Lab Introduction
- AWS experience: Intermediate
- Time to complete: 35 minutes
- AWS Region: US East (N. Virginia) us-east-1
- Cost to complete: ~1-2$
- Services used: Bedrock, Amazon S3 Vectors
Architecture Diagram
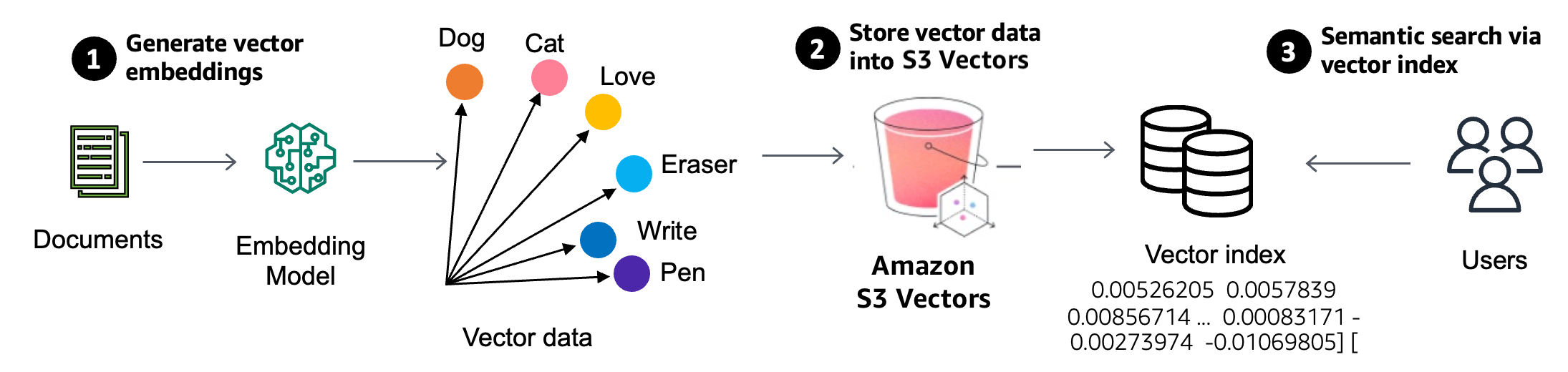
Amazon S3 Vectors, a purpose-built durable vector storage solution that can reduce the total cost of uploading, storing, and querying vectors by up to 90 percent.
Vector search is an emerging technique used in generative AI applications to find similar data points to given data by comparing their vector representations using distance or similarity metrics. Vectors are numerical representation of unstructured data created from embedding models. You use embedding models to generate vector embeddings of your data and store them in S3 Vectors to perform semantic searches.
Task Details
- Create Amazon S3 Vectors
- Create a new knowledge base
- Configure the data source
- Configure data source and processing
- Sync the data source
- Test the knowledge base
- Export S3 vector data to Amazon OpenSearch Service
Prerequisites
Enable model access for embedding and inference models such as Amazon Titan Text Embeddings V2 and FM Claude 3 Sonnet.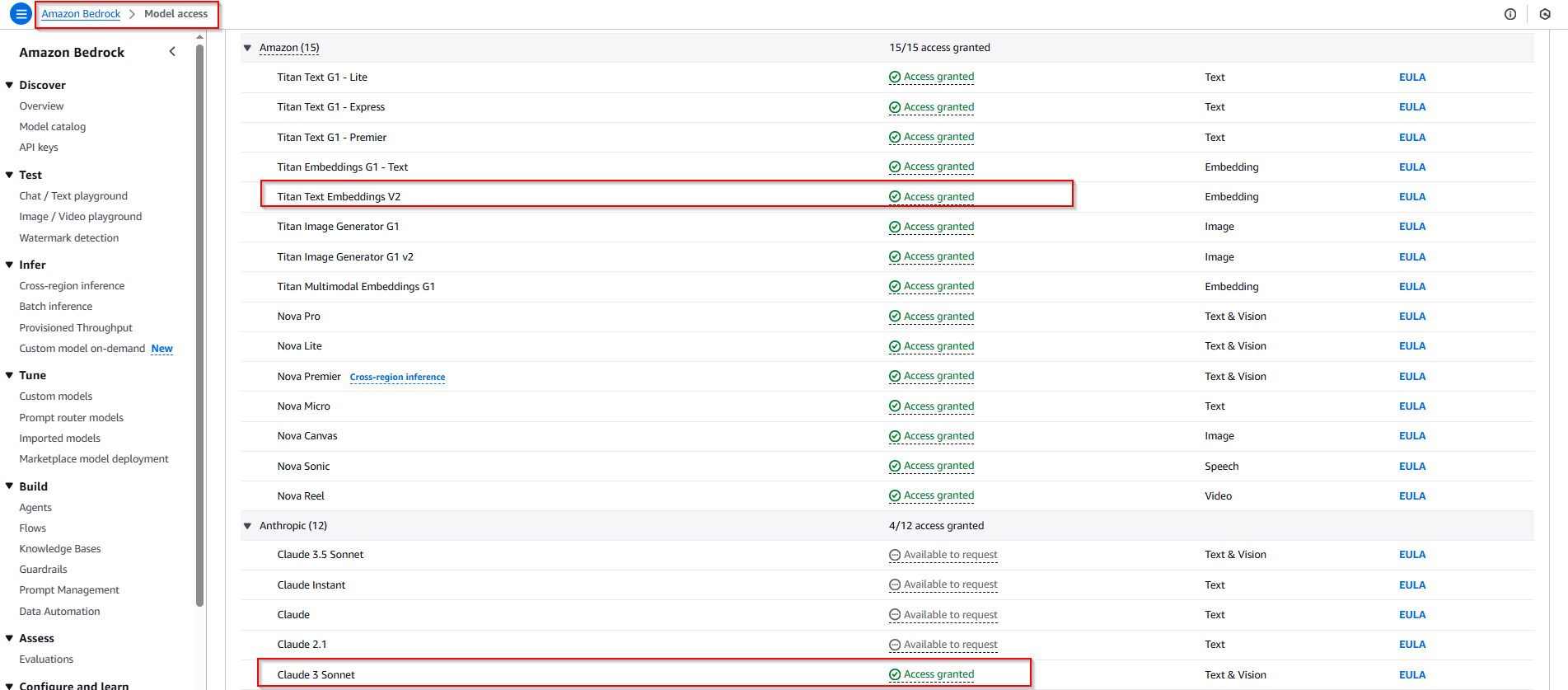
1. Create Amazon S3 Vectors
To create a vector bucket, choose Vector buckets in the left navigation pane in the Amazon S3 console and then choose Create vector bucket.
Enter a vector bucket name and choose the encryption type. If you don’t specify an encryption type, Amazon S3 applies server-side encryption with Amazon S3 managed keys (SSE-S3) as the base level of encryption for new vectors.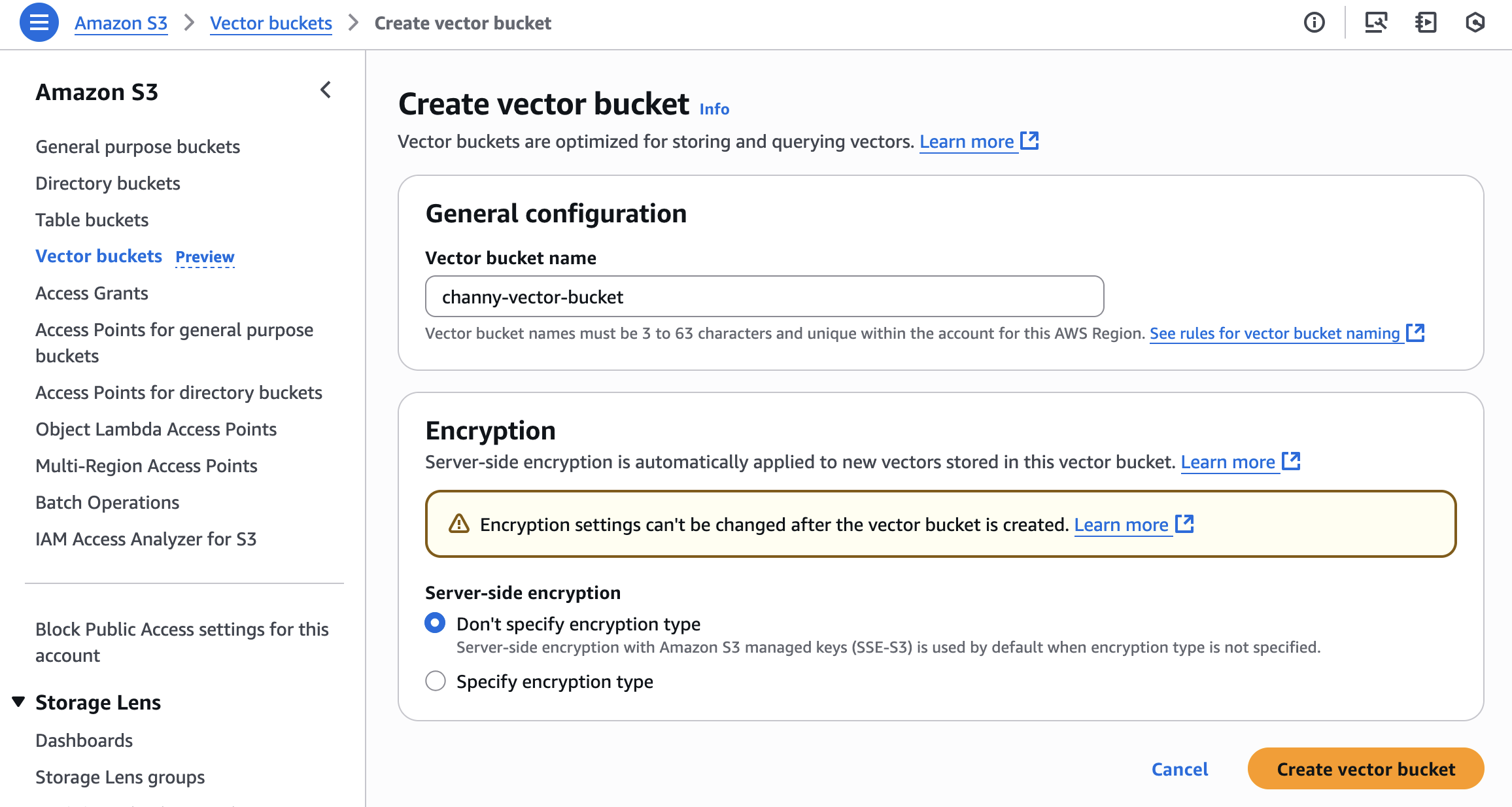
Now, you can create a vector index to store and query your vector data within your created vector bucket.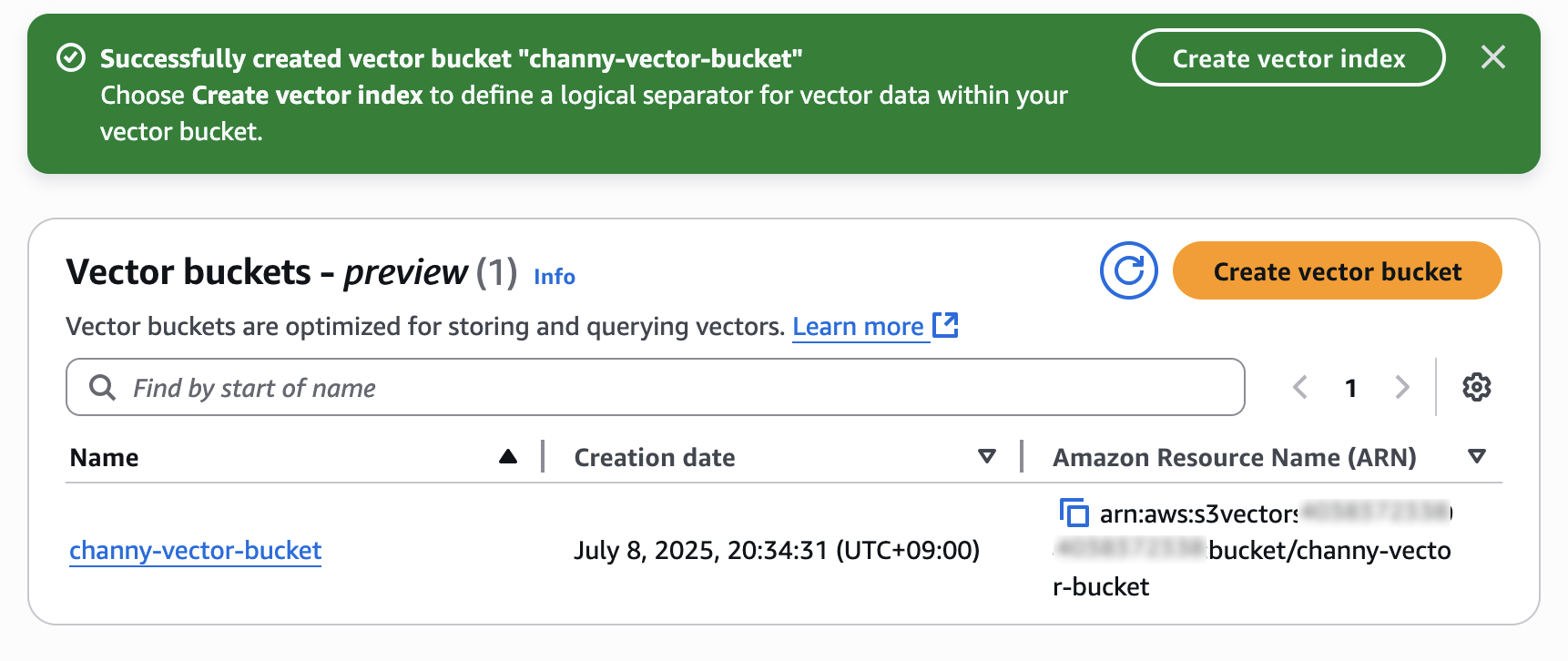
Enter a vector index name and the dimensionality of the vectors to be inserted in the index. All vectors added to this index must have exactly the same number of values.
For Distance metric, you can choose either Cosine or Euclidean. When creating vector embeddings, select your embedding model’s recommended distance metric for more accurate results.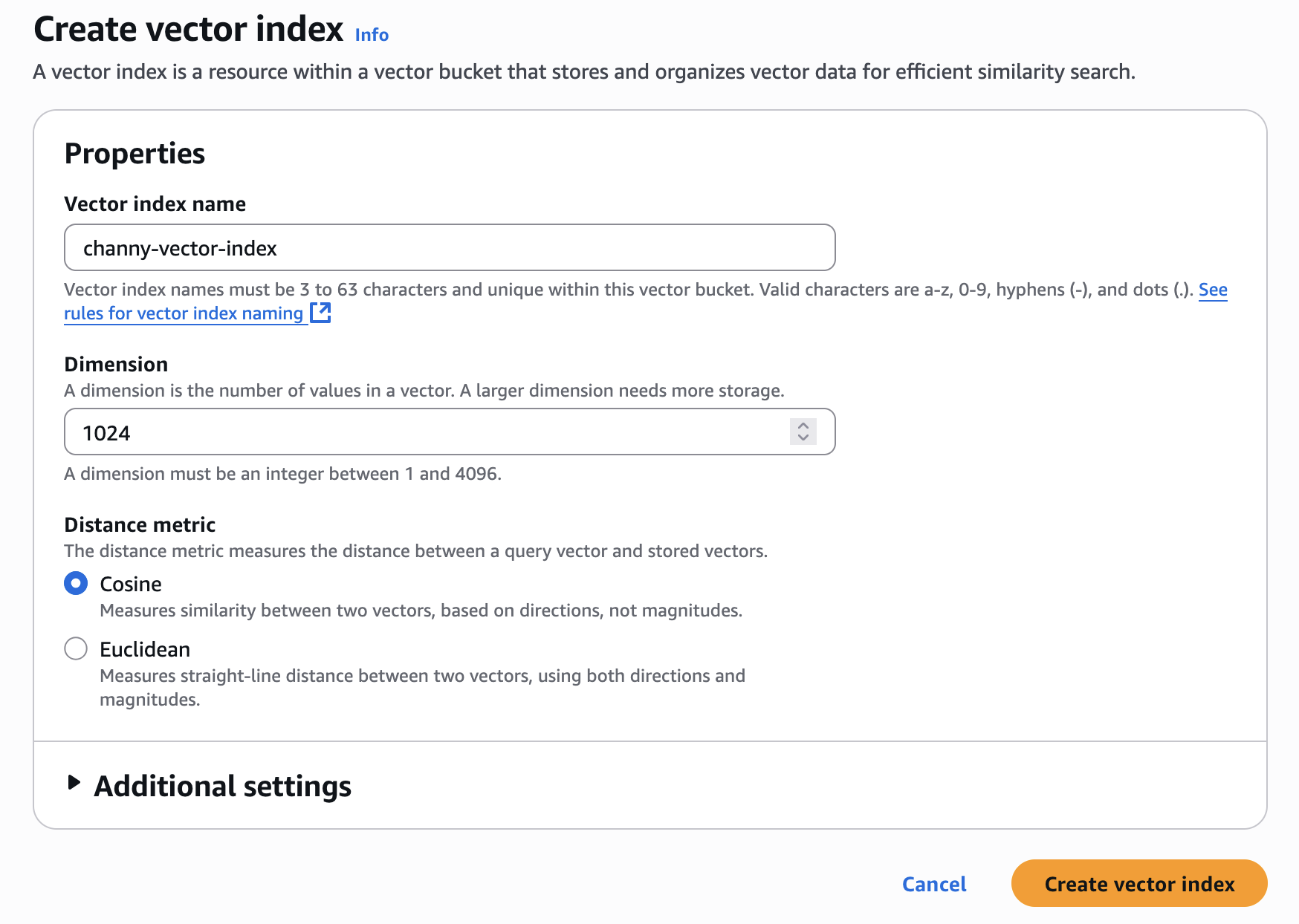
Choose Create vector index and then you can insert, list, and query vectors.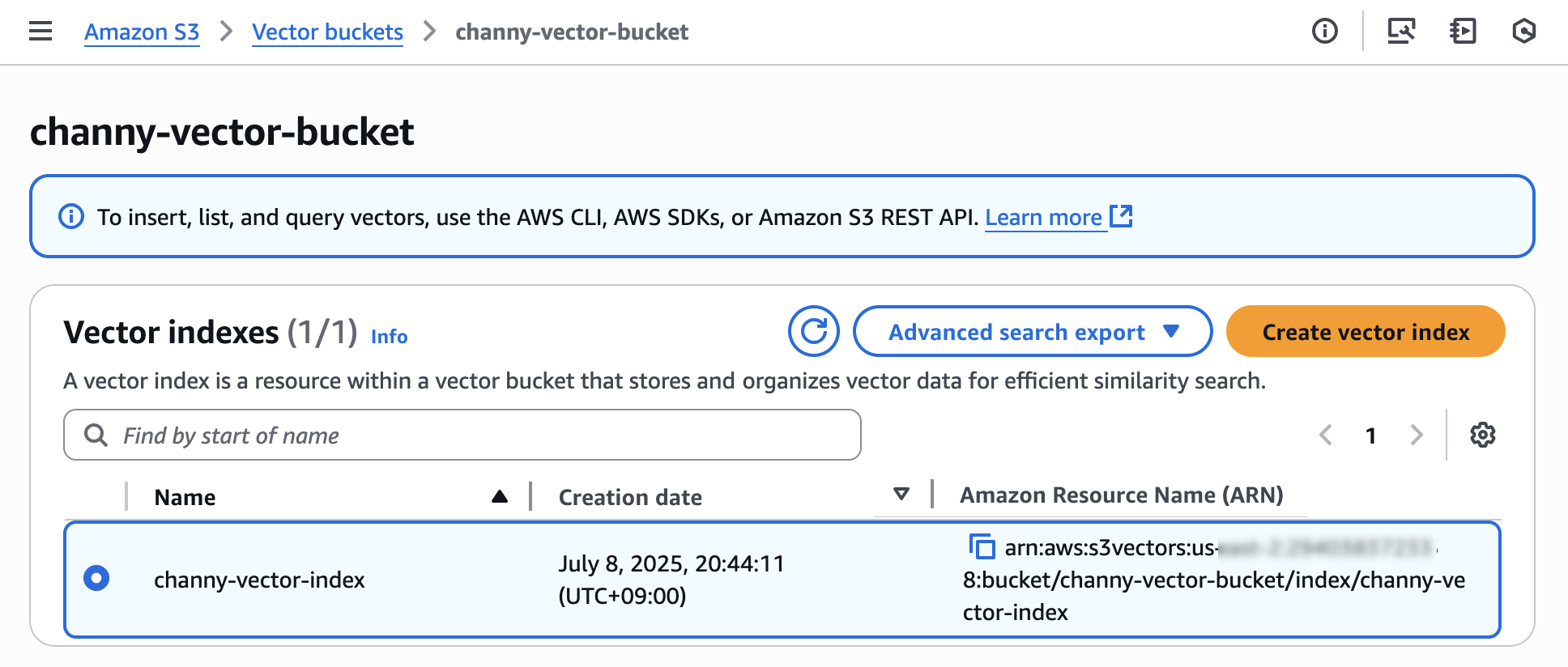
2. Create a new knowledge base
- On the Amazon Bedrock console in the left navigation pane, choose Knowledge Bases. To initiate the creation process, in the Create dropdown list, choose Knowledge Base with vector store.
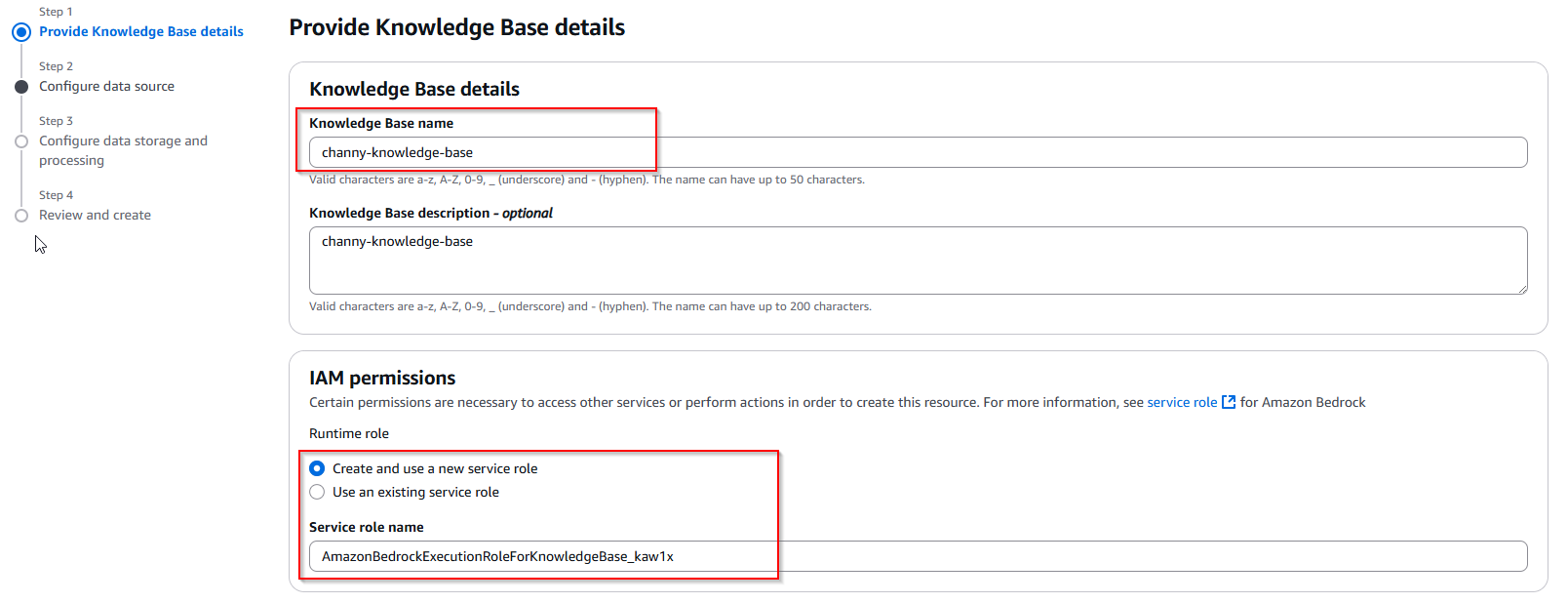
- On the Provide Knowledge Base details page, enter a descriptive name for your knowledge base and an optional description to identify its purpose.
- Choose Amazon S3. Optionally, add tags to help organize and categorize your resources and configure log delivery destinations such as an S3 bucket or Amazon CloudWatch for monitoring and troubleshooting.
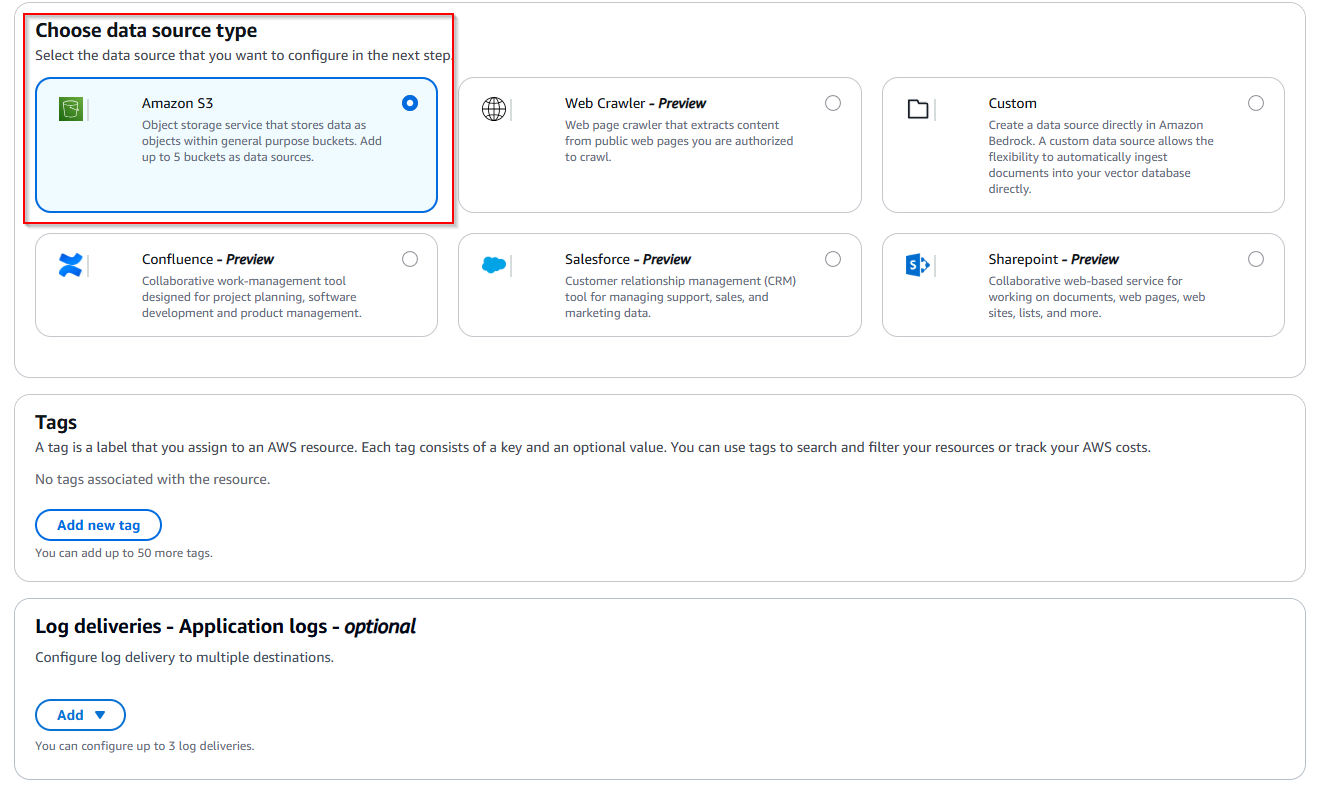
- Choose Next to proceed to the data source configuration.
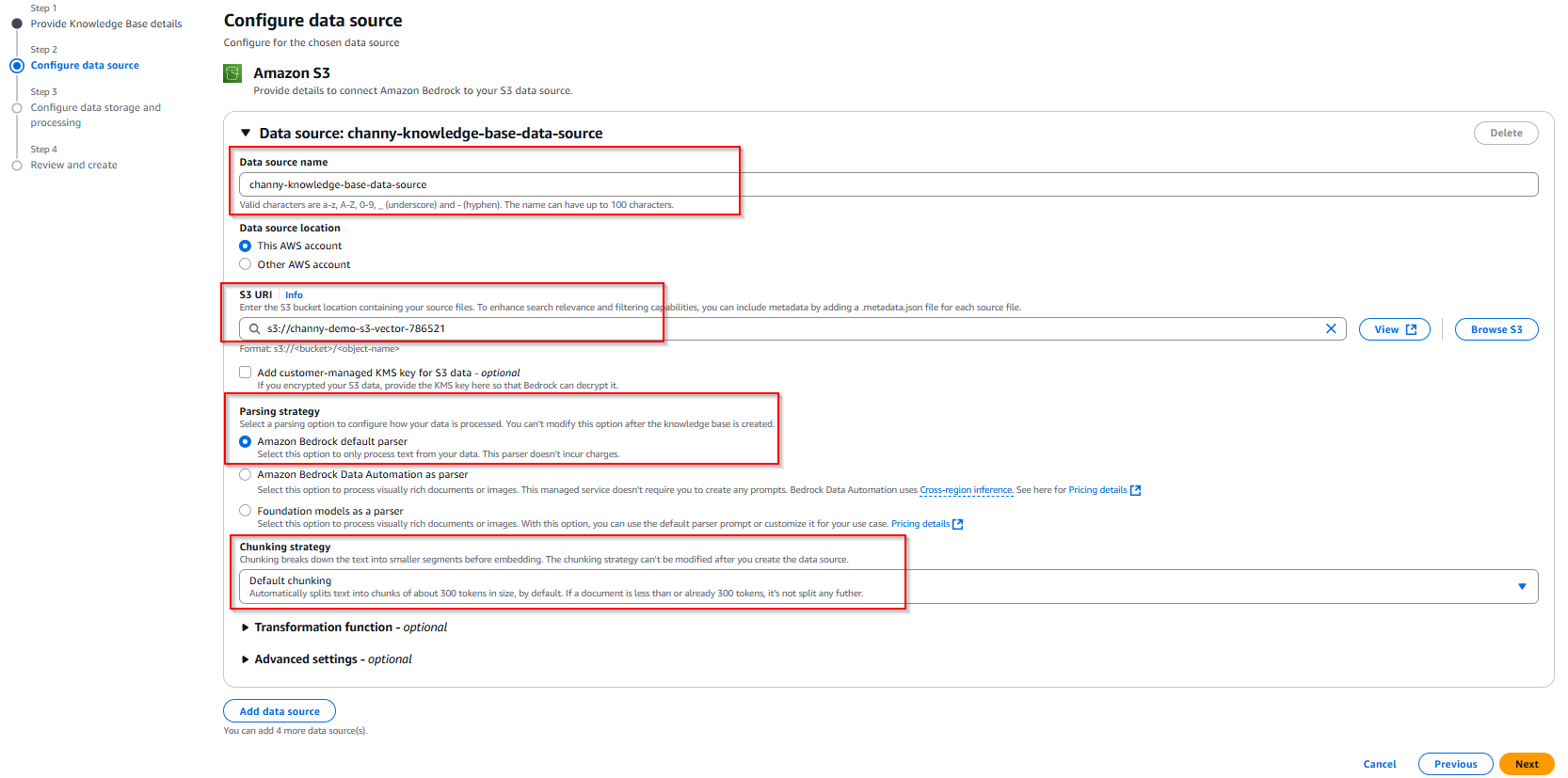
- Assign a descriptive name to your knowledge base data.
- In Data source location, select whether the S3 bucket exists in your current AWS account or another account, then specify the location where your documents are stored.
- Select Amazon Bedrock default parser for text-only documents at no additional cost. Select Amazon Bedrock Data Automation as parser or Foundation models as a parser for processing complex documents with visual elements.
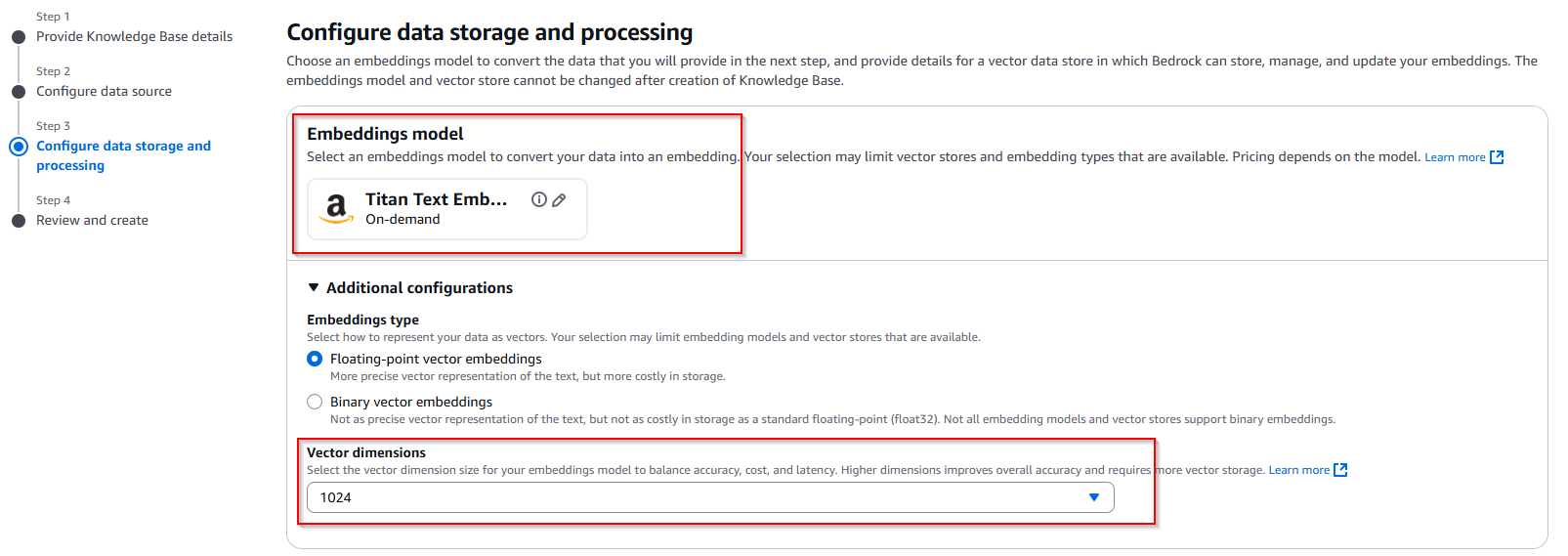
- To configure data storage and processing, first select the embeddings model. The embeddings model will transform your text chunks into numerical vector representations for semantic search capabilities.
- If connecting to an existing S3 Vector as a vector store, make sure the embedding model dimensions match those used when creating your vector store because dimensional mismatches will cause ingestion failures.
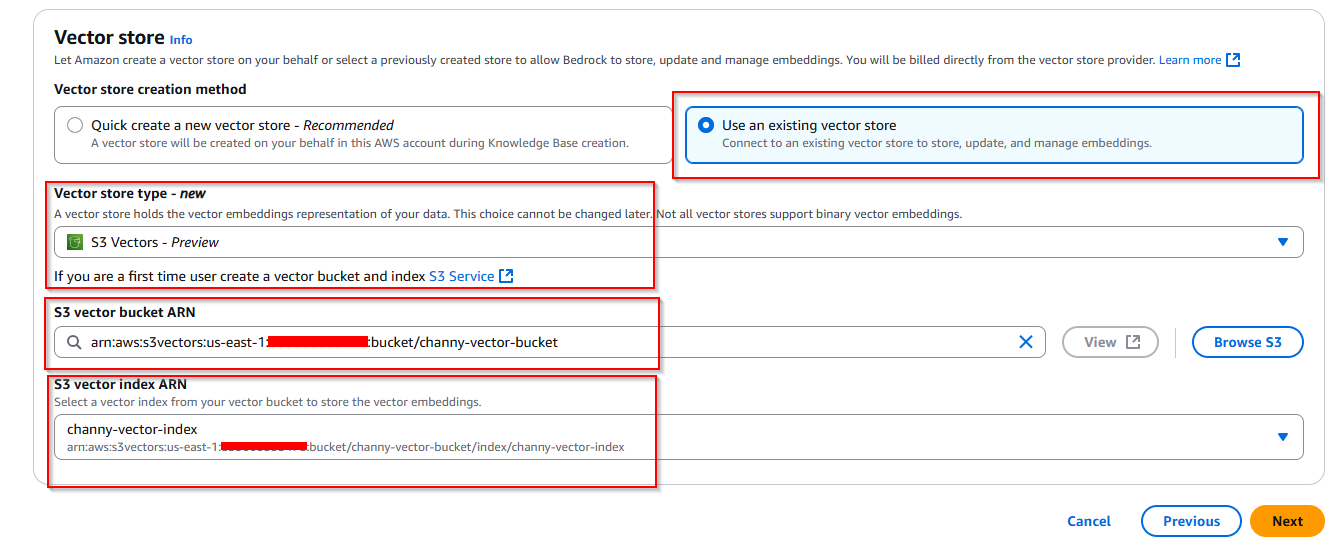
- After you have an S3 Vector bucket and index, you can connect it to your knowledge base. You’ll need to provide both the S3 Vector bucket Amazon Resource Name (ARN) and vector index ARN.
- Finally, preview and choose button Create Knowledge Base.
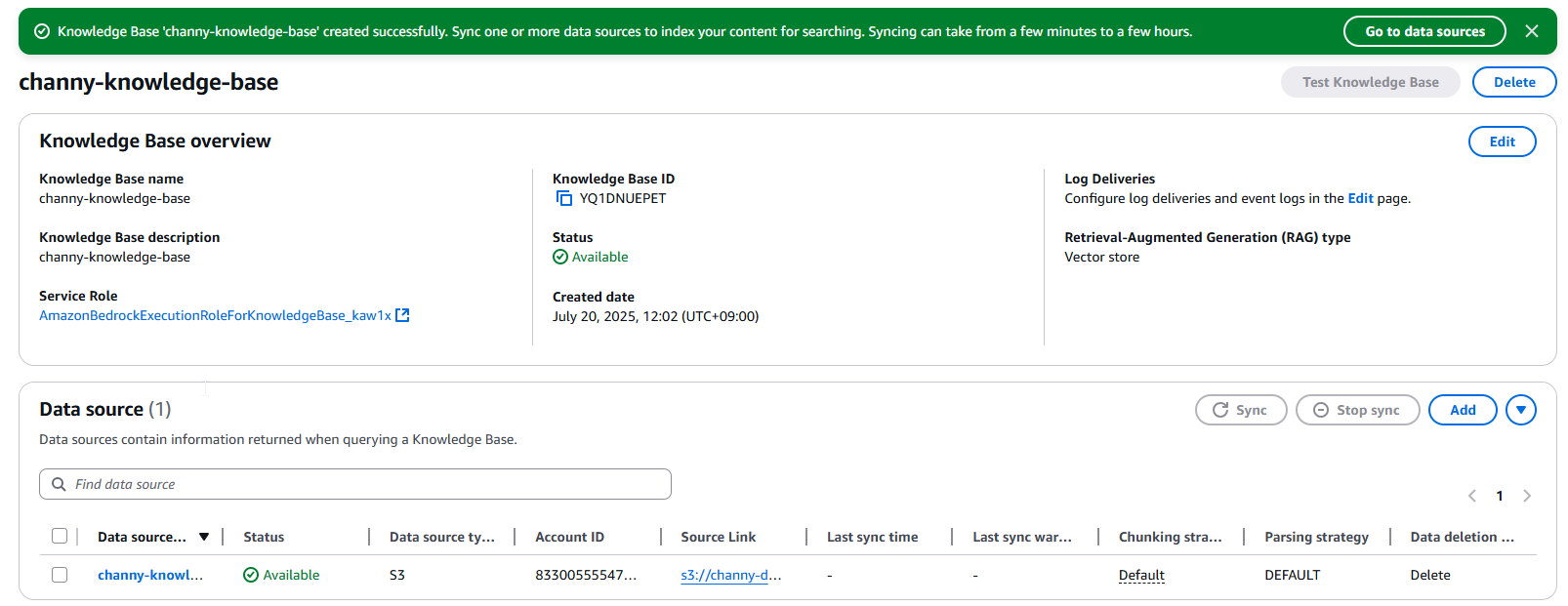
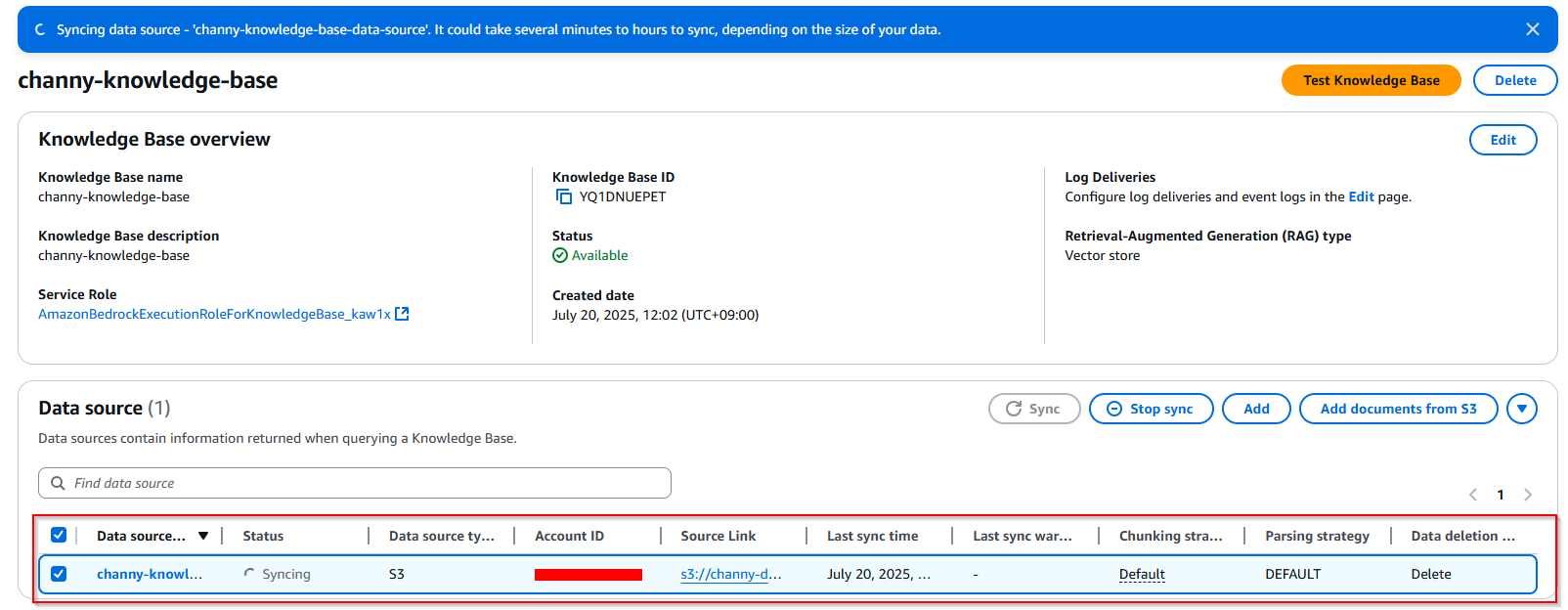
5. Sync the data source
After you’ve configured your knowledge base with S3 Vectors, you need to synchronize your data source to generate and store vector embeddings.
- From the Amazon Bedrock Knowledge Bases console, open your created knowledge base and locate your configured data source and choose Sync to initiate the process.
- During synchronization, the system processes your documents according to your parsing and chunking configurations, generates embeddings using your selected model, and stores them in your S3 vector index.
6. Test the knowledge base
After successfully configuring your knowledge base with S3 Vectors, you can validate its functionality using the built-in testing interface.
The testing interface provides valuable insights into how your knowledge base processes queries, displaying source chunks, their relevance scores, and associated metadata.
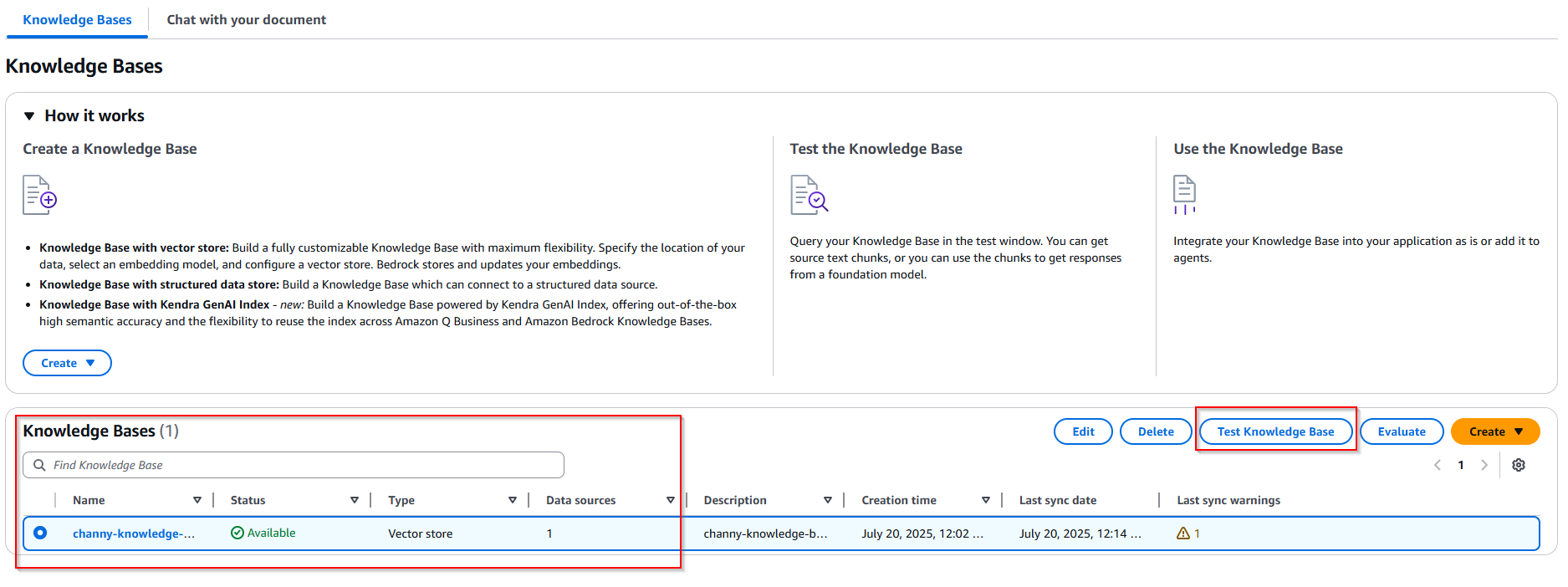
- Choose my Knowledge Bases -> Choose button Test Knowledge Base
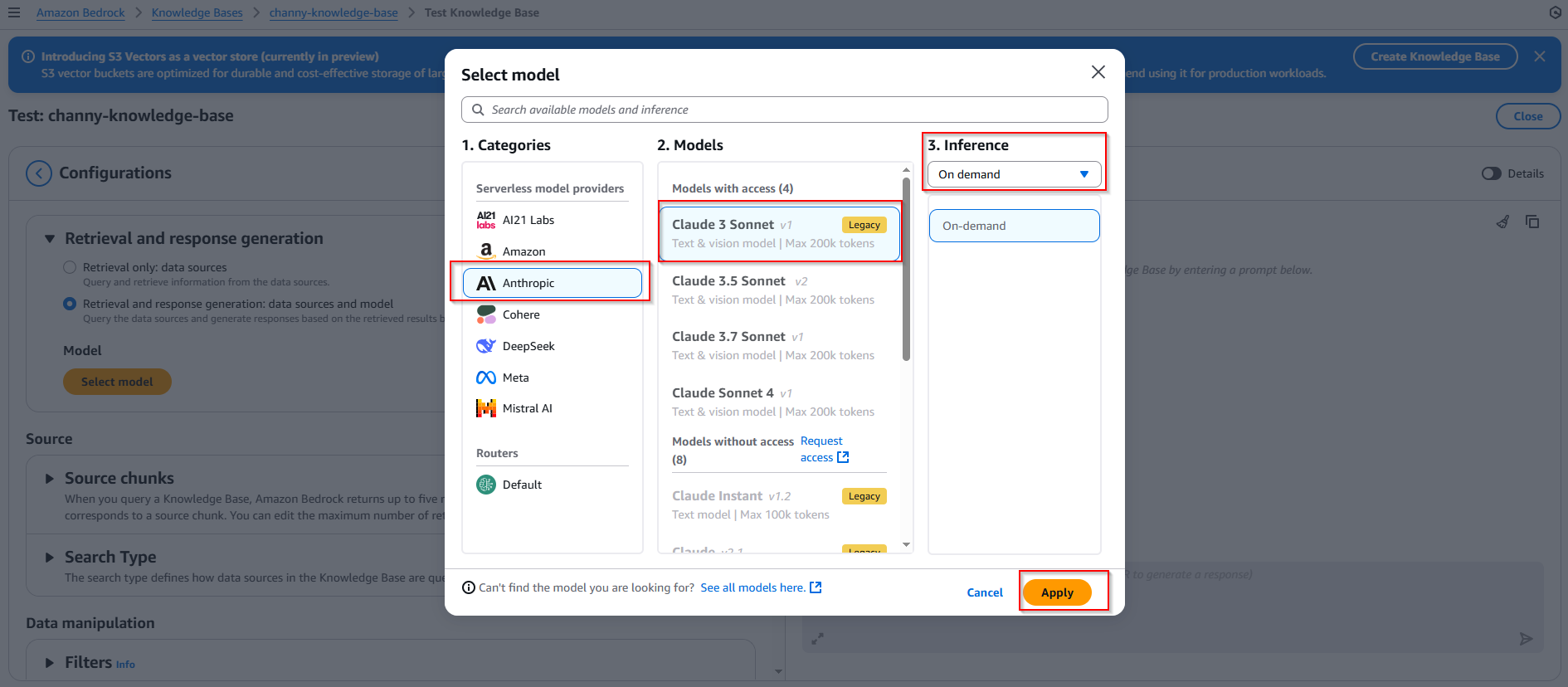
- In Retrieval and response generation, choose button Select model -> Categories model: Anthropic, Model: Claude 3 Sonnet, Inference: On-demand -> Choose button Apply.
- Enter my question for testing: Explain Amazon Bedrock Knowledge Base
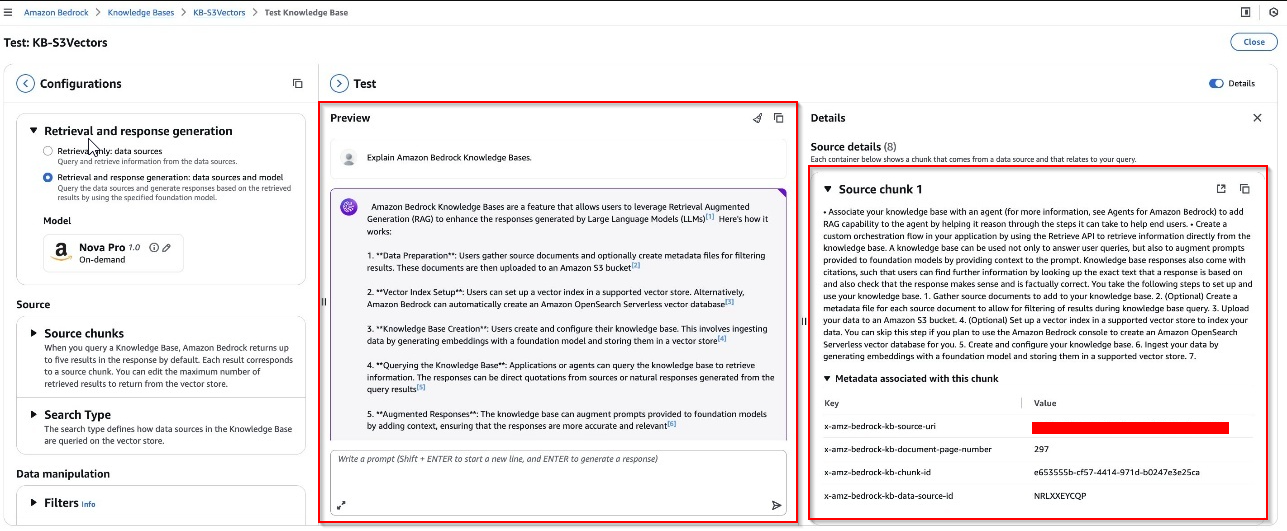
Optionally: You can also configure query settings for your knowledge base just as you would with other vector storage options, including filters for metadata-based selection, guardrails for appropriate responses, reranking capabilities, and query modification options...Using this hands-on validation, you can refine your configuration before integrating the knowledge base with production applications.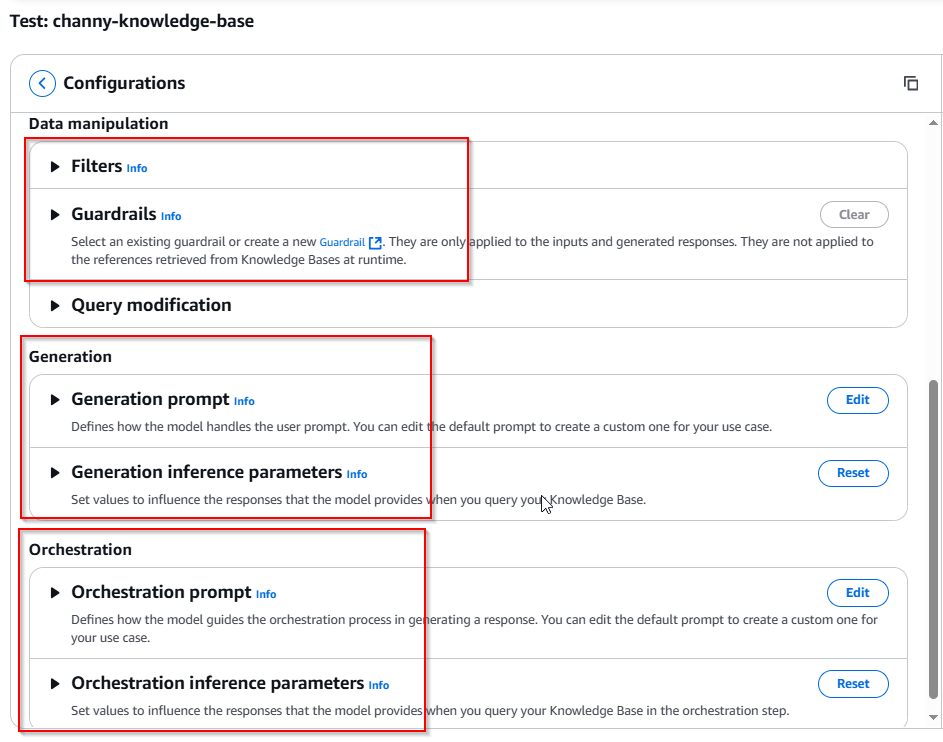
7. Export S3 vector data to Amazon OpenSearch Service
You can balance cost and performance by adopting a tiered strategy that stores long-term vector data cost-effectively in Amazon S3 while exporting high priority vectors to OpenSearch for real-time query performance.
This flexibility means your organizations can access OpenSearch’s high performance (high QPS, low latency) for critical, real-time applications, such as product recommendations or fraud detection, while keeping less time-sensitive data in S3 Vectors.
To export your vector index, choose Advanced search export, then choose Export to OpenSearch in the Amazon S3 console.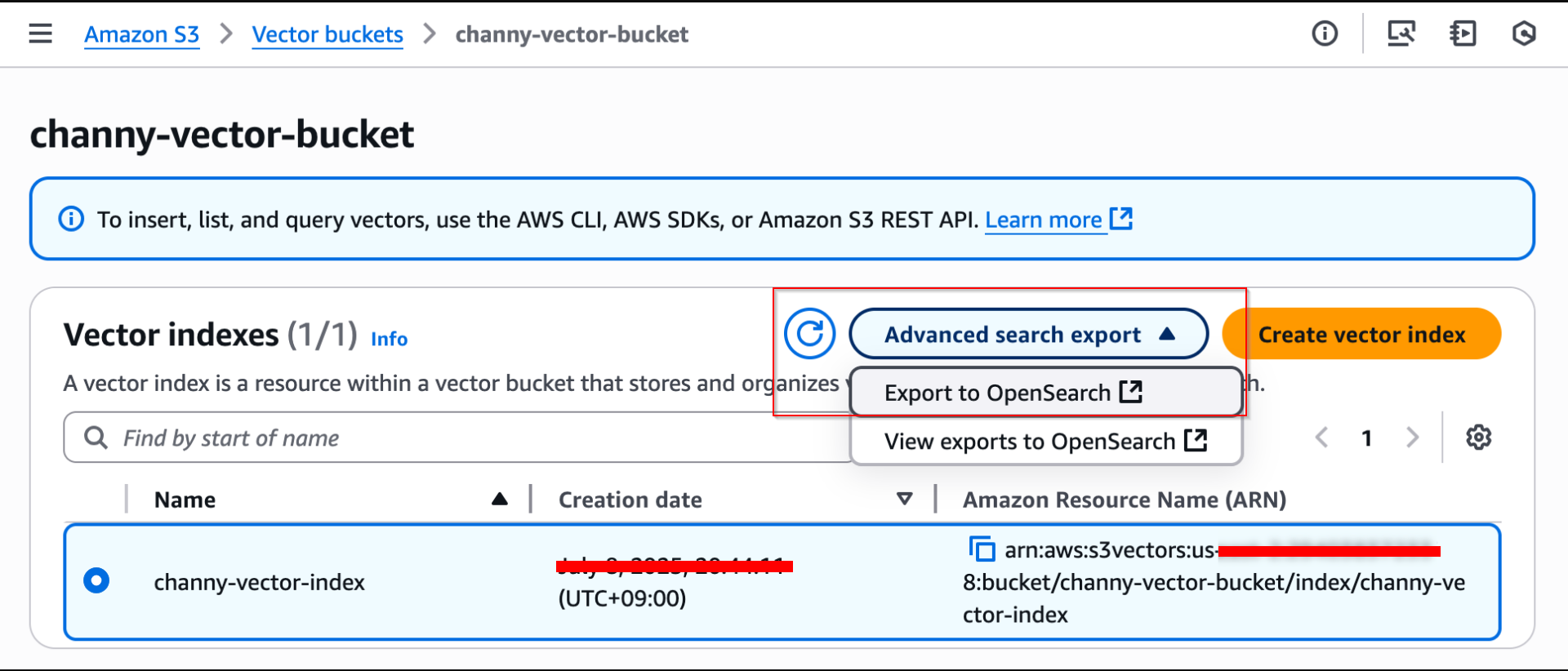
Then, you will be brought to the Amazon OpenSearch Service Integration console with a template for S3 vector index export to OpenSearch vector engine. Choose Export with pre-selected S3 vector source and a service access role.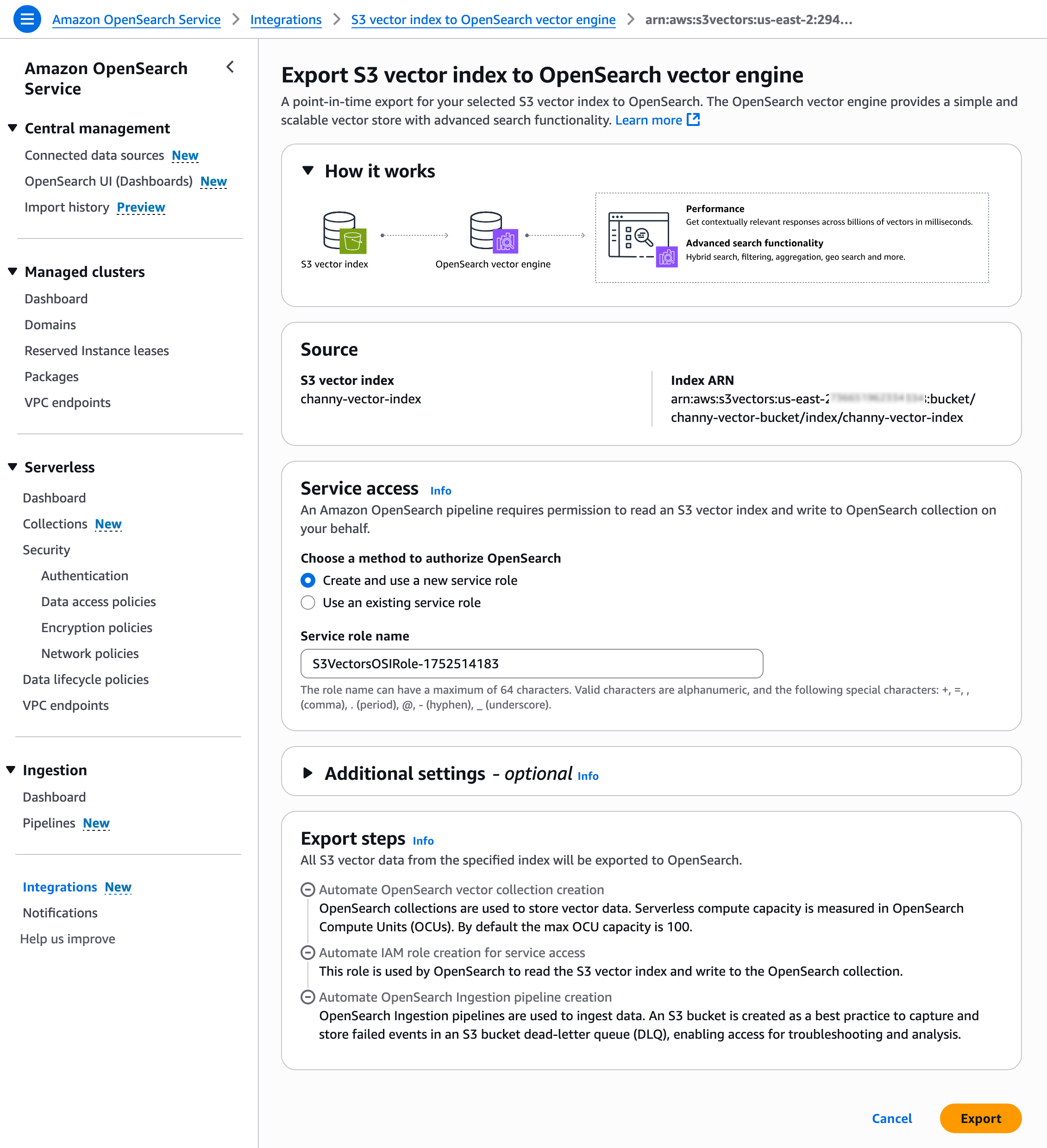
Choose the Import history in the left navigation pane. You can see the new import job that was created to make a copy of vector data from your S3 vector index into the OpenSearch Serverless collection.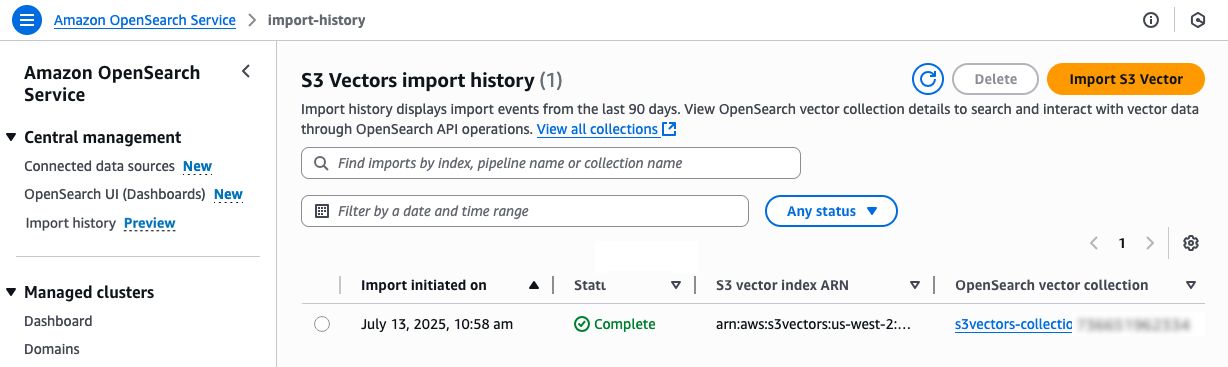
Once the status changes to Complete, you can connect to the new OpenSearch serverless collection and query your new OpenSearch knn index.
Clean up resources
- Delete resource Knowledge Bases
- Delete S3 Vector as a vector store using AWS CLI
aws s3vectors delete-index --vector-bucket-name YOUR_VECTOR_BUCKET_NAME --index-name YOUR_INDEX_NAME --region YOUR_REGION
aws s3vectors delete-vector-bucket --vector-bucket-name YOUR_VECTOR_BUCKET_NAME --region YOUR_REGION
- Delete S3 Bucket as you uploaded for this lab





