing data to S3
train_uri = S3Uploader.upload("train_data.csv", f"s3://{bucket}/{prefix}")
train_input = TrainingInput(train_uri, content_type="csv")
test_uri = S3Uploader.upload("test_features.csv", f"s3://{bucket}/{prefix}")
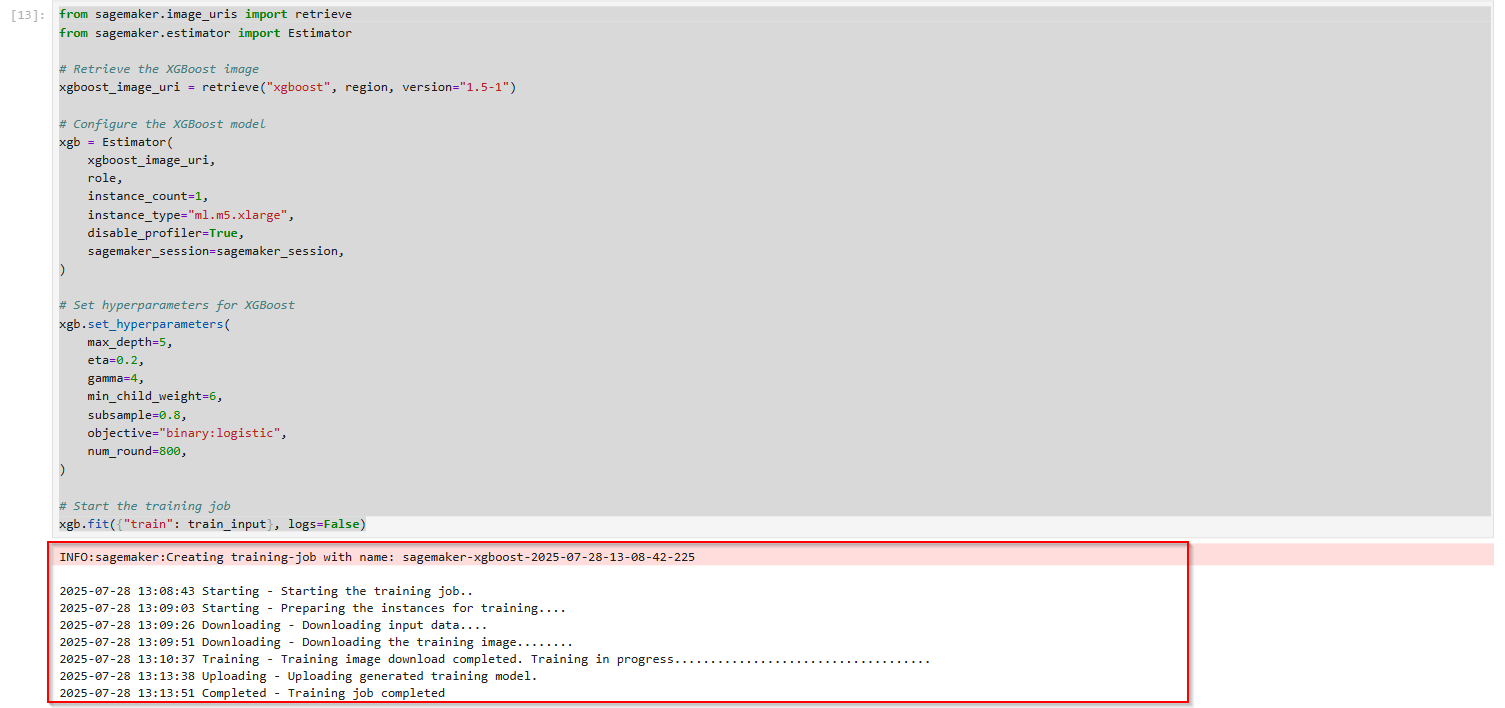
2.2 Training an XGBoost Model
XGBoost là một thuât toán phổ biến và hiệu quả cho cây tăng cường gradient, nổi tiếng về hiệu suất và tốc độ. Trong bước này, chúng ta sẽ cấu hình và khởi tạo mô hình XGBoost trên tập dữ liệu của mình.
from sagemaker.image_uris import retrieve
from sagemaker.estimator import Estimator
# Retrieve the XGBoost image
xgboost_image_uri = retrieve("xgboost", region, version="1.5-1")
# Configure the XGBoost model
xgb = Estimator(
xgboost_image_uri,
role,
instance_count=1,
instance_type="ml.m5.xlarge",
disable_profiler=True,
sagemaker_session=sagemaker_session,
)
# Set hyperparameters for XGBoost
xgb.set_hyperparameters(
max_depth=5,
eta=0.2,
gamma=4,
min_child_weight=6,
subsample=0.8,
objective="binary:logistic",
num_round=800,
)
# Start the training job
xgb.fit({"train": train_input}, logs=False)
- Lấy URI Docker image của XGBoost: Dòng
xgboost_image_url = retrieve("xgboost", region, version="1.5-1") lấy đường dẫn tới Docker image được build sẵn của thuật toán XGBoost do SageMaker quản lý. - Cấu hình Estimator: Đoạn code khởi tạo một đối tượng
Estimator cho XGBoost (xgb). Nó xác định:- xgboost_image_url: Docker image sẽ dùng để huấn luyện.role: Quyền IAM để SageMaker có thể truy cập dữ liệu và tài nguyên AWS khác.instance_count: Số lượng instance EC2 sẽ sử dụng (ở đây là 1).instance_type: Loại instance EC2 sẽ dùng (ở đây là ml.m5.xlarge).
- Thiết lập Hyperparameters (Siêu tham số): Đoạn code đặt các siêu tham số cho mô hình XGBoost như
max_depth, eta, gamma, objective (mục tiêu là phân loại nhị phân binary:logistic), và num_round (số vòng huấn luyện). - Khởi chạy Job huấn luyện: Dòng
xgb.fit({"train": train_input}, logs=False) bắt đầu quá trình huấn luyện.
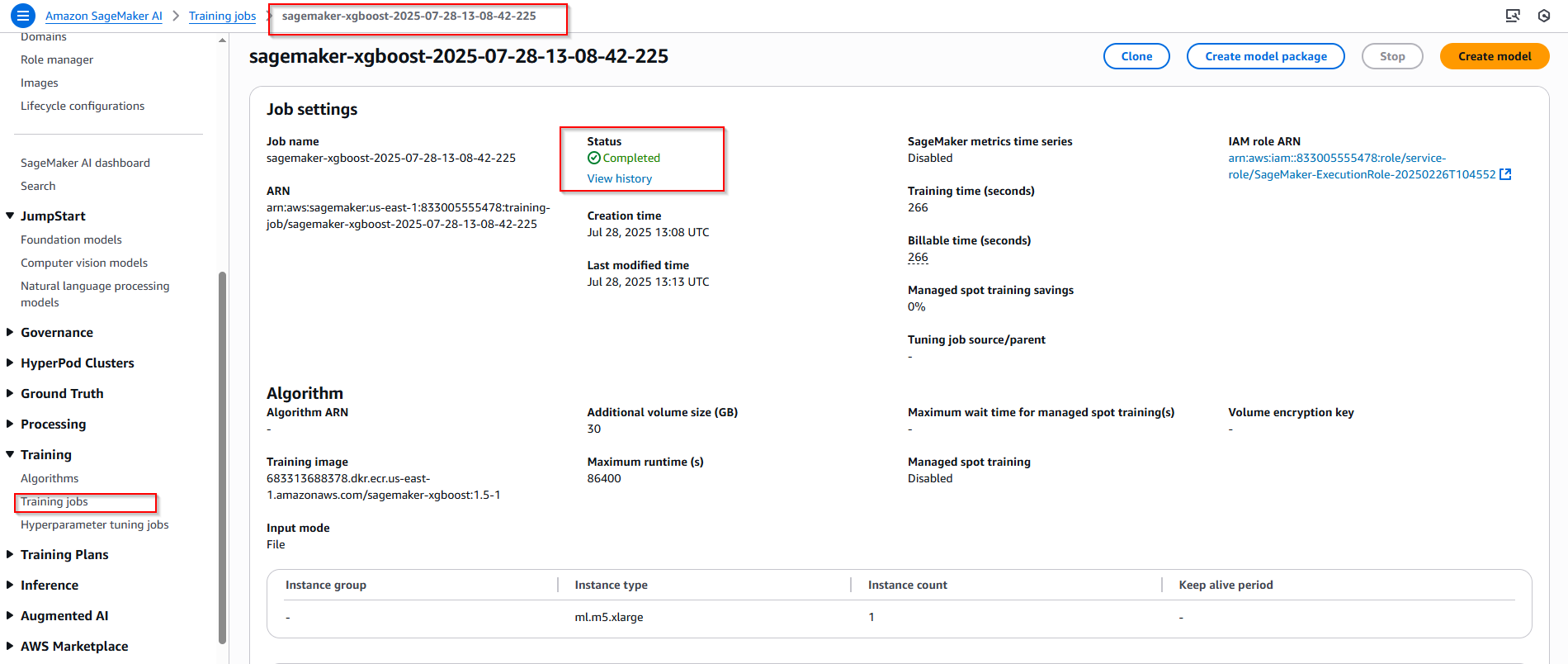
- Đợi khoảng 3-5p hoàn tất. Quay sang Sagmaker console, bên trái menu nhấn vào mục Training job, tại đây bạn có thể theo dõi quá trình training job.
3. Create a SageMaker Model
Sau khi hoàn tất quá trình đào tạo, bước tiếp theo là tạo mô hình SageMaker. Mô hình này sẽ được sử dụng để "kiểm tra chỉ số thiên vị và tại sao mô hình lại đưa ra kết quả dự đoán như vậy?" với SageMaker Clarify.
model_name = "DEMO-clarify-model-{}".format(datetime.now().strftime("%d-%m-%Y-%H-%M-%S"))
# Create a SageMaker model
model = xgb.create_model(name=model_name)
container_def = model.prepare_container_def()
sagemaker_session.create_model(model_name, role, container_def)

Quay lại màn hình Sagemaker console, chọn Inference -> Models -> DEMO-clarify-model-28-07-2025-13-16-23. Xác nhận model đã tạo thành công.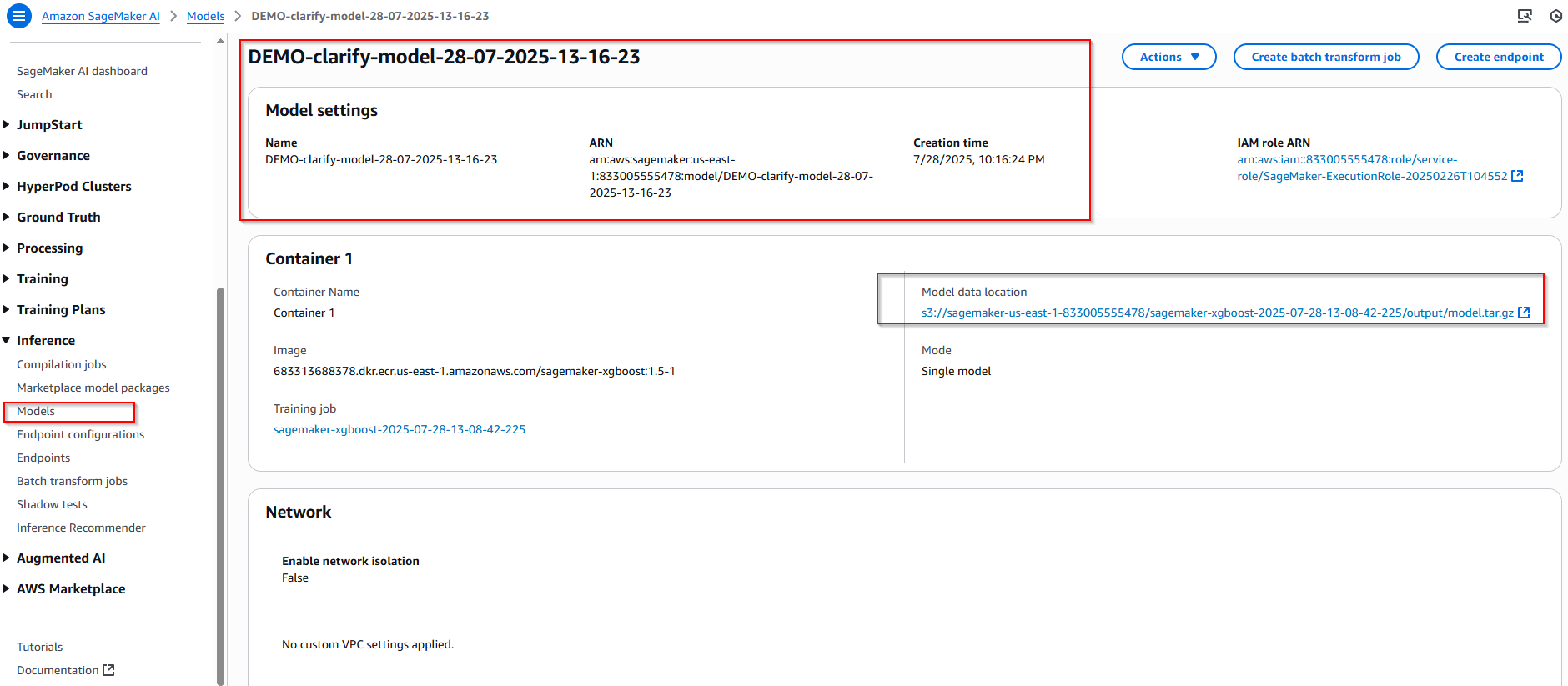
4. Amazon SageMaker Clarify - Bias Detection and Mitigation
4.1 Detecting Bias (Phát hiện thiên vị)
Phát hiện và giải quyết thiên vị là một khía cạnh then chốt của các thực hành AI có trách nhiệm. Trong phần này, chúng ta sẽ khám phá cách Amazon SageMaker Clarify giúp xác định và giảm thiểu các thiên vị trong các mô hình học máy.
4.2 SageMaker Clarify for Bias Detection
SageMaker Clarify là công cụ để phát hiện cả thiên vị trước huấn luyện và sau huấn luyện bằng cách sử dụng nhiều loại số liệu khác nhau. Thiên vị trước huấn luyện phát sinh từ chính dữ liệu huấn luyện, trong khi thiên vị sau huấn luyện có thể phát triển trong quá trình học của mô hình.
4.3 Initializing Clarify
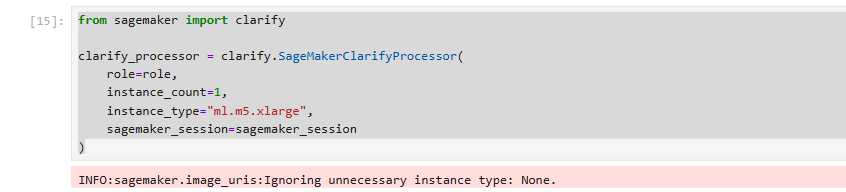
Để bắt đầu, chúng ta khởi tạo SageMakerClarifyProcessor, SageMakerClarifyProcessor sẽ tính toán số liệu sai lệch và giải thích mô hình:
from sagemaker import clarify
clarify_processor = clarify.SageMakerClarifyProcessor(
role=role,
instance_count=1,
instance_type="ml.m5.xlarge",
sagemaker_session=sagemaker_session
)
4.4 DataConfig: Setting Up Data for Bias Analysis
DataConfig thông báo cho SageMaker Clarify về dữ liệu được sử dụng để phân tích độ lệch:
bias_report_output_path = f"s3://{bucket}/{prefix}/clarify-bias"
bias_data_config = clarify.DataConfig(
s3_data_input_path=train_uri,
s3_output_path=bias_report_output_path,
label="loan_approved",
headers=training_data.columns.to_list(),
dataset_type="text/csv",
)
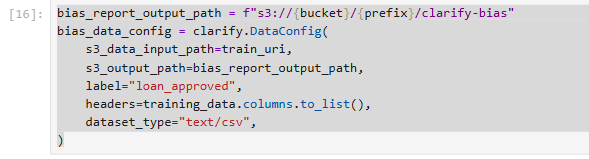
bias_report_output_path: Định nghĩa đường dẫn S3 nơi báo cáo phân tích thiên vị sẽ được lưu trữ.bias_data_config = clarify.DataConfig(...): Tạo một đối tượng cấu hình dữ liệu:s3_data_input_path: Đường dẫn S3 của dữ liệu đầu vào cần phân tíchs3_output_path: Chỉ ra đường dẫn S3 để lưu kết quả phân tích.label: Tên cột chứa biến mục tiêu ("loan_approved").headers: Danh sách các tên cột trong dữ liệu đầu vào (training_data.columns.to_list()).dataset_type: Kiểu của tập dữ liệu ("text/csv").
4.5 ModelConfig and ModelPredictedLabelConfig: Configuring the Model
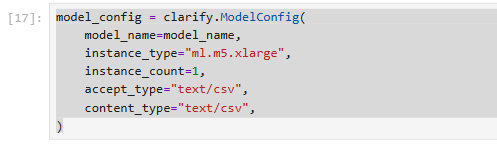
ModelConfig định nghĩa các chi tiết của mô hình đã được đào tạo:
model_config = clarify.ModelConfig(
model_name=model_name,
instance_type="ml.m5.xlarge",
instance_count=1,
accept_type="text/csv",
content_type="text/csv",
)
4.6 ModelPredictedLabelConfig sets up how SageMaker Clarify interprets the model’s predictions:
predictions_config =
clarify.ModelPredictedLabelConfig(probability_threshold=0.8)
probability_threshold=0.8 có nghĩa là nếu mô hình dự đoán xác suất cho một lớp là 0.8 trở lên, Clarify sẽ coi đó là dự đoán tích cực (hoặc là nhãn dự đoán cụ thể mà bạn quan tâm). Đây là ngưỡng để chuyển đổi xác suất dự đoán thành nhãn dự đoán nhị phân.
4.7 BiasConfig: Specifying Bias Parameters
BiasConfig được sử dụng để chỉ định các tham số cho việc phát hiện độ lệch:
bias_config = clarify.BiasConfig(
label_values_or_threshold=[1],
facet_name="gender",
facet_values_or_threshold=[0],
group_name="age"
)
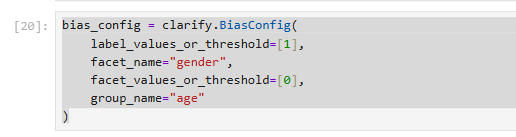
label_values_or_threshold=[1]: Chỉ ra giá trị của nhãn mục tiêu mà chúng ta coi là kết quả "tích cực" hoặc "mong muốn" (ví dụ: khoản vay được phê duyệt, ở đây là giá trị số 1).facet_name="gender": Xác định thuộc tính nhạy cảm mà chúng ta muốn kiểm tra thiên vị. Trong trường hợp này là giới tính.facet_values_or_threshold=[0]: Chỉ ra giá trị (hoặc ngưỡng) của thuộc tính nhạy cảm mà chúng ta coi là nhóm "bị bảo vệ" hoặc "thiểu số" (ví dụ: giới tính được mã hóa là 0). Clarify sẽ so sánh kết quả giữa nhóm này và các nhóm khác.group_name="age": Xác định một thuộc tính bổ sung (age - tuổi) để tạo các nhóm con trong facet (gender) để phân tích sâu hơn về thiên vị theo từng nhóm tuổi.
4.8 Running Bias Report Processing
Cuối cùng, cchạy phân tích độ lệch bằng SageMaker Clarify:
clarify_processor.run_bias(
data_config=bias_data_config,
bias_config=bias_config,
model_config=model_config,
model_predicted_label_config=predictions_config,
pre_training_methods="all",
post_training_methods="all",
)
data_config: Cấu hình về dữ liệu đầu vào.bias_config: Các tham số định nghĩa các thuộc tính nhạy cảm và nhóm để phân tích thiên vị.model_config: (Không hiển thị trong đoạn code này, nhưng giả định đã được định nghĩa ở đâu đó) Cấu hình về mô hình cần phân tích.model_predicted_label_config: Cấu hình về cách Clarify diễn giải các nhãn dự đoán của mô hình.pre_training_methods="all": Chỉ định rằng Clarify sẽ chạy tất cả các phương pháp phát hiện thiên vị "trước huấn luyện" (tức là phân tích thiên vị trong dữ liệu thô).post_training_methods="all": Chỉ định rằng Clarify sẽ chạy tất cả các phương pháp phát hiện thiên vị "sau huấn luyện" (tức là phân tích thiên vị trong dự đoán của mô hình).
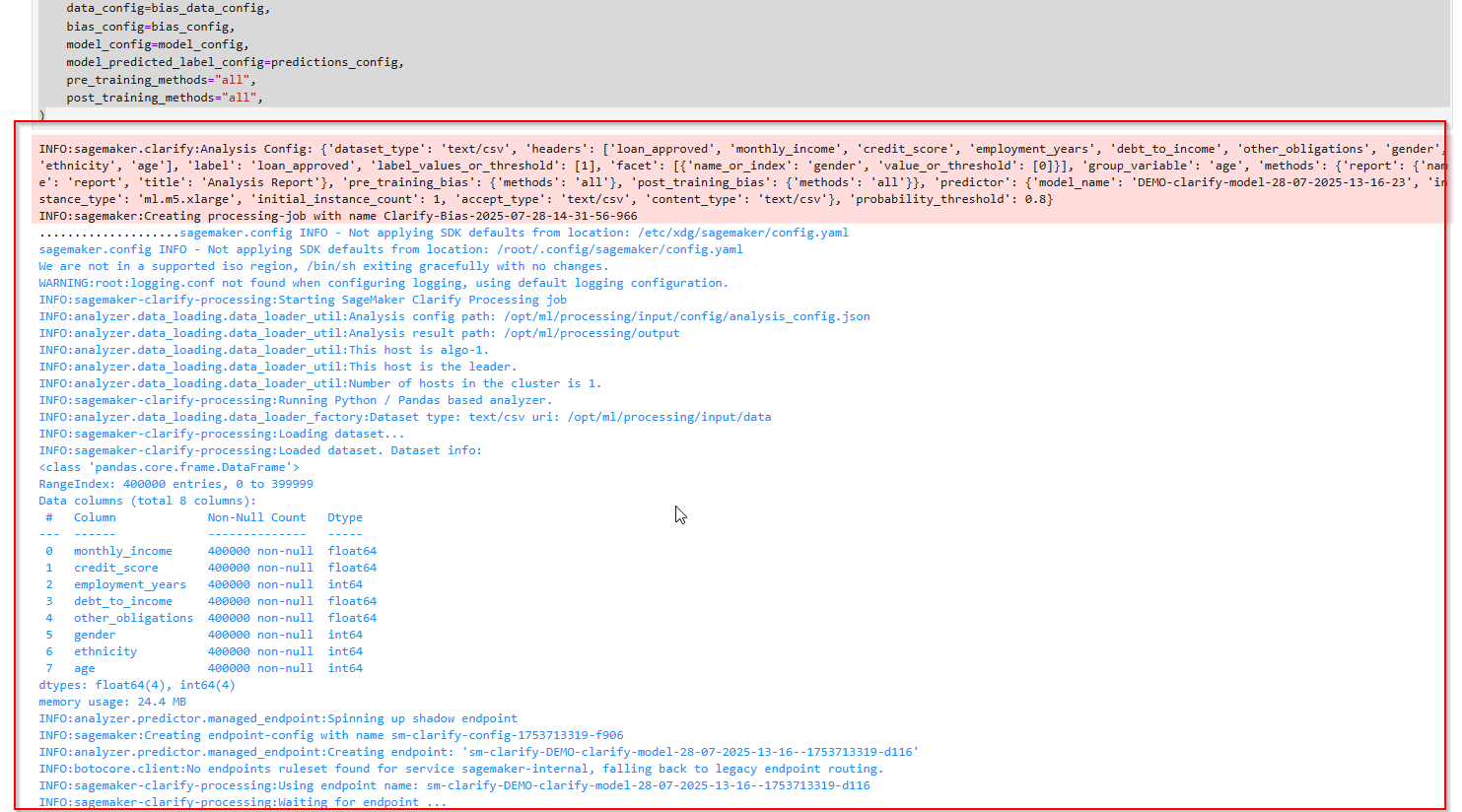
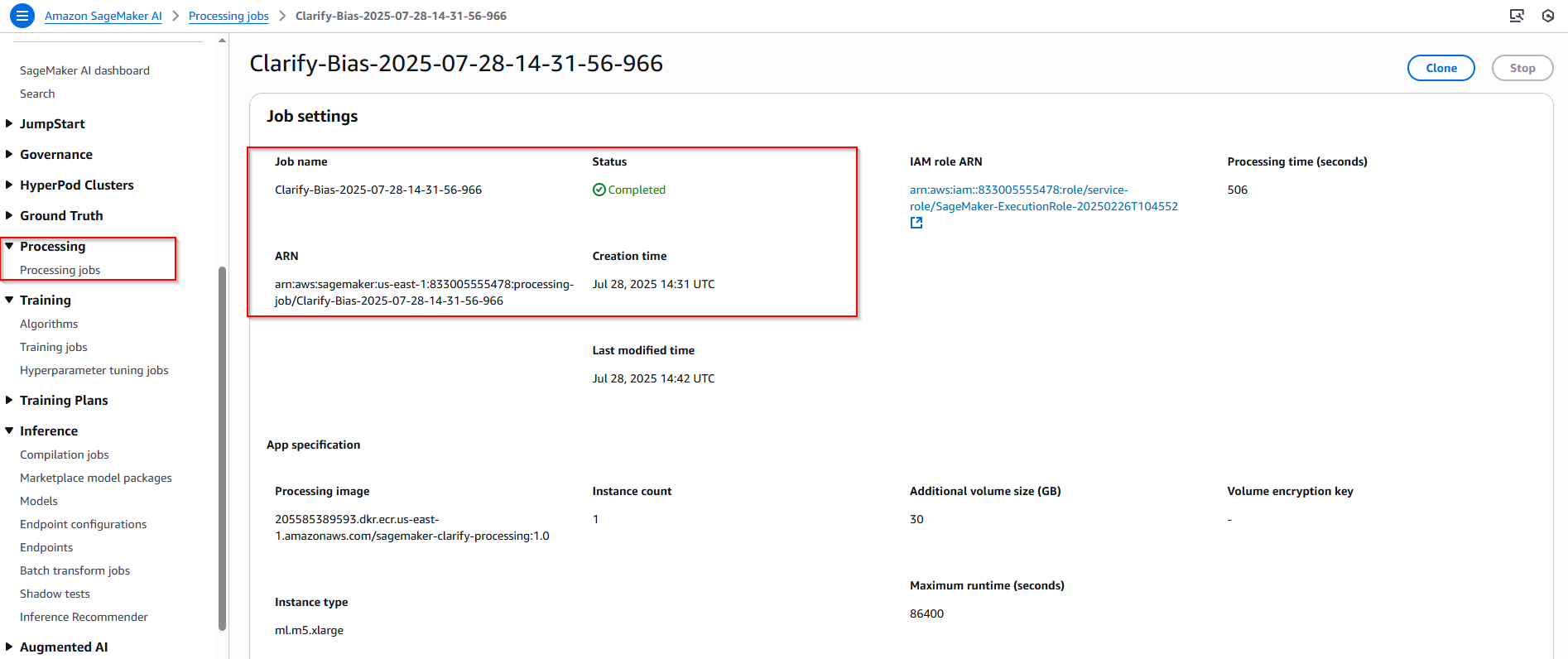
4.9 Viewing the Bias Report
Sau khi chạy phân tích SageMaker Clarify, bạn có thể xem kết quả báo cáo sai lệch đường link sau:
print(bias_report_output_path)

File report được lưu tại S3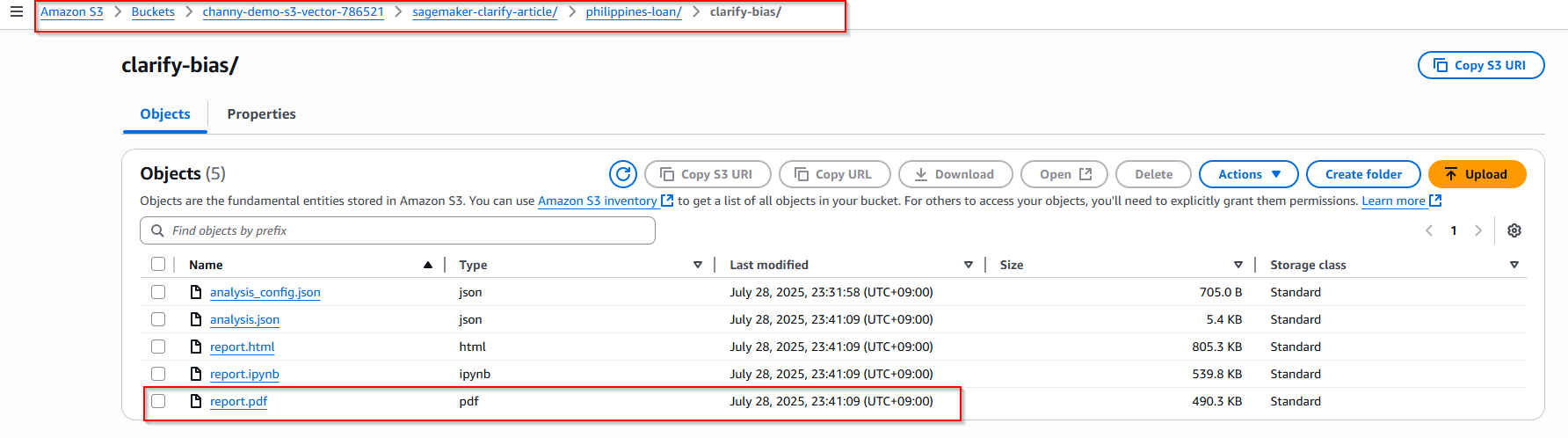
4.10 Report Overview

Báo cáo thiên vị của Amazon SageMaker Clarify rất toàn diện, được cấu trúc thành nhiều phần khác nhau:
- Cấu hình phân tích (Analysis Configuration): Phần này trình bày chi tiết cấu hình được sử dụng cho phân tích thiên vị, bao gồm cột nhãn kết quả, khía cạnh (thuộc tính quan tâm để phân tích thiên vị), và một biến nhóm tùy chọn.
- Các chỉ số hiệu suất mô hình cấp cao (High Level Model Performance): Phần này của báo cáo cung cấp các chỉ số cho thấy hiệu suất của mô hình, chẳng hạn như độ chính xác (accuracy), tỷ lệ dương tính thật (true positive rate hay recall), và tỷ lệ dương tính giả (false positive rate hay precision).
- Các chỉ số thiên vị trước huấn luyện (Pre-training Bias Metrics): Các chỉ số này đo lường sự mất cân bằng trong biểu diễn các giá trị khía cạnh (ví dụ: giới tính) trong dữ liệu huấn luyện. Nhiều chỉ số khác nhau, như Độ chênh lệch nhân khẩu học có điều kiện trong nhãn (Conditional Demographic Disparity in Labels - CDDL), Mất cân bằng lớp (Class Imbalance - CI), và Sự khác biệt về tỷ lệ nhãn (Difference in Proportions of Labels - DPL), cung cấp cái nhìn sâu sắc về mức độ cân bằng hoặc mất cân bằng của dữ liệu huấn luyện liên quan đến khía cạnh.
- Các chỉ số thiên vị sau huấn luyện (Post-training Bias Metrics): Phần này đo lường sự mất cân bằng trong các dự đoán của mô hình trên các đầu vào khác nhau. Các chỉ số như Sự khác biệt về độ chính xác (Accuracy Difference - AD), Độ chênh lệch nhân khẩu học có điều kiện trong nhãn dự đoán (Conditional Demographic Disparity in Predicted Labels - CDDPL), và Tác động không cân xứng (Disparate Impact - DI) giúp hiểu liệu các dự đoán của mô hình có công bằng giữa các nhóm khác nhau được xác định bởi khía cạnh (ví dụ: giới tính) hay không.
5. Amazon SageMaker Clarify - Explaining Predictions with Kernel SHAP
Trong lĩnh vực học máy, đặc biệt là trong các ứng dụng có tác động xã hội quan trọng như mô hình phê duyệt khoản vay trogn ngân hàng trong Finance, mô hình dự đoán ung thư trong Healthcare,... việc hiểu "lý do tại sao" đằng sau quyết định của mô hình cực kì quan trọng.
Kernel SHAP là một phương pháp trong học máy được sử dụng để giải thích các dự đoán của mô hình. Amazon SageMaker Clarify sử dụng Kernel SHAP (Shapley Additive exPlanations) để làm rõ sự đóng góp của từng tính năng riêng lẻ vào quyết định cuối cùng.
5.1 Explainability Report Configuration
explainability_output_path = f"s3://{bucket}/{prefix}/clarify-explainability"
explainability_data_config = clarify.DataConfig(
s3_data_input_path=train_uri,
s3_output_path=explainability_output_path,
label="loan_approved",
headers=training_data.columns.to_list(),
dataset_type="text/csv",
)
baseline = [training_data.mean().iloc[1:].values.tolist()]
shap_config = clarify.SHAPConfig(
baseline=baseline,
num_samples=15,
agg_method="mean_abs",
save_local_shap_values=True,
)
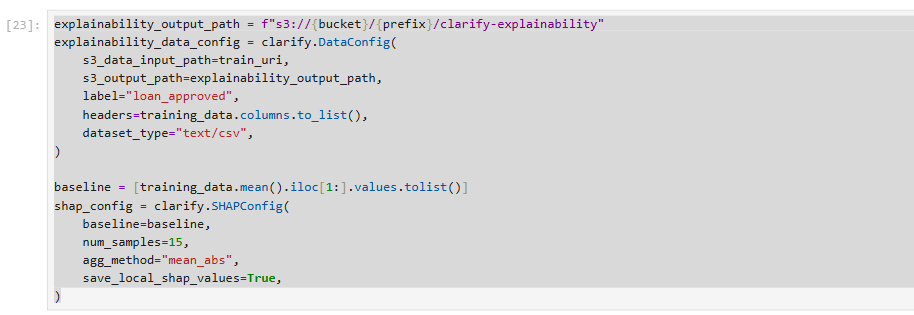
Cấu hình SHAPConfig với các tham số sau:
- Baseline: Thuật toán Kernel SHAP yêu cầu một bộ dữ liệu cơ sở hoặc dữ liệu nền để tham chiếu. Dữ liệu cơ sở này có thể là một bộ dữ liệu được xác định trước hoặc được tính toán tự động bằng các phương pháp như K-means.
- Num_samples: Tham số này quyết định số lượng mẫu dữ liệu tổng hợp được sử dụng để tính toán giá trị SHAP. Việc lựa chọn con số này có thể cân bằng giữa hiệu quả tính toán và độ trung thực của các giải thích.
- Agg_method: Tham số này đề cập đến phương pháp được sử dụng để tổng hợp các giá trị SHAP global. Chúng tôi sử dụng 'mean_abs', phương pháp này tính giá trị trung bình của các giá trị SHAP tuyệt đối trên tất cả các trường hợp, cung cấp một thước đo tác động tổng thể của mỗi tính năng.
- Save_local_shap_values: Khi được đặt thành True, tùy chọn này sẽ lưu các giá trị SHAP cục bộ trong vị trí đầu ra, cho phép kiểm tra chi tiết các đóng góp của tính năng cho các dự đoán cá nhân.
5.2 Running Explainability Report Processing
Gọi đến phương thức run_explainability để chạy job phân tích giải thích quết định từ mô hình, mất khoảng 10-15 phút:
clarify_processor.run_explainability(
data_config=explainability_data_config,
model_config=model_config,
explainability_config=shap_config,
)
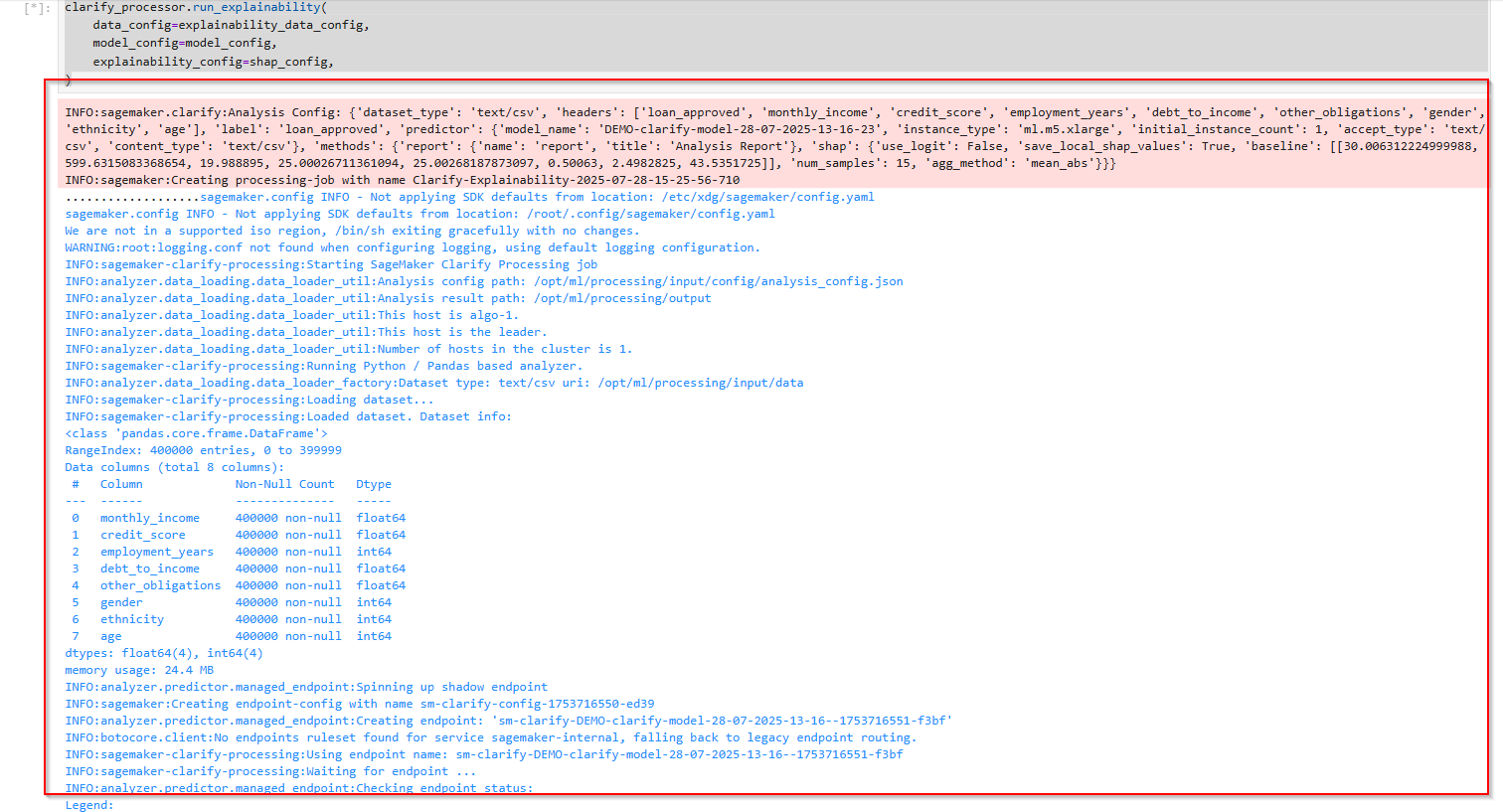
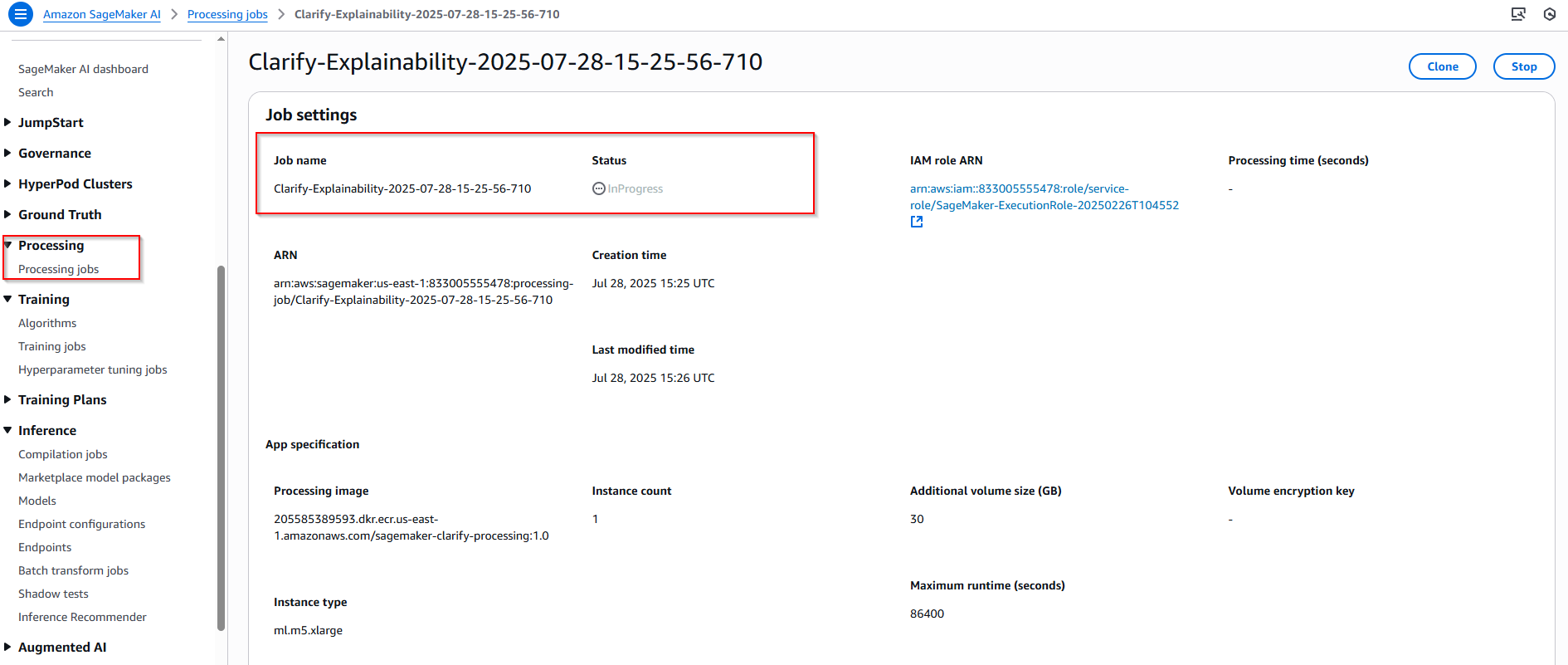
5.3 Viewing the Explainability Report
Báo cáo Giải thích (Explainability Report) do SageMaker Clarify tạo ra cung cấp một cái nhìn sâu sắc về cách các đặc trưng khác nhau ảnh hưởng đến dự đoán của mô hình. Báo cáo này bao gồm:
- Giải thích mô hình (Model Explanations): Biểu đồ cung cấp các giải thích SHAP cho từng nhãn riêng lẻ, nêu chi tiết sự đóng góp của từng trong số 8 đặc trưng trong mô hình.
- Biểu đồ này hiển thị mức độ quan trọng tổng thể của từng đặc trưng đối với mô hình.
- Trục tung liệt kê các đặc trưng (ví dụ: gender, age, credit_score,...)
- Trục hoành biểu thị Giá trị SHAP toàn cầu (Global SHAP Value). Giá trị càng lớn, đặc trưng đó càng có ảnh hưởng mạnh mẽ đến quyết định cuối cùng của mô hình.
- Ví dụ: Trong biểu đồ, đặc trưng "gender" (giới tính) có giá trị SHAP cao nhất, cho thấy đây là đặc trưng có ảnh hưởng mạnh mẽ nhất đến dự đoán của mô hình. Ngược lại, "employment_years" (số năm làm việc) có ảnh hưởng yếu nhất.
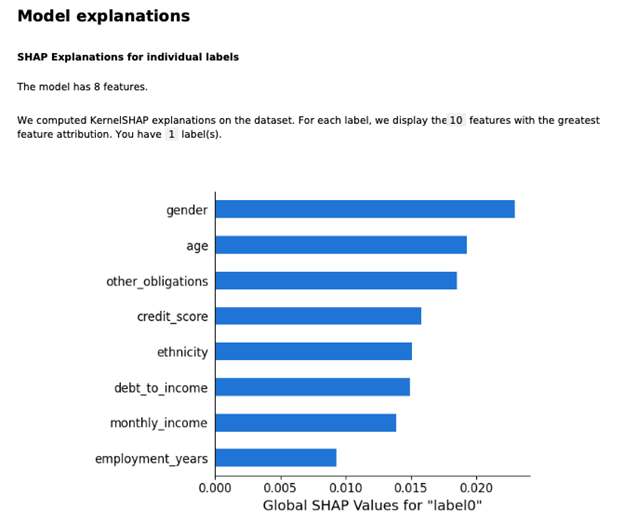
- Trực quan hóa giá trị SHAP (Visualization of SHAP Values): Biểu đồ này cho thấy ảnh hưởng cụ thể của từng đặc trưng lên từng trường hợp dữ liệu riêng lẻ. Mỗi dòng tương ứng với một đặc trưng, và mỗi chấm tròn nhỏ đại diện cho một trường hợp dự đoán.
- Trục hoành biểu thị Giá trị SHAP cục bộ (Local SHAP Value):
- Giá trị SHAP dương (chấm nằm bên phải trục 0) cho thấy đặc trưng đó đang đẩy dự đoán theo hướng tích cực hơn (ví dụ: tăng khả năng được phê duyệt khoản vay).
- Giá trị SHAP âm (chấm nằm bên trái trục 0) cho thấy đặc trưng đó đang đẩy dự đoán theo hướng tiêu cực hơn.
- Màu sắc của chấm tròn biểu thị giá trị của đặc trưng đó:
- Màu đỏ thường biểu thị giá trị cao của đặc trưng (ví dụ: tuổi cao, thu nhập cao).
- Màu xanh thường biểu thị giá trị thấp của đặc trưng (ví dụ: tuổi thấp, thu nhập thấp).
- Ví dụ về cách đọc biểu đồ:
- Đối với đặc trưng "gender" (giới tính), các chấm màu xanh chủ yếu nằm ở bên trái (giá trị SHAP âm), trong khi các chấm màu đỏ chủ yếu nằm ở bên phải (giá trị SHAP dương). Điều này có nghĩa là một giới tính có giá trị thấp (màu xanh) thường có xu hướng làm giảm khả năng dự đoán, trong khi giới tính có giá trị cao (màu đỏ) lại làm tăng khả năng dự đoán.
- Đối với "age" (tuổi), các chấm màu xanh (tuổi thấp) tập trung ở bên trái, và các chấm màu đỏ (tuổi cao) tập trung ở bên phải. Điều này cho thấy tuổi càng cao, càng có xu hướng làm tăng dự đoán của mô hình.
Clean up resources
- Xóa SageMaker notebook
- Xóa S3 bucket
- Xóa SageMaker model





