Data Pipeline - AWS Glue for ETL, Integrating Athena for Querying the Processed Data
Lab Introduction
- AWS experience: Intermediate
- Time to complete: 35 minutes
- AWS Region: US East (N. Virginia) us-east-1
- Cost to complete: Free Tier eligible or 1-2$
- Services used: Amazon S3, Amazon Glue, Amazon Athena
Example Scenario Details
Bạn đang làm việc cho một công ty bán lẻ và có dữ liệu bán hàng trong tệp CSV được lưu trữ trên một bucket S3. Dữ liệu này bao gồm các cột như: card_id, price, product_id và timestamp. Cột customer_price chứa giá dưới dạng chuỗi có ký hiệu đô la (ví dụ: $34.56). Bạn cần xử lý dữ liệu này và loại bỏ ký hiệu đô la khỏi giá để cho đội Analytics phân tích thống kê cuối năm.
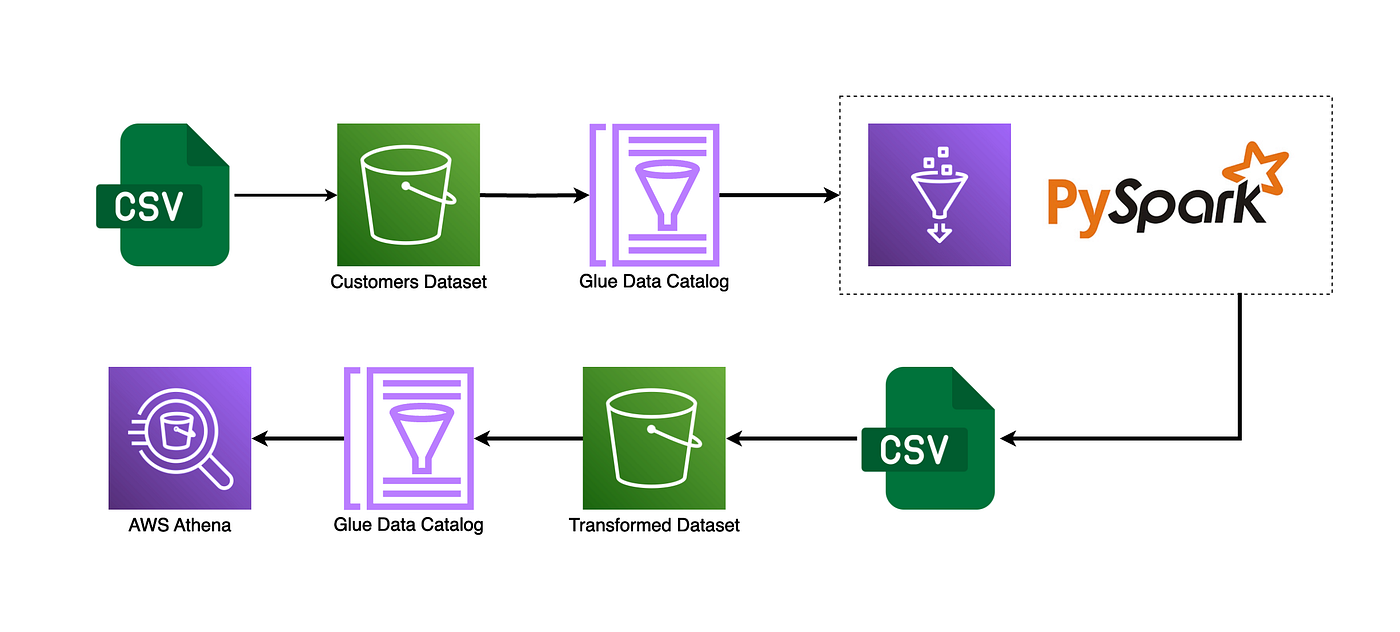
Architecture Diagram
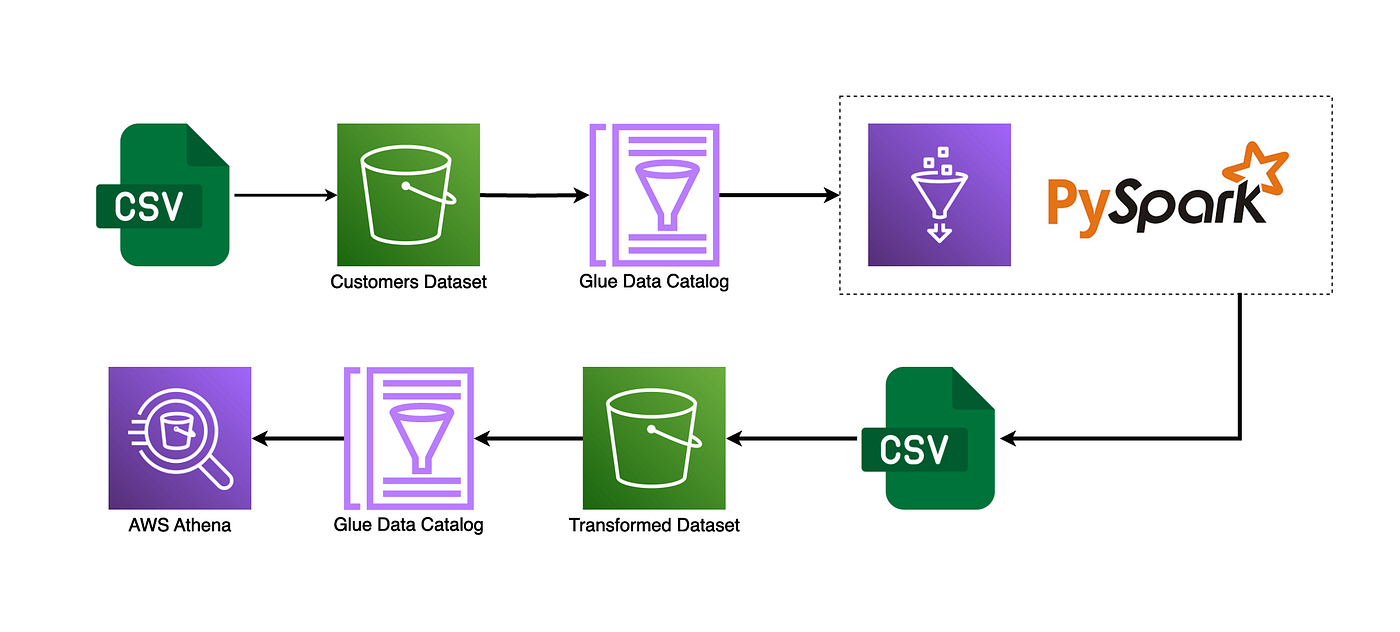
- Người dùng tải file csv dữ liệu thô vào S3 bucket, ở folder /input/
- Glue Crawler dùng data source ở S3 folder /input/, crawl data vào database -> sẽ tạo ra table catalog chứa thông tin dữ liệu thô.
- ETL job thực hiện chuyển đổi, làm sạch dữ liệu.
- File csv đã được làm sạch sẽ lưu vào S3 bucket, ở folder /output/
- Thực hiện Clawer dữ liệu từ file csv đã được xử lý -> sẽ tạo ra table catalog chứa thông tin dữ liệu sạch.
- Sử dụng Athena query từ table catalog chứa thông tin dữ liệu sạch.
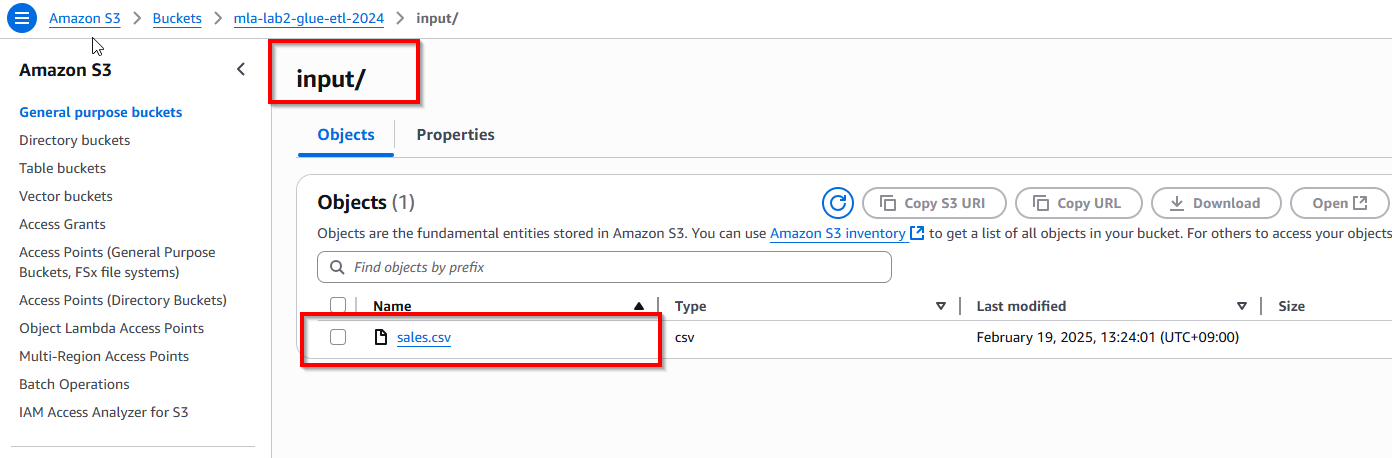
1. Chuẩn bị Dữ liệu trong S3
- Đăng nhập vào AWS Console và truy cập Amazon S3.
- Tạo một S3 bucket (nếu bạn chưa có) để lưu trữ dữ liệu đầu vào. Bạn có thể đặt tên là "mla-lab2-glue-etl-2024".
- Tải tệp CSV (sales.csv) lên một thư mục trong bucket. Giả sử tệp được lưu trong thư mục input/.
- Link download file: https://drive.google.com/file/d/1YZSZmQ9AjZnJlIYyMw_YEFjxTFtP1nG2/view?usp=sharing
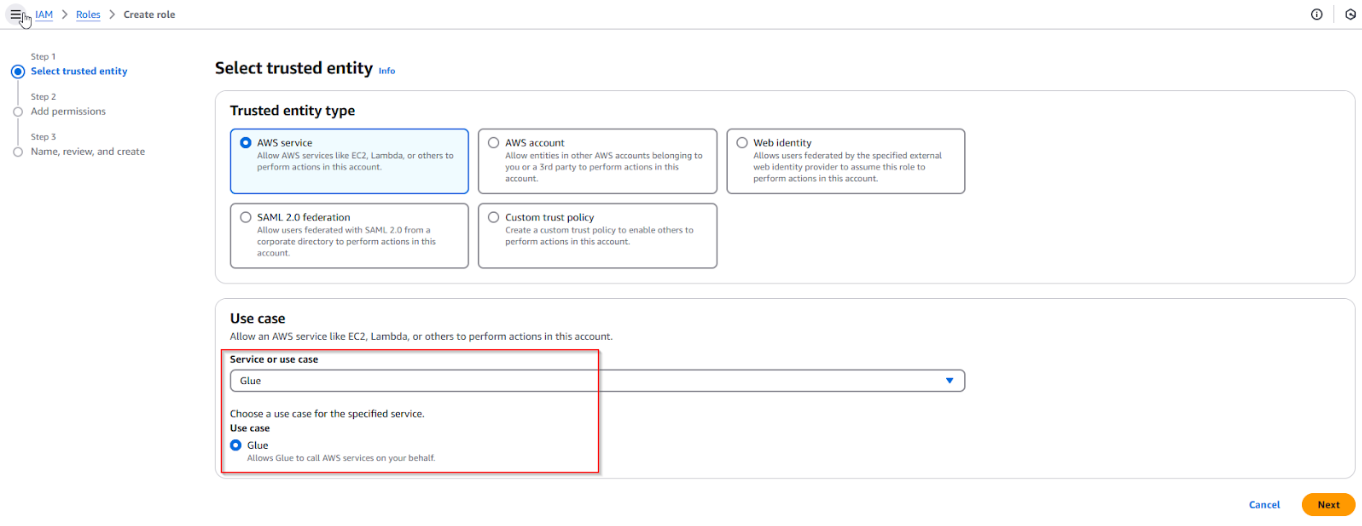
2. Thiết lập Môi trường AWS Glue
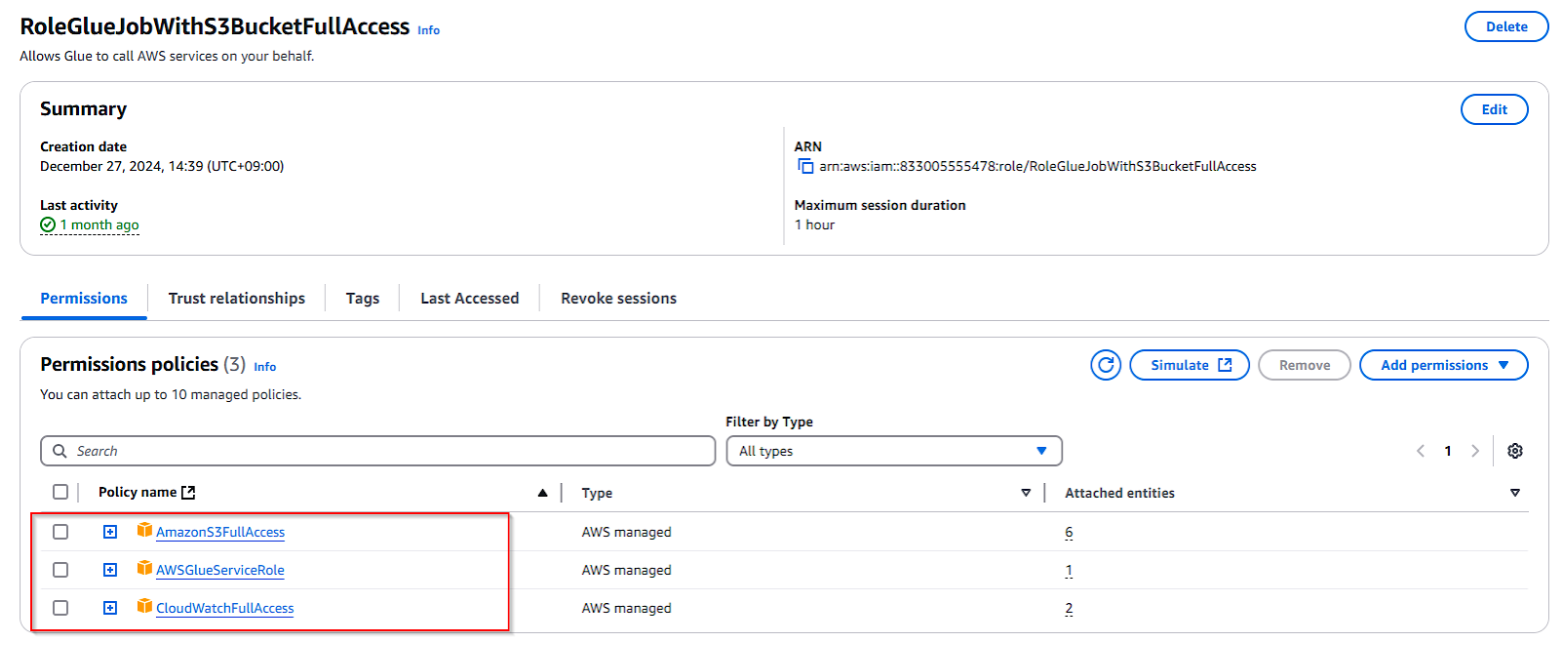
- Đăng nhập vào AWS Glue Console và tạo một IAM Role mới nếu bạn chưa có. Role có quyền truy cập vào S3, CloudWatch và AWS Glue. Ví dụ: RoleGlueJobWithS3BucketFullAccess
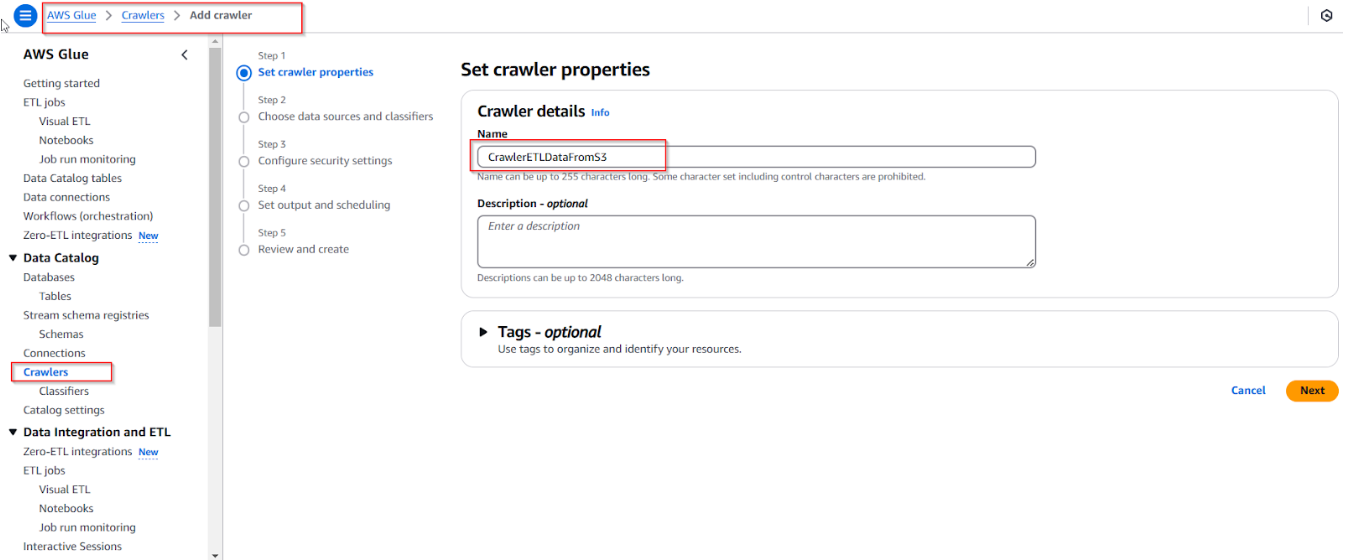
- Tạo Glue Crawler, nhập Crawler Name: 'CrawlerETLDataFromS3'. Sau đó chọn "Next"
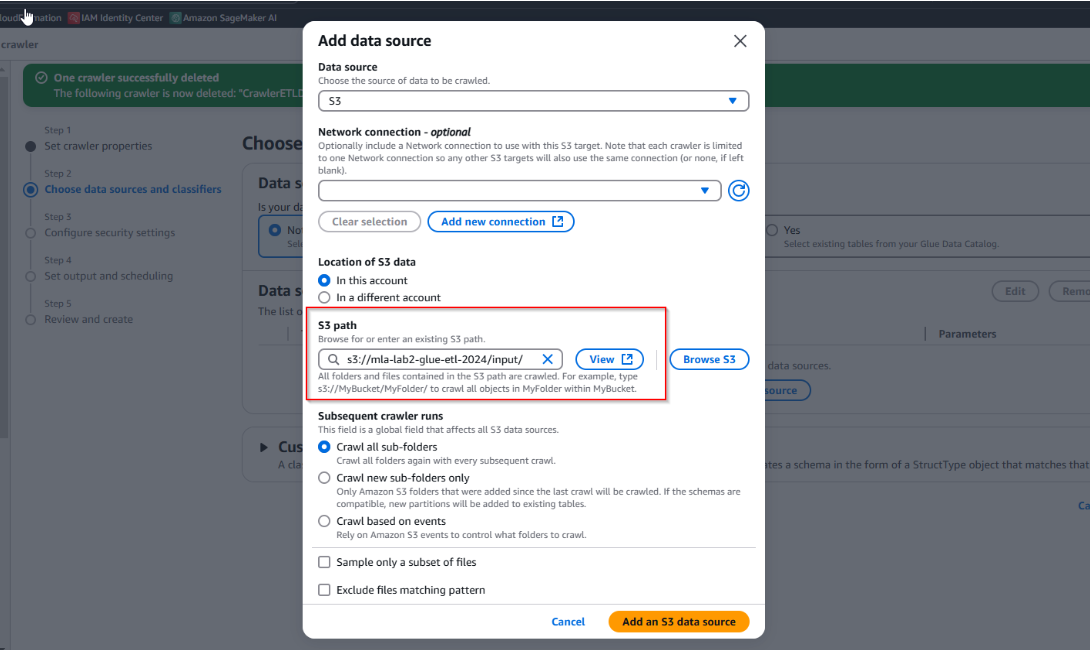
- Trong phần cấu hình Data Store, chọn đường dẫn S3 chứa file datasource: S3 input folder (s3://mla-lab2-glue-etl-2024/input/). Chọn nút "Add an S3 data source" => Tiếp theo, nhấn nút "Next".
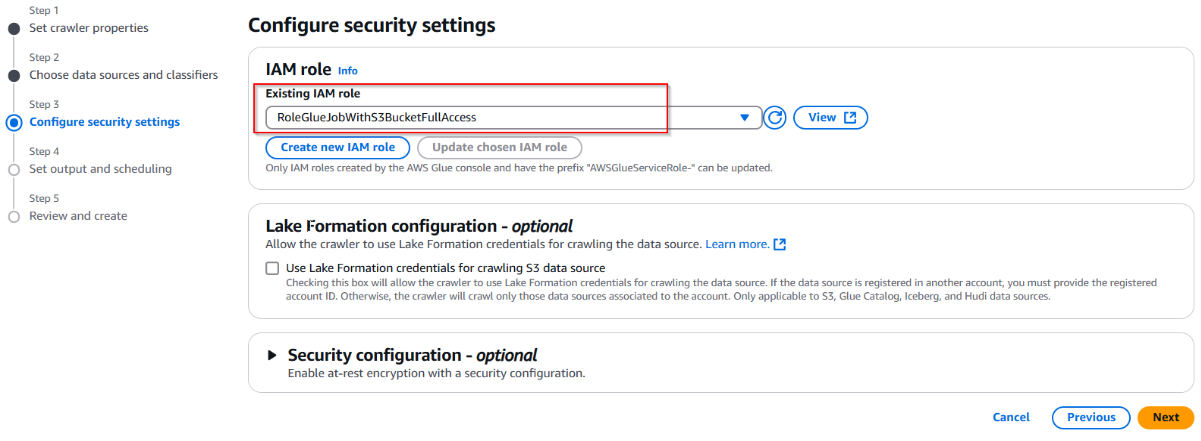
- Ở mục cấu hình IAM cho Glue, chọn role đã tạo ở trên => Tiếp theo, nhấn nút "Next".
- Chúng ta sẽ tạo một Database, dùng để lưu trữ các table sau khi Crawler. Nhấn nút "Add database" và nhập tên "Database name" is "glue-etl-sales-database" -> Cuối cùng, nhấn nút Create database
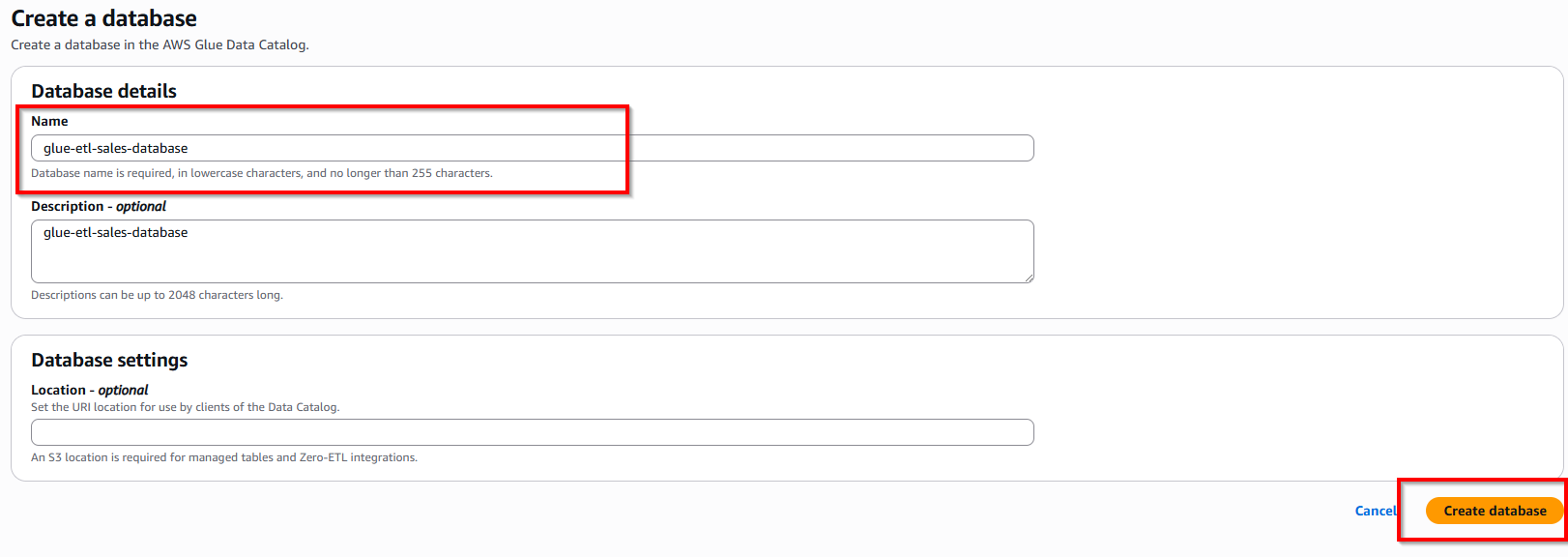
- Quay lại dịch vụ Glue, ở mục Target database, chọn database vừa tạo: glue-etl-database. Nhấn nút Next và chọn nút Create crawler.
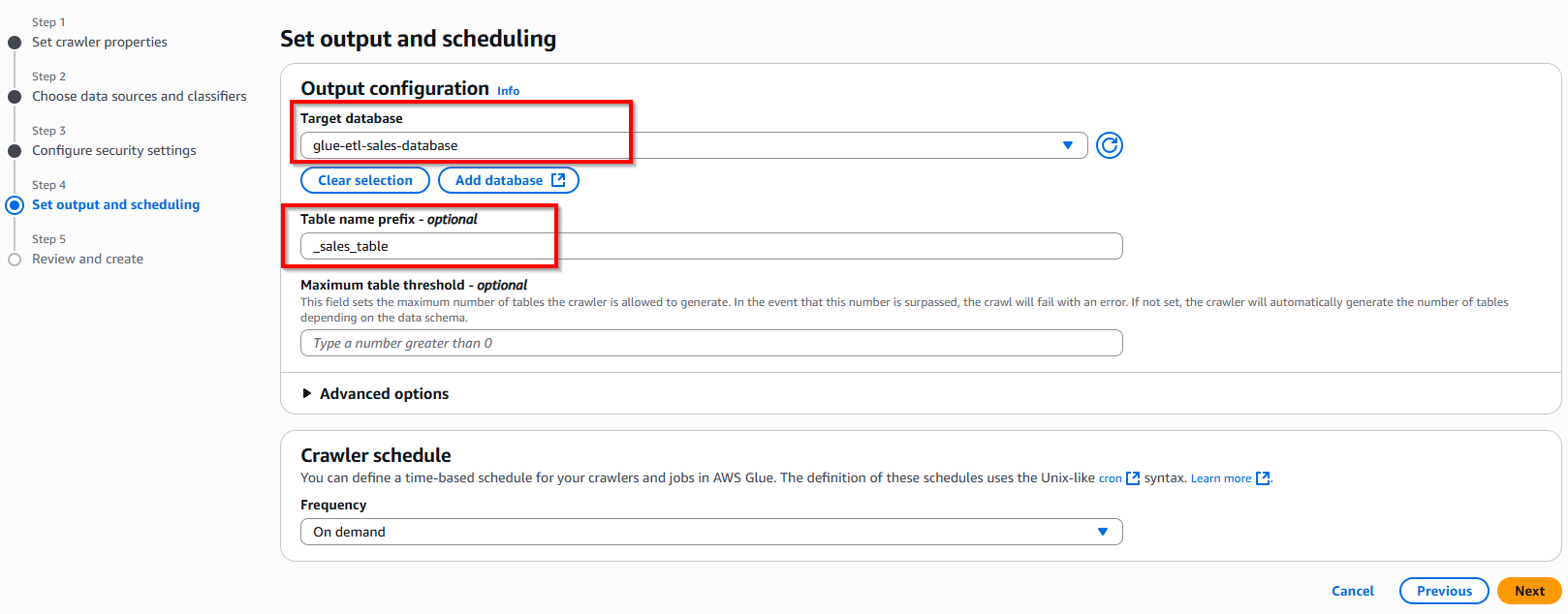
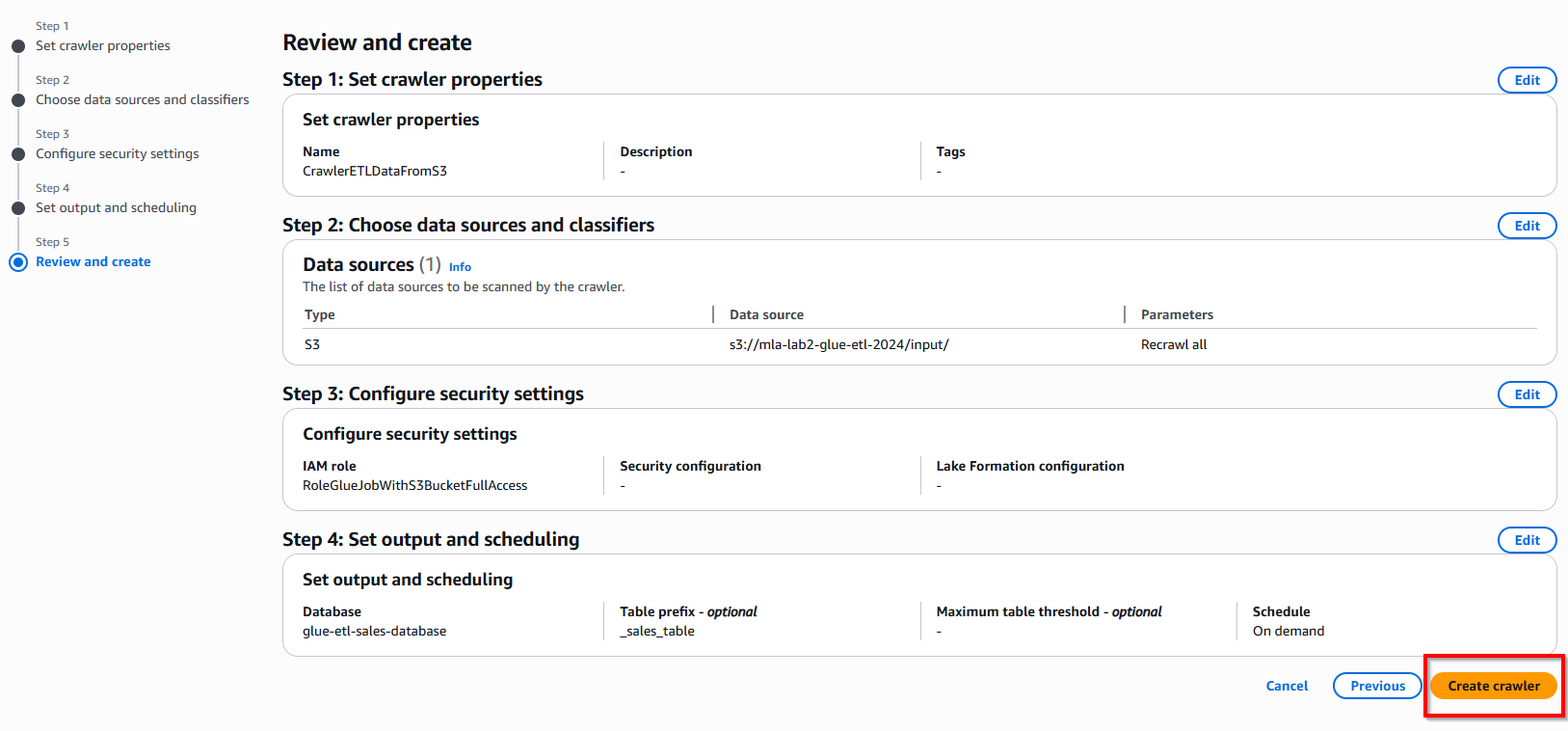
- Chọn nút Run Crawler góc phải trên cùng. Thao tác này sẽ tạo một bảng trong Glue ánh xạ tới cấu trúc tệp sales.csv.
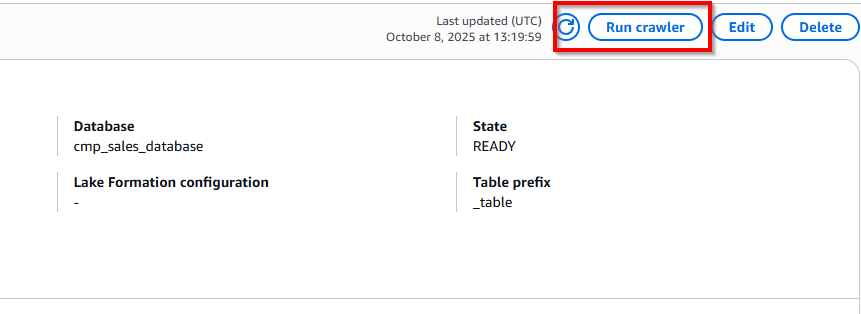

- Điều hướng đến AWS Glue và chọn Database, chọn table input - bạn có thể thấy cấu trúc cột table mapping tương ứng với file sales.csv
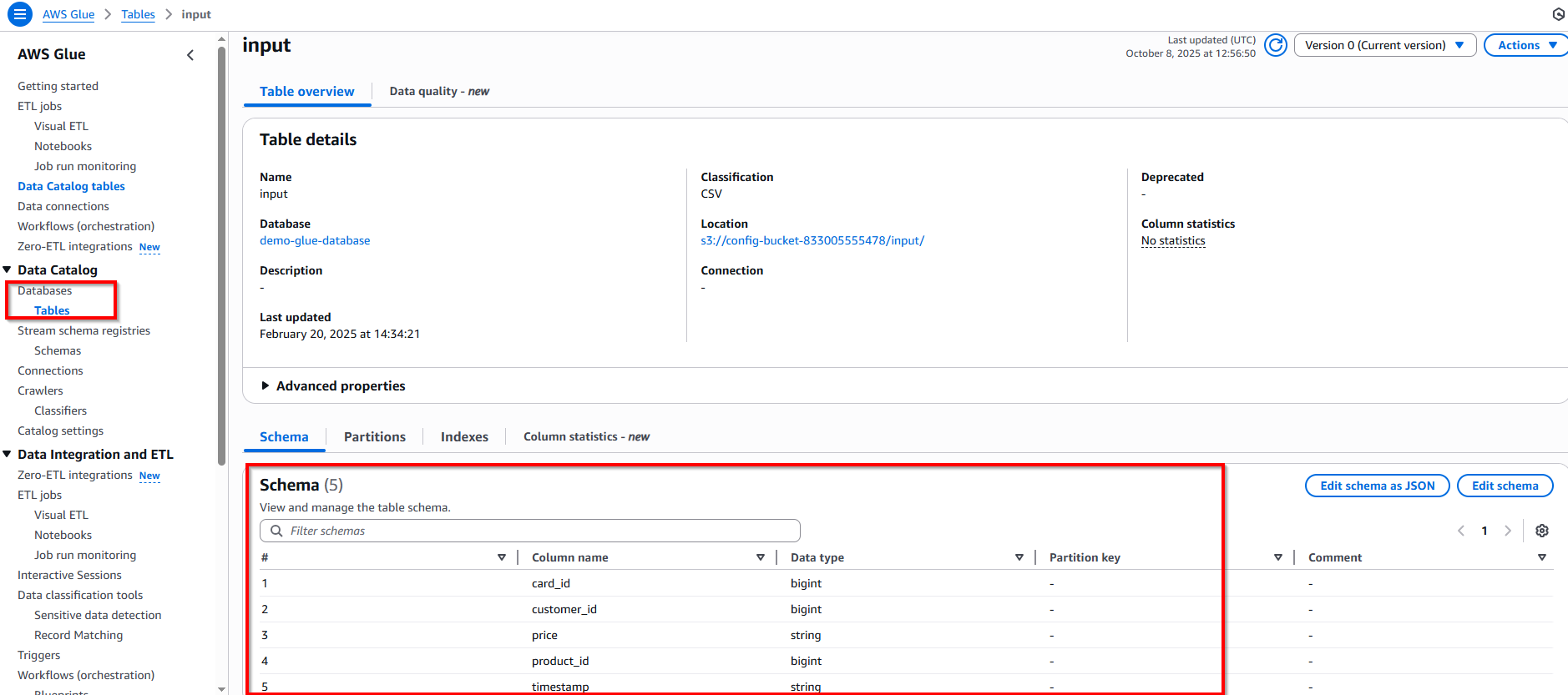
- Hiện tại, data trong bảng table input là dữ liệu thô, chưa được xử lý. Tiếp theo, chúng ta sẽ thực hiện bước xử lý làm sạch dữ liệu.
3. Tạo Glue Job dùng để làm sạch dữ liệu, cụ thể là xóa dấu $
Chúng ta sẽ tạo một Job, để thực hiện chuyển đổi ETL và lưu dữ liệu sau khi xử lý vào thư mục S3 mới. ( sử dụng cùng 1 bucket, nhưng tạo thêm 1 folder tên s3://mla-lab2-glue-etl-2024/ouput/ )
- Tại giao diện Glue Console, chọn mục Glue Job.
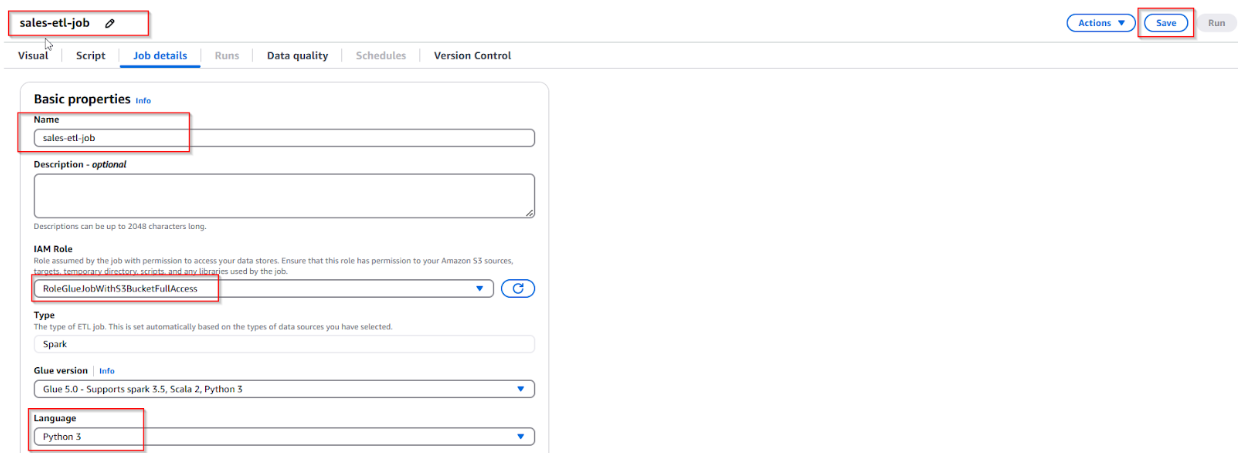
- Nhấn nút tạo Job và điền các thông tin cấu hình bên dưới:
- Name: sales-etl-job
- IAM Role: Choose the role created earlier. ( RoleGlueJobWithS3BucketFullAccess )
- Type: Select Spark (the default for large-scale ETL jobs).
- Script Language: Choose Python.
- Select button "Save"
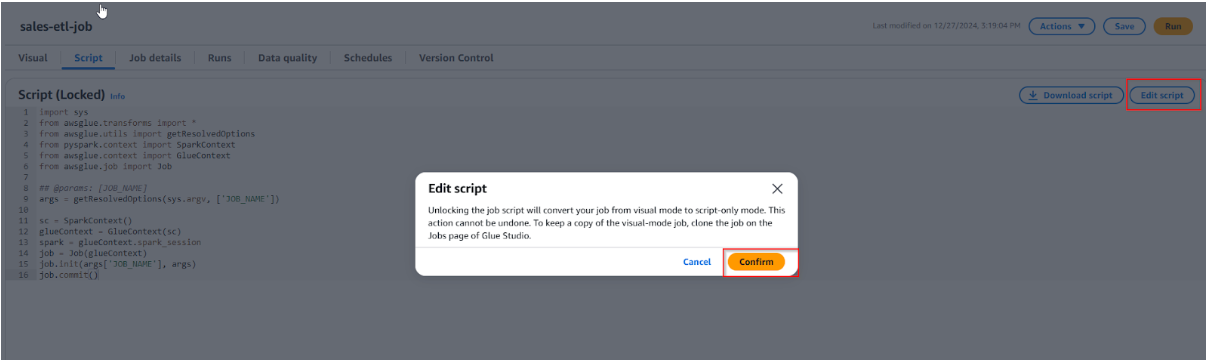
- In the Script Editor, AWS Glue will generate an auto-filled script, but we will modify it to perform our custom transformation. The main transformation is to remove the $ from the price column.
- Viết code xóa dấu $
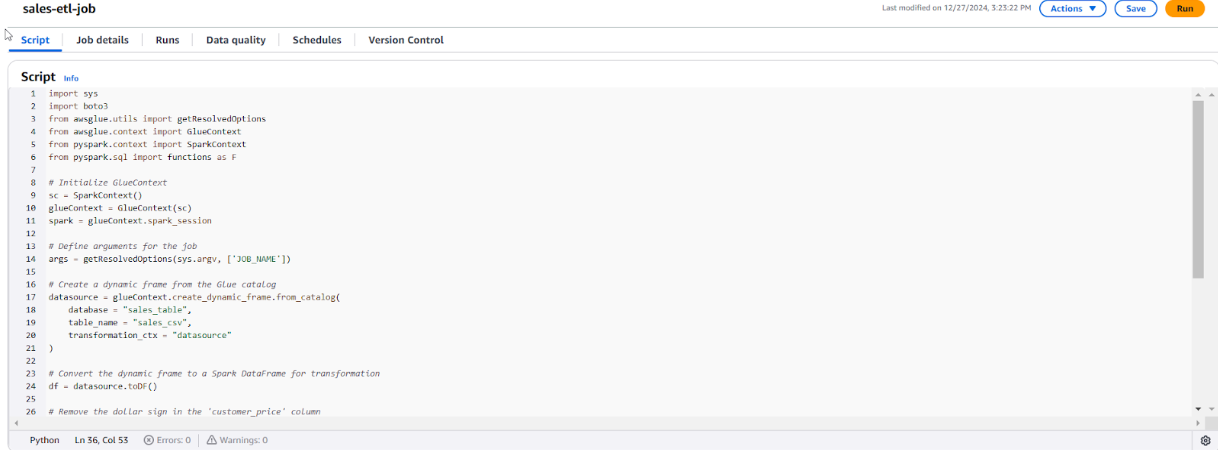
- Thay thế đoạn mã bên dưới và nhấn nút Save Script, cuối cùng nhấn nút Run. Lưu ý: Nếu bạn đặt tên database, table_name và output_path khác trong bài hướng dẫn thì cần phải replace lại các thông tin trong code bên dưới.
import sys
import boto3
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from pyspark.context import SparkContext
from pyspark.sql import functions as F
from awsglue.dynamicframe import DynamicFrame
# Initialize GlueContext
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
# Define arguments for the job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
# Create a dynamic frame from the Glue catalog
datasource = glueContext.create_dynamic_frame.from_catalog(
database = "sales_table",
table_name = "sales_csv",
transformation_ctx = "datasource"
)
# Convert the dynamic frame to a Spark DataFrame for transformation
df = datasource.toDF()
# Remove the dollar sign in the 'price' column
df_cleaned = df.withColumn(
'price',
F.regexp_replace(df['price'], r'\$', '').cast('float')
)
# Convert the DataFrame back to a DynamicFrame
dynamic_frame_cleaned = DynamicFrame.fromDF(df_cleaned, glueContext, "dynamic_frame_cleaned")
# Define the output S3 path
output_path = "s3://mla-lab2-glue-etl-2024/output/"
# Write the transformed data back to S3 as CSV
glueContext.write_dynamic_frame.from_options(
dynamic_frame_cleaned,
connection_type = "s3",
connection_options = {"path": output_path},
format = "csv"
)
4. Chạy Job ETL
- Theo dõi tiến trình của job trong mục Jobs của Glue Console.
- Sau khi hoàn tất, dữ liệu đã được xử lý (đã loại bỏ ký hiệu đô la $) sẽ được ghi vào trong S3 bucket của bạn (s3://mla-lab2-glue-etl-2024/output/).
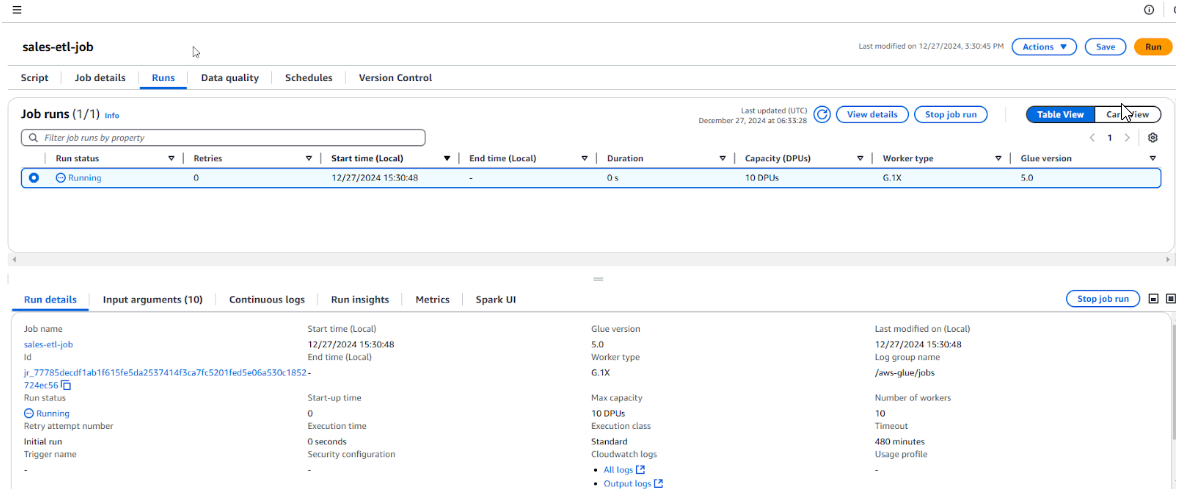
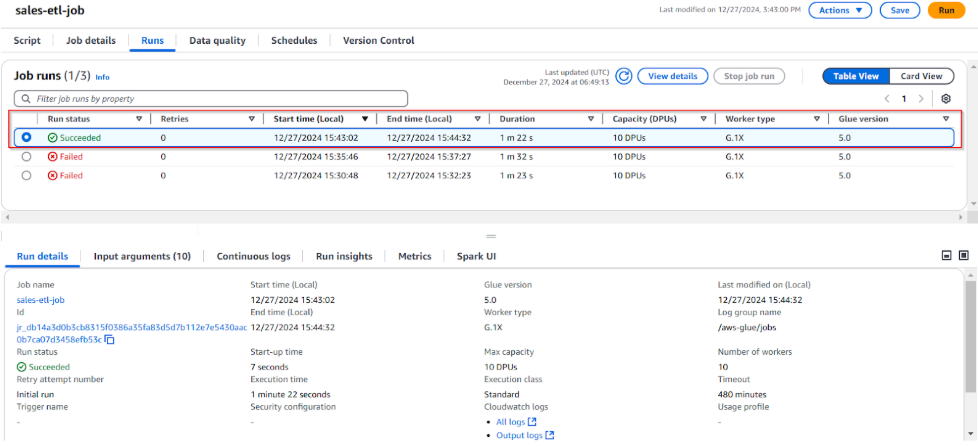
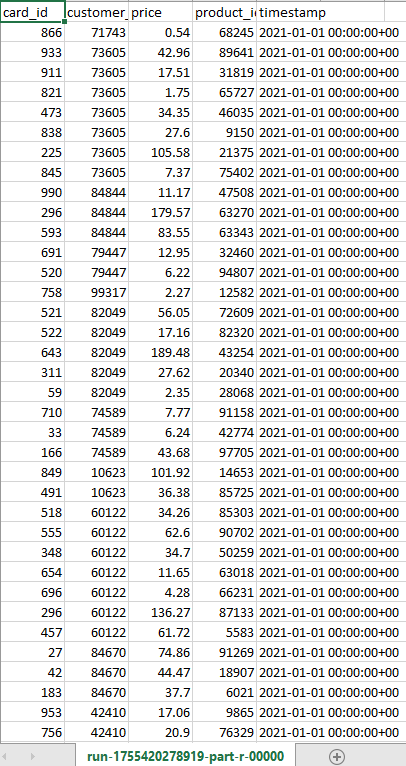
- Xác minh kết quả đã xóa dấu $. Truy cập Amazon S3 và đi tới thư mục s3://mla-lab2-glue-etl-2024/output/. Mở file CSV và kiểm tra cột giá (price column) không còn chứa ký hiệu đô la $, và các giá trị đã ở định dạng số.
5. Thực hiện Crawler data đã được xử lý và lưu vào table catalog để phân tích dữ liệu
- Thực hiện tương tự giống bước 2, nhưng mục Data Store, chúng ta sẽ chọn S3 input folder (s3://mla-lab2-glue-etl-2024/output/)
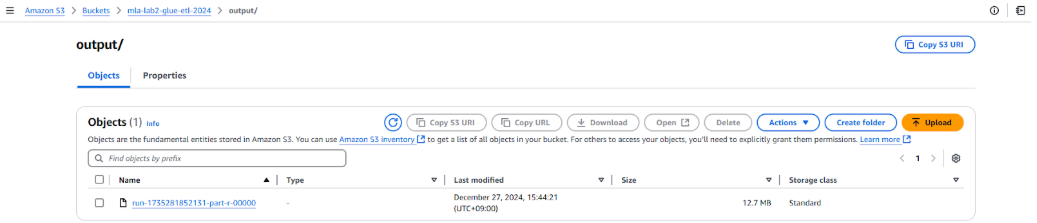
- Sau khi Crawler data thành công, chúng ta có table output chứa dữ liệu đã được xử lý.

6. Truy vấn dữ liệu trong bảng Data Catalog bằng AWS Athena
- Cấu hình kết nối Athena với bảng trong Data Catalog:
- Datasource: AwsDataSource
- Catelog: None
- Database: glue-etl-db
- Table: output
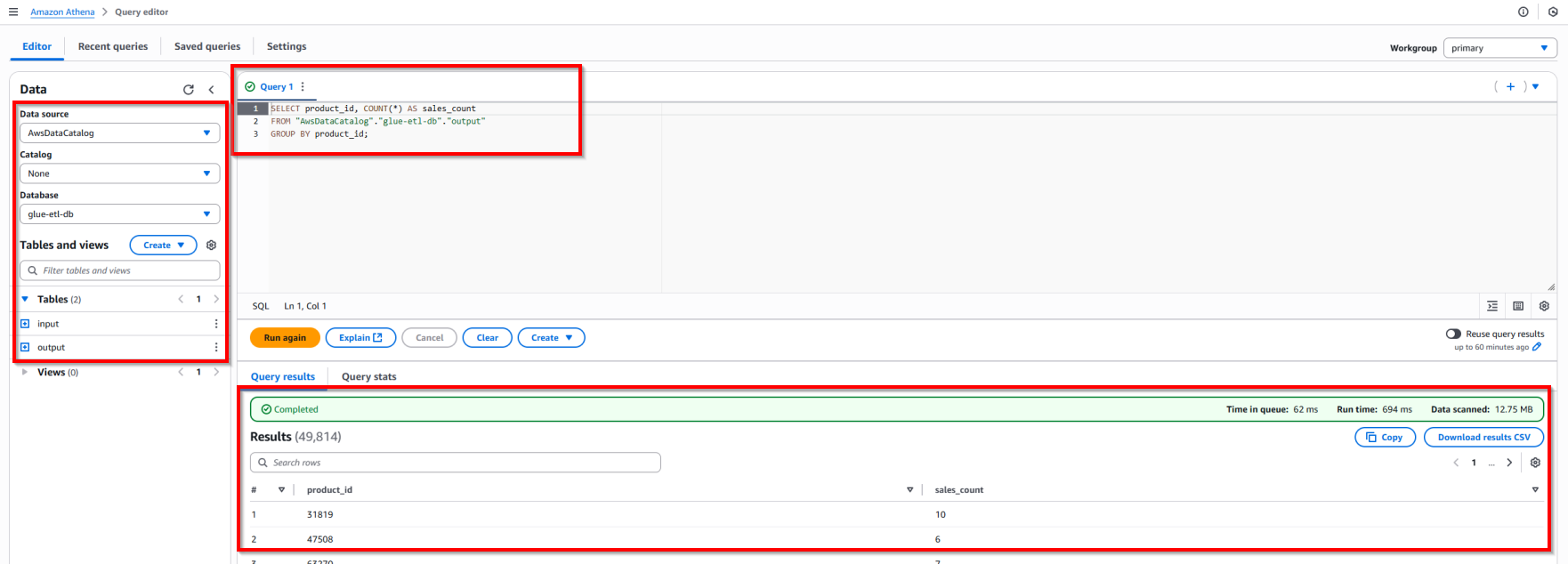
- Sau khi đã cấu hình xong bảng trong Athena, bạn có thể chạy các câu lệnh SQL trên dữ liệu đã xử lý.
- Truy vấn đếm số lượng sản phẩm bán ra (theo product_id):
SELECT product_id, COUNT(*) AS sales_count
FROM "AwsDataCatalog"."glue-etl-db"."output"
GROUP BY product_id;
- Tính Tổng Doanh Thu và Giá Trung Bình theo Khách Hàng (customer_price)
SELECT
customer_price,
COUNT(card_id) AS total_transactions,
SUM(product_price) AS total_revenue,
AVG(product_price) AS average_price_per_transaction
FROM
your_table_name -- Thay 'your_table_name' bằng tên bảng thực tế của bạn
GROUP BY
customer_price
HAVING
SUM(product_price) > 100
ORDER BY
total_revenue DESC;
- Tìm Giao Dịch Có Giá Cao Hơn Giá Trung Bình Của Toàn Bộ Dữ Liệu
SELECT
card_id,
customer_price,
product_price,
timestamp
FROM
your_table_name -- Thay 'your_table_name' bằng tên bảng thực tế của bạn
WHERE
product_price > (
SELECT
AVG(product_price)
FROM
your_table_name
)
ORDER BY
product_price DESC;

7. Clean up resources
- Xóa S3 bucket
- Xóa resource Glue